
Introduction
Decision Systemを実現するには、
Signal(予測・スコア)とDecision(意思決定)を分離するだけでは不十分です。
Decision Trace Model が定義するように、
その間にある「意思決定の流れ」を、
実際に実行できる形で構造化する必要があります。
OSSとして公開している
Multi-Agent Orchestrator Core(GitHubリンク) は、
この「実行レイヤー」を担うエンジンです。
何ができるのか
この Orchestrator は、意思決定を以下の構造として実行できます。
1. 条件分岐(Condition / Decision)
単純な条件分岐の例としては、
if risk_score > 0.8:
reject
else:
approve
のような形があります。
しかし、実際の意思決定は単なる二択ではありません。
現場では、現在の状態、複数条件の組み合わせ、例外条件、そして判断後の処理分岐まで含めて設計する必要があります。
たとえば、
- リスクスコア
- 金額閾値
- 顧客属性
- 過去履歴
- 人間レビューの有無
などを総合的に評価し、
- 承認
- 却下
- 保留
- エスカレーション
- 追加確認
といった異なるアクションへ分岐させます。
複合的なDecisionの例
def decide_application(ctx): if ctx.risk_score > 0.9 and ctx.amount > 1_000_000: return "reject" if ctx.risk_score > 0.7: if ctx.customer_tier == "VIP": return "manual_review" return "hold" if ctx.missing_documents: return "request_additional_info" if ctx.past_fraud_flag: return "manual_review" if ctx.risk_score < 0.3 and ctx.customer_tier == "trusted": return "auto_approve" return "approve"
この例では、単なる1条件の分岐ではなく、
- 複数条件の組み合わせ(risk × amount)
- 状態依存の判断(VIPかどうか)
- 例外処理(過去不正履歴)
- 入力不備への対応
- 自動承認の条件
といった要素が組み合わさっています。
さらに重要なのは、このDecisionの結果によって、
- 人間レビューへ回す
- 追加情報を要求する
- 処理を保留する
といった後続の処理フローそのものが変わる点です。
このように Decision は、単なる if 文ではなく、
状態依存・複数条件評価・後続処理分岐を含む、明示的な判断ロジック
として定義されます。
Decisionをコードとして定義できるとは、
「モデル出力を受けて何をするか」を暗黙の運用に任せるのではなく、
判断基準そのものを実行可能な構造として外在化すること
を意味します。
2. 境界の明示(Boundary)
たとえば、モデルの確信度が十分でない場合には、自動で結論を出さず、人間による確認へ切り替えることができます。
if confidence < 0.7:
→ human_review
これは単なる条件分岐ではありません。
ここで表現されているのは、自動化の適用範囲そのもの です。
実際の業務では、AIが常に最後まで判断してよいわけではありません。
確信度が低い場合、入力が不完全な場合、例外度が高い場合、あるいは影響が大きい場合には、途中で処理を止め、人間へエスカレーションする必要があります。
Boundaryとして明確に設計できる とは、
AIの不確実性を「運用でなんとかする」のではなく、
どこで止めるか、どこで人に戻すかを実行可能なルールとして外在化する ことを意味します。
より実務に近い書き方にするなら、たとえばこうです。
if confidence < 0.7: route_to_human_review() elif amount > 1000000: require_manager_approval() elif input_missing_critical_field: request_additional_information() else: proceed_automatically()
- 確信度の低さ
- 業務インパクトの大きさ
- 入力不備
- 承認権限の必要性
といった複数の観点から、自動化の限界を制御しています。
重要なのは、BoundaryはDecisionの後ろに付く補助条件ではないという点です。
Decisionが「何をするか」を決めるのに対し、
Boundaryは「それを自動でやってよいのか」を決めます。
つまり Boundary は、
Decision System 全体における安全柵(Safety Guard)そのものです。
これを明示的に実装することで、
- どの条件で人に戻したのかが分かる
- 責任分界点が明確になる
- 過剰な自動化を防げる
- 安全性や監査性を高められる
- 改善時に境界条件だけを見直せる
ようになります。
3. 人間介入(Human Gate)
たとえば、一定の条件に達した場合には、処理を人間の判断に渡すことができます。
human_gate → approve / reject
これは単なる手作業への切り替えではありません。
ここで表現されているのは、人間の判断そのものを意思決定フローの一部として定義することです。
実際の業務では、すべてを自動化すべきではありません。
高リスク案件、例外案件、説明責任が重い案件、顧客影響の大きい案件などでは、人間が最終判断を担う必要があります。
重要なのは、その人間介入を暗黙の運用に任せるのではなく、
- どの条件で人に渡すのか
- 人は何を確認するのか
- 人が選べるアクションは何か
- その判断結果を次にどう反映するのか
を、明示的なフローとして設計することです。
このように Human Gate は、
AIの外側で人がなんとなく補う仕組みではなく、
判断構造の中に人間の責任と介入点を埋め込む仕組みです。
より実務に近い例を入れるなら、こう書けます。
if risk_score > 0.75 or exception_case: result = human_gate( reviewer="senior_analyst", options=["approve", "reject", "request_additional_info"] ) else: result = auto_approve()
システムの中で、
- 介入条件が定義され
- 担当者が定義され
- 選択可能なアクションが定義され
- その結果が後続処理に接続される
という形で、明確な役割を持っています。
つまり Human Gate は、
- 承認権限
- 例外対応
- 最終責任
- 補足情報の追加
- 自動処理の上書き
といった人間特有の判断機能を、構造の中に取り込む仕組みです。
ここで大事なのは、Boundaryとの違いも見えるようにすることです。
- Decision は、何をするかを決めるロジック
- Boundary は、どこまで自動で進めてよいかを決めるロジック
- Human Gate は、そこで人間がどのように介入するかを定義するロジック
です。
つまり、Boundary が「人に戻す」地点を決め、
Human Gate が「戻された人がどう判断するか」を構造化します。
4. 非同期実行(Action / WAITING / Resume)
意思決定フローの中には、その場で完了しない処理があります。
action → WAITING → resume
これは、アクション実行後に処理を一時停止し、
外部応答やイベントを待ってからフローを再開する構造を表しています。
たとえば、
- API呼び出し
- AIエージェント処理
- 外部ワークフローの完了待ち
- 人間承認待ち
- センサーや業務システムからのイベント待ち
などは、すぐに結果が返るとは限りません。
このような場合、処理を無理に同期的に書くのではなく、
WAITING という状態を明示的に持つことで、
- どこで止まっているのか
- 何を待っているのか
- どの条件で再開するのか
を構造として扱えるようになります。
より実務に近い形で書くなら、たとえばこうです。
result = call_external_risk_api(application) if result.status == "pending": set_state("WAITING") save_resume_point("after_risk_api") elif result.status == "completed": proceed_with(result.data) else: handle_error(result.error)
if current_state == "WAITING" and event.type == "risk_api_completed": resume(from_point="after_risk_api", data=event.data)
この例で重要なのは、処理の停止と再開が暗黙ではなく、
明示的な状態遷移として定義されていることです。
この仕組みが必要になるのは、単にAPIが遅いからではありません。
実際には、意思決定の中に次のような「待つべき対象」が存在します。
- 外部サービスの判定結果
- 複数AIエージェントの評価結果
- 人間による確認・承認
- バッチ処理やジョブキューの完了
- 他システムで発生する状態変化
つまり、現実のDecision Systemは、
即時処理の連続ではなく、待機・再開を含む時間的な構造を持っています。
このように、Action / WAITING / Resume を構造に組み込めるとは、
長時間処理や分散処理を、場当たり的な例外対応ではなく、意思決定フローの正式な一部として扱える
ことを意味します。
これによって、
- 長時間処理を安全に扱える
- 分散した外部処理と連携できる
- 途中停止した状態を追跡できる
- 再開地点を明示できる
- タイムアウトや再試行を組み込みやすくなる
- 非同期な人間介入やAI処理を統合できる
ようになります。
ここで大事なのは、これは単なる技術的な非同期処理の話ではない、という点です。
通常の非同期実装では、
- コールバック
- キュー
- Future / Promise
- ワーカー処理
といった仕組みが使われます。
しかし Decision System において重要なのは、
それらを単に内部実装として隠すことではなく、
「今この判断フローはどこで止まっていて、何を待っていて、何が起きたら再開するのか」
を判断構造として見える形にすることです。
つまり WAITING は技術的な待機ではなく、
判断フロー上の意味を持った状態です。
Decision / Boundary / Human Gate との関係も整理すると、こうなります。
- Decision は、何をするかを決める
- Boundary は、どこで止めるか・人に戻すかを決める
- Human Gate は、人がどう介入するかを決める
- WAITING / Resume は、止まった処理をいつどう再開するかを決める
この4つがそろうことで、意思決定は単なる分岐ではなく、
現実の時間と外部イベントを含んだ実行可能なシステムになります。
5. 状態管理(State Persistence)
意思決定フローが途中で停止する場合、その時点の状態を保持しておく必要があります。
WAITING → save → load → resume
これは、フローを一時停止したあと、必要な状態を保存し、
後からその状態を再読み込みして、処理を再開する構造を表しています。
実際の業務では、
- 外部APIの応答待ち
- 人間承認待ち
- 非同期ジョブの完了待ち
- 外部イベントの到着待ち
などにより、処理が途中で止まることがあります。
このとき、単に「待機中」というフラグだけを持つのでは不十分です。
必要なのは、
- 現在の実行位置
- 判定に使っていた入力データ
- 途中までの評価結果
- 次に再開すべきノードやステップ
- 待機理由や待機対象
を明示的に保持することです。
そうすることで、フローは単に中断されるのではなく、
将来再開可能な実行状態として保存されるようになります。
より実務に近い例を入れるなら、たとえばこうです。
if external_check.status == "pending": state = { "current_node": "fraud_check", "application_id": application.id, "risk_score": risk_score, "resume_point": "after_external_check", "waiting_for": "external_check_completed" } save_state(state) set_status("WAITING")
state = load_state(application.id) if state["waiting_for"] == "external_check_completed": resume(from_point=state["resume_point"], context=state)
この例で重要なのは、再開時に単に処理を呼び直しているのではなく、
中断時点の意味を持った状態を読み戻していることです。
このような状態管理が必要なのは、長時間処理に対応するためだけではありません。
本質的には、意思決定の途中経過を失わずに保持するためです。
たとえば保存すべきものには、次のようなものがあります。
- どの判断ステップまで進んだか
- どの条件がすでに評価されたか
- どのSignalが入力として使われたか
- どのBoundaryで停止したか
- どのHuman Gateに渡されたか
- 次に何が起きたら再開するか
こうした情報が保存されていれば、
中断後もフローを正しく継続できます。
逆に、状態保存がない場合、フローの再開は不安定になります。
- 再計算により結果が変わる
- 同じアクションを二重に実行してしまう
- 途中の人間判断を失う
- 監査時に「何が起きていたか」を説明できない
そのため、State Persistence は単なるキャッシュではなく、
意思決定の継続性を支える基盤になります。
このように、State Persistence を構造に組み込めるとは、
処理の途中停止を一時的な例外として扱うのではなく、保存・復元・再開可能な正式な状態として扱える
ことを意味します。
これによって、
- 中断後の再開が可能になる
- 長時間ワークフローを安全に扱える
- 分散処理や非同期処理と整合が取れる
- 二重実行や状態消失を防げる
- 途中経過を監査・再現しやすくなる
ようになります。
ここで大事なのは、これは単なるシステム実装上の便利機能ではないという点です。
Decision System において状態とは、
単なる変数の集合ではなく、
その時点までの判断過程そのものです。
つまり save / load / resume は、
- データの保存
- 実行位置の保存
- 判断文脈の保存
- 再開可能性の保証
を意味しています。
そのため、State Persistence は、
非同期実行を支える補助機能ではなく、
時間をまたぐ意思決定を成立させるためのコア機能だといえます。
整理すると、ここまでの役割は次のようになります。
- Decision は、何をするかを決める
- Boundary は、どこで止めるかを決める
- Human Gate は、人がどう介入するかを決める
- WAITING / Resume は、停止と再開の流れを定義する
- State Persistence は、その停止状態を失わず保持する
この5つがそろうことで、意思決定フローは
その場限りの処理ではなく、
中断・再開・監査に耐える実行可能なシステムになります。
6. 意思決定のトレース(Trace)
意思決定フローでは、処理の流れそのものをイベントとして記録できます。
node.started
node.waiting
boundary.triggered
human_gate.approved
これは、各ステップで何が起きたのかを、
判断の進行に沿って追跡可能にする仕組みです。
たとえば、ある申請処理においては、
- どのノードから開始したか
- どこでWAITING状態に入ったか
- どのBoundary条件が発動したか
- どのHuman Gateで承認されたか
を順番に残すことができます。
このように、Trace は単なるログ出力ではありません。
ここで記録されているのは、意思決定の経路そのものです。
より実務に近い書き方にするなら、たとえば次のようなイベント列になります。
trace = [ "application.received", "node.started:risk_check", "signal.generated:risk_score=0.82", "boundary.triggered:high_risk_case", "node.waiting:human_review", "human_gate.assigned:senior_reviewer", "human_gate.approved", "node.resumed:post_review", "action.executed:final_approval" ]
- どのSignalが生成されたか
- どのBoundaryで止まったか
- 人間にどう渡されたか
- どの時点で再開したか
- 最後にどのActionが実行されたか
までが一連の流れとして残っています。
これによって、単に「承認された」という結果だけではなく、
どのような経路を通って承認に至ったのか
を、あとから追跡できるようになります。
この仕組みが重要なのは、監査のためだけではありません。
Trace があることで、意思決定フローは
- 説明できる
- 検証できる
- 再現できる
- 改善できる
ようになります。
たとえば、ある判断が問題になったときでも、
- モデル出力がどうだったか
- どのDecisionが適用されたか
- どのBoundaryが発火したか
- 人がどこで介入したか
- どの状態で再開されたか
を順に見れば、
「なぜその結果になったのか」を構造的に説明できます。
逆に Trace がなければ、残るのは最終結果だけです。
- なぜ承認されたのか分からない
- なぜ人に回されたのか分からない
- どこで止まっていたのか分からない
- 誰が何を見て判断したのか分からない
という状態になり、
意思決定はブラックボックス化します。
つまり Trace は、
判断結果を記録するためのものではなく、判断過程を可視化するためのものです。
このように、意思決定のトレースを構造に組み込めるとは、
Decision、Boundary、Human Gate、WAITING、Resume といった各要素の動きを、後から追跡可能な形で記録できる
ことを意味します。
これによって、
- 判断の流れを説明できる
- 監査や検証がしやすくなる
- 問題発生時に原因を追える
- 再現実行や改善に活用できる
- AIと人間の役割分担を可視化できる
ようになります。
ここで大事なのは、Trace は単なる補助機能ではないという点です。
Decision System において、
判断が「正しかったか」だけでは不十分です。
必要なのは、
どのように判断されたか
を残すことです。
その意味で Trace は、
Decision System を単なる実行系ではなく、
説明可能で監査可能な意思決定基盤にするための中核機能です。
ここまでの流れをまとめるなら、こう整理できます。
- Decision は、何をするかを決める
- Boundary は、どこで止めるかを決める
- Human Gate は、人がどう介入するかを決める
- WAITING / Resume は、停止と再開を扱う
- State Persistence は、その状態を保持する
- Trace は、その全体の流れを記録する
つまり Trace は、
個々の判断要素をばらばらに残すのではなく、
それらをひとつの意思決定経路として接続して可視化する役割を持っています。
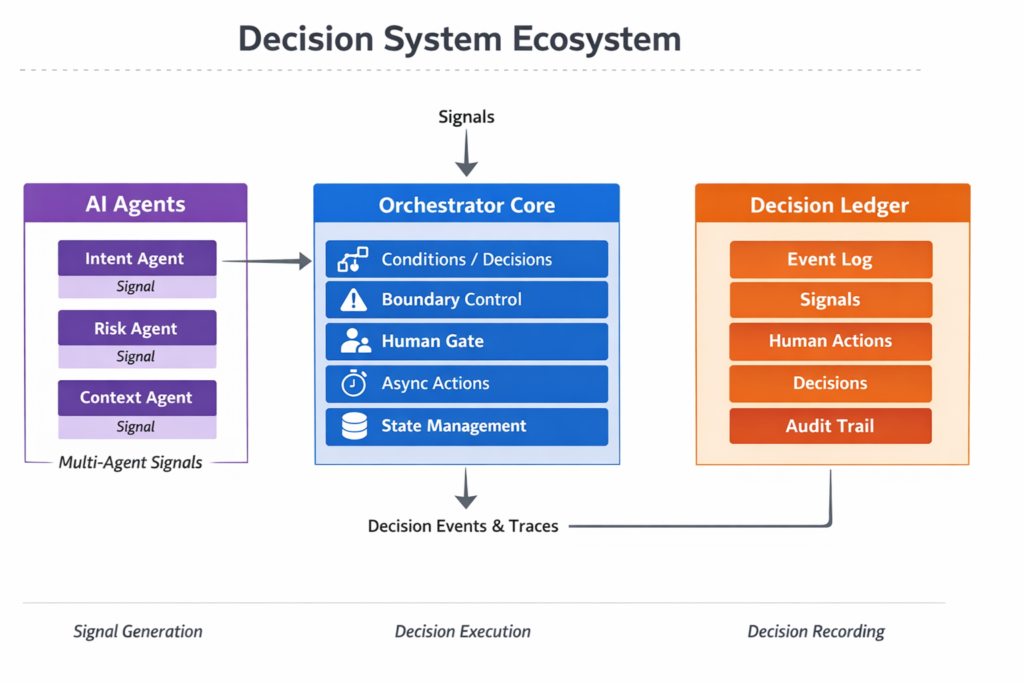
Multi-Agent Orchestrator Core
ここまで見てきたように、意思決定システムを実装するためには、
- Decision(判断ロジック)
- Boundary(停止条件)
- Human Gate(人間介入)
- WAITING / Resume(非同期実行)
- State Persistence(状態管理)
- Trace(意思決定の記録)
といった複数の要素を統合的に扱う必要があります。
これらは個別に実装することも可能ですが、
実際にはそれぞれが密接に連携するため、
一貫した構造として扱わなければ、運用はすぐに破綻します。
Multi-Agent Orchestrator Core は、これらの機能をすべて統合した実行基盤です。
このコアは、
- 意思決定ロジック(Decision)を実行し
- 条件に応じて停止(Boundary)し
- 人間へ引き渡し(Human Gate)
- 外部イベントや処理完了を待ち(WAITING)
- 状態を保持し(State Persistence)
- 後からすべての判断経路を追跡できる(Trace)
という一連の流れを、ひとつの実行モデルとして提供します。
重要なのは、これらが単なる機能の寄せ集めではないという点です。
それぞれが独立しているのではなく、
- Decisionが判断を定義し
- Boundaryが自動化の限界を定義し
- Human Gateが責任の所在を定義し
- WAITINGが時間的な分断を扱い
- Stateが継続性を保証し
- Traceが全体を可視化する
という形で、ひとつの意思決定構造として結合されています。
その結果、Multi-Agent Orchestrator Core は、
- AIと人間の協働を前提としたフローを構築できる
- 長時間・分散処理を安全に扱える
- 判断過程をすべて記録・再現できる
- 条件・ルール・責任を明示的に設計できる
という、従来のシステムでは実現が難しかった
「実行可能な意思決定基盤」を提供します。
Multi-Agentとの関係
この Orchestrator は、単体で完結するものではありません。
最初から、複数の AI Agent と連携して動作することを前提に設計されています。
重要なのは、ここでの Agent の役割が、従来の AI システムとは異なるという点です。
従来のAIでは、しばしば
モデル = 判断主体
のように扱われてきました。
つまり、モデルがスコアや予測や推薦を出し、その出力をそのまま「判断結果」とみなしてしまう構造です。
しかし、この構造には本質的な問題があります。
モデルが出しているのは、あくまで予測・評価・生成結果であって、
それ自体が意思決定ではないからです。
この Orchestrator を中心とした構造では、
Agent は「答えを出す存在」ではありません。
Agent の役割は、
- 意図を解釈する
- リスクを評価する
- 文脈を補完する
- 候補案を生成する
- 状況を別視点から評価する
といった形で、異なる観点から Signal を生成することにあります。
つまり、この構造では
Agent = Signal生成 + 視点
です。
Agent はそれぞれ独立した判断者なのではなく、
意思決定のための材料を、複数の観点から生成する役割を担います。
たとえば、次のような構成を考えることができます。
Event → Intent Agent(意図理解) → Risk Agent(リスク評価) → Context Agent(文脈補完) → Signal(複数)
それぞれ異なる観点から異なる Signal を返します。
- Intent Agent は「何を求めているのか」を解釈する
- Risk Agent は「何が危険か」を評価する
- Context Agent は「不足している背景文脈は何か」を補う
その結果として得られるのは、ひとつの答えではなく、
複数の Signal と複数の視点です。
ここが非常に重要です。
Multi-Agent の価値は、
複数の Agent がそれぞれ「最終結論」を出すことではありません。
そうではなく、
- 異なる観点を導入できる
- 単一モデルでは見落とす要素を拾える
- 意図・リスク・文脈・候補生成を分離できる
- 判断の材料を多面的に生成できる
ことにあります。
そして、その複数の Signal を
最終的な意思決定へ変換する役割を持つのが Orchestrator です。
Orchestrator は、各 Agent から集まった Signal をそのまま出力しません。
それらを受け取り、条件・ルール・境界・人間介入の構造に接続して、
実際のアクションへ変換します。
流れとしては、たとえば次のようになります。
Signal(複数) → Condition / Decision → Boundary → Human Gate
- 複数の Signal を受け取り
- 条件に基づいて評価し
- 必要に応じて停止し
- 人間へ引き渡し
- 最終的なフローを実行する
ことで、Signal を意思決定へ変換します。
ここでのポイントは非常に明確です。
Agent は「答えを出す存在」ではない。
Orchestrator が「意思決定を実行する」。
この役割分担によって、
Multi-Agent システムは単なる「複数モデルの寄せ集め」ではなく、
判断構造を持ったシステムになります。
もう少し丁寧に言えば、各 Agent は
- 部分的な解釈
- 専門的な評価
- 観点ごとの候補生成
を行う存在です。
一方で Orchestrator は、それらを統合して
- どの Signal を採用するか
- どの条件で分岐するか
- どこで止めるか
- どこで人に戻すか
- どのアクションを実行するか
を決めます。
つまり、
- Agent は「材料を出す」
- Orchestrator は「構造化して決める」
という関係です。
この分離には大きな意味があります。
もし Agent 自身がそのまま判断主体になってしまうと、
- なぜその結論になったのか分かりにくい
- 複数 Agent の不一致を扱いにくい
- 停止条件や人間介入を設計しにくい
- 責任分界が曖昧になる
という問題が起こります。
しかし Orchestrator が意思決定を担う構造にすると、
- Agent の役割を明確に分離できる
- Signal と Decision を切り分けられる
- Boundary や Human Gate を入れられる
- 全体の判断フローを Trace できる
ようになります。
つまり、Multi-Agent を本当に使える形にするためには、
Agent を増やすだけでは足りません。
それらを意思決定構造に変換する中核が必要であり、
それが Orchestrator です。
Ledgerとの関係
この Orchestrator は、単に意思決定フローを実行して終わるものではありません。
むしろ重要なのは、実行されたすべての意思決定が Ledger に記録されることです。
つまり、この構造では
実行と記録は切り離されたものではなく、最初から一体のものとして扱われます。
意思決定システムにおいて本当に重要なのは、
「何が実行されたか」だけではありません。
必要なのは、
- どの Event から始まったのか
- どの Agent がどの Signal を出したのか
- どの Decision が適用されたのか
- どの Boundary が発動したのか
- どこで Human Gate に渡されたのか
- 誰が何を承認・却下したのか
といった、判断の流れそのものを残すことです。
この Orchestrator は、そうした一連の過程を
Ledger に保存する前提で設計されています。
たとえば記録対象になるのは、次のような要素です。
- Event
判断の起点となる入力や事実 - Signal
各 Agent が生成した評価、解釈、候補、スコア - Decision
Signal をもとに実際に選択された判断 - Boundary
停止、保留、エスカレーション、追加確認などの境界条件 - Human Operation
人間による承認、却下、差し戻し、補足判断
これらはバラバラのログとして散在するのではなく、
ひとつの trace として連続的に保存されます。
つまり Ledger には、単なる結果だけではなく、
「どのような流れでその結果に至ったのか」
が保存されます。
ここでの Ledger の役割は、普通のログ保存とは少し違います。
Ledger は単なる監視ログやデバッグログではありません。
その役割は、意思決定の履歴そのものを構造化して保持することにあります。
Ledger は典型的には、次のような性質を持ちます。
- append-only
過去の記録を書き換えず、出来事を追記していく - 改ざん困難
後から都合よく履歴を変えにくい - 再現可能
過去の判断経路をあとから追跡し、必要に応じて再生できる
この3つは、意思決定を扱う上で非常に重要です。
まず append-only であることの意味は、
判断履歴を「都度上書きされる状態」ではなく、
時間に沿って積み重なる出来事の列として保持できることにあります。
これによって、
- 最初に何が起きたか
- 途中で何が追加されたか
- どこで判断が変わったか
- 誰が介入したか
を時系列で追うことができます。
もし履歴が上書きされるだけなら、
最終結果しか残らず、過程は消えてしまいます。
しかし Ledger では、過程そのものが保存対象になります。
次に、改ざん困難であることの意味は、
後から結果に合わせて履歴を書き換えにくいという点にあります。
これは単にセキュリティの話ではありません。
本質的には、判断の責任を支えるための性質です。
たとえば問題が起きたとき、
- 本当にその Signal が出ていたのか
- 本当にその Boundary が発動したのか
- 本当に人間が承認したのか
を確認できなければ、
記録としての意味がありません。
Ledger は、こうした履歴を
「あとから都合よく整えるためのメモ」ではなく、
実際に何が起きたかを残す基盤として扱います。
そして再現可能であることの意味は、
過去の意思決定を単なる記録として眺めるだけでなく、
その流れを検証し、理解し、改善に活かせることにあります。
たとえば Ledger があれば、
- なぜその判断に至ったのかを追跡できる
- どこで停止したのかを確認できる
- どの Agent 出力が採用されたかを見られる
- 人間介入がどのように影響したかを分析できる
ようになります。
つまり Ledger は、監査のためだけの保管庫ではありません。
意思決定を再現可能な知識として蓄積する装置でもあります。
このように考えると、Ledger の役割はかなり明確です。
Orchestrator が意思決定を実行し、
Ledger がその意思決定の履歴を保持する。
この2つが組み合わさることで、
システムは単なる処理実行系ではなく、
追跡可能で改善可能な意思決定基盤になります。
もし Orchestrator だけで Ledger がなければ、
- 何が起きたか後から分からない
- 判断理由を説明できない
- 人間介入の履歴が残らない
- 改善のための材料が蓄積されない
という問題が起こります。
逆に Ledger があることで、
実行された判断は一回限りで消えるものではなく、
将来の検証・改善・再利用のための資産になります。
ここで言う「資産化」とは、
単にログをたくさん保存することではありません。
重要なのは、個々の意思決定が
- 説明可能で
- 比較可能で
- 再利用可能で
- 改善可能な
形で残ることです。
たとえば、過去の trace を見れば、
- どの条件設定が妥当だったか
- どの Boundary が厳しすぎたか
- どの Human Gate で差し戻しが多いか
- どの Agent の Signal が有効だったか
を分析できます。
これは単なる監査ログではなく、
組織の意思決定そのものが蓄積されていく状態です。
つまり Ledger とは、
意思決定の履歴を保存するだけでなく、
意思決定の経験を組織資産へ変換する基盤なのです。
全体構造
これらを統合すると、Decision System は以下の3層構造になります。

- Agent:Signalを生成する
- Orchestrator:意思決定を実行する
- Ledger:意思決定を記録する
Agent は、意図理解、リスク評価、文脈補完など、
異なる観点から判断材料となる Signal を生成します。
Orchestrator は、それらの Signal を受け取り、
Condition / Decision、Boundary、Human Gate、WAITING / Resume などを通じて、
実際の意思決定フローを実行します。
Ledger は、その過程全体を trace として保存し、
意思決定を追跡可能で再現可能な履歴として保持します。
この3層が分離されることで、
意思決定は単なるモデル出力ではなく、
構造・実行・記録を備えたシステムとして扱えるようになります。
同時に、このアーキテクチャは最初からフル構成で実装する必要はありません。
より軽量なアプローチから始めることも可能です。
例えば、シンプルなケースでは以下の最小構成でも十分に機能します:
Event → Signal → Decision → Human → Log
このような Light 構成でも、
・LLMやルールによるSignal生成
・ルールベースの意思決定
・人へのエスカレーション
・意思決定の記録
といった基本的な意思決定フローをカバーできます。
その上で、必要に応じてマルチエージェントによる評価や、
より高度なオーケストレーションへと段階的に拡張することが可能です。
つまり、構造は一貫したまま、実装は段階的に進化させることができます。

Light構成の詳細は軽量DTMで実現する「判断できるAI」の最小構成も参照のこと。
何が変わるのか
この構造を導入すると、AIの使い方は大きく変わります。
従来のAIシステムでは、モデルがスコアや予測を出し、
最終判断は人間が行い、
その過程はコードや運用の中に埋もれていました。
そのため、
- AIは何を出したのか
- 人はなぜそう判断したのか
- どこで止めるべきだったのか
- どの条件で例外処理になったのか
といったことが、あとから見えにくくなっていました。
結果として、判断は属人的になり、
ログも断片的で、
同じ状況が再び起きても、同じ判断を再現することが難しくなります。
一方、Decision System として構造化すると、状況は変わります。
- 判断フローそのものが明示的に設計される
- Agent の役割が分離される
- Boundary が明示される
- 人間の介入点が定義される
- その全過程が trace として記録される
つまり、意思決定はその場限りの対応ではなく、
構造を持ち、実行でき、記録できるシステムとして扱われるようになります。
言い換えれば、
意思決定が「システム」になるのです。
この変化によって、従来は難しかったことが可能になります。
1. 判断の再現
従来のシステムでは、最終結果だけが残り、
なぜその結論に至ったのかは、人の記憶や断片的なログに頼ることが多くありました。
しかし、Decision System では、
- どの Event から始まったのか
- どの Agent がどの Signal を出したのか
- どの Condition / Decision が適用されたのか
- どの Boundary が発動したのか
- どこで Human Gate が使われたのか
を trace として追うことができます。
そのため、単に「承認された」「却下された」ではなく、
なぜそうなったのかを後から再現できるようになります。
これは、トラブル時の原因分析だけでなく、
良い判断を学習し、再利用するためにも重要です。
2. 判断の標準化
多くの現場では、同じような案件でも
担当者によって判断が微妙に変わります。
その背景には、
- 判断基準が明文化されていない
- 例外対応が口頭知や経験に依存している
- 人によって重視する観点が異なる
といった問題があります。
Decision System では、Condition、Boundary、Human Gate などが
構造として明示されるため、
判断基準を共有しやすくなります。
もちろん人間の裁量を完全になくすわけではありません。
しかし少なくとも、
- 何を見て判断するのか
- どこで止めるのか
- どこで人に渡すのか
が明確になることで、
属人性を減らし、判断のばらつきを抑えることができます。
つまり、判断は個人の勘だけに依存するものではなく、
組織として扱える標準的な構造になります。
3. AIと人間の分業
従来のAI導入では、
「どこまでAIに任せてよいのか」が曖昧なまま進みがちです。
その結果、
- 任せすぎて危険になる
- 逆に結局すべて人が見てしまう
- 誰が責任を持つのか分からない
といった問題が起こります。
Decision System では、Boundary と Human Gate を通じて、
- どこまで自動で進めるