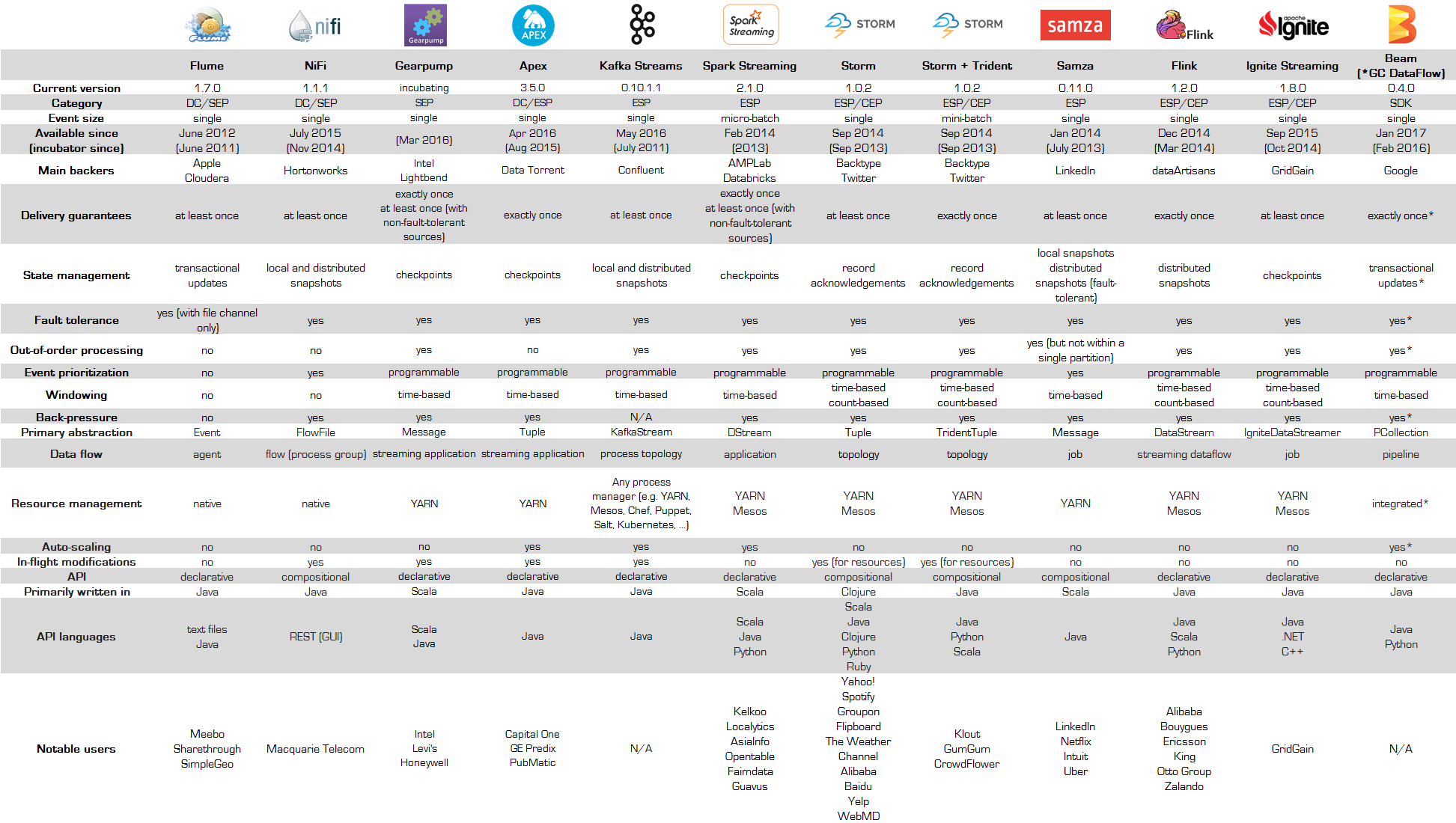
Apache Streaming technologies
Apcheで提供されているストリーム処理を実現する分散プラットフォームについてまとめた。

データ収集系
- Flume
- 分散データ収集の元祖的なプロダクト。Fluentdと近い内容。
- Hadoopエコシステムとして登場したが、最近は、あまり聞かない。
- Kafka Streams
- 元々、LinkedInが開発したメッセージングシステム。Pub-Sub型のメッセージングをサポートするが、キューとしての機能も持つ。
- 高速、かつ、耐障害性に強く、動的なスケールアウトも可能。
データフロー・ETL(Extract/Transform/Load)系
イベントデータに対して、リアルタイムに加工をするタイプ。
- Nifi
- 米国家安全保障局(NSA)がOSSとして公開。
- WebUIで、データフローを定義可能で、信頼性と性能のトレードオフ、動的な変更などが可能。
- 双方向のフローが可能。
ストリーム・プロセッシング系
- Storm
- Twitter社が公開したOSS。分散ストリーム処理プラットフォームの火付け役的な存在。
- 大規模な活用事例も多い。YahooやSpotifyの他、SalesforceのIoTプラットフォームであるThunderでも利用されえている。Hortonworks、Microsoft Azureなどでもプラットフォームとして利用できるようになっている。
- Singleイベントとして処理するSpout/Bolt構成の Storm Core と、Micro-batchとして動作する Storm Trident のタイプがある。
- Storm Core は At Least Once、Storm Trident は Exactly Once。
- Spark Streaming
- Sparkのリアルタイム処理エンジン。Hadoopが(バッチ処理の)Sparkと連携することが増えているため、Hadoopファミリとしての利用例が増えている。
- Micro-batchとして動作する。Exactly Once に対応しているとあるが、耐障害性を考慮すると At Least Once。
- Stormと比較されることが多かったが、最近では、競合となるのはFlinkだと思っている。
- Apex
- DataTorrent社が公開したOSS。
- YARNベースで、Hadoopと連携する。
- Exactly Once。
- Samza
- Kafkaと同様、LinkedInで開発された。そのため、Kafkaとの統合が容易。
- Flink
- 耐障害性に優れており、ダウンしても自動で復旧し、処理を継続することが可能。
- ストリーム処理だけでなく、バッチ処理をサポートしていたり、機械学習のライブラリも存在する。
- Exactly Once。
- Ignite
- インメモリ・データグリッドとしての特性をもつ。Sparkなどとも連携可能。
- Scanクエリ、SQLクエリ、テキストクエリなど、多彩なクエリに対応する。
- At Least Once。
- Gearpump
- 高スループット、低レイテンシを意識。
- StormやSamzaと互換性を持つ。
- At Least Once、Exactly Onceの両方に対応可。
- Beam
- Google Cloud Dataflow のモデルをOSS化したもの。ストリーム処理とバッチ処理の両モードに対応する。
- バックエンドとして、Flink、Spark、Google Cloud Dataflow を利用できる。Googleが、ストリーム処理エンジンの統合を狙ったものを考えられる。
- Auto-scalingに対応する。
- Exactly Once。
選択する時のポイント
- 性能と耐障害性
- ストリーム処理は、リアルタイムの処理となるため、性能が重要視されるのは間違いありません。ただ、それと同様に、耐障害性は重要となります。どのプロダクトも、耐障害性をうたっていますが、At Least Once(少なくとも1度は処理する)なのか、Exactly Once(必ず1度だけ処理する)といったメッセージの信頼性が異なったり、障害が発生したときのプログラミングモデルもプロダクトによって異なりますが、データ収集や保存の方式によって、どこで信頼性を担保するのかも変わってくるので、システム全体のアーキテクチャをふまえて、検討する必要があるでしょう。
- Single-Event vs Micro-Batch
- Stormのように、プログラミングモデルの違いにより、両方をサポートするケースもありますし、Spark Streamingのように、Micro-Batchに特化しているようなモノもあります。
- Single-Event方式では、1メッセージ毎の遅延は少なくなりますが、Micro-Batchでは、短い時間スパンでの集計処理などを行うことが可能になったりします。
- Streaming + Batch
- Spark/Spark Streamingにより、ストリーム処理とバッチ処理の両方に対応します。また、FlinkやBeamのように、ひとつのプロダクトで、両方をサポートするケースもあります。
- システム全体を考えた場合、ストリーム処理とバッチ処理の両方を利用するケースは多いため、そのような要件も踏まえて、選択するのもありでしょう。
- プログラミングモデル
- Stormなどは、低レベルのAPIで処理を実現しますが、Spark Streaming/Flinkでは、高レベルのAPIが提供されており、分散処理をあまり意識せずに、実装を行えます(その分、障害発生時の切り分けは難しくなる傾向もある)。
- 運用性
- 大量のデータをストリーム処理するとなると、ログを出力して動作を確認する、というわけにはいかなくなります(ログが大量に出力されることになる)。
- そのため、管理コンソール画面の存在は大きいです。スループットやエラー情報など、管理コンソール画面で確認できると、運用が楽になります。
- また、障害発生時に、他システムへ通知を行えるなどの機能も重要です。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

コメント
[…] Apache Streaming Technologies […]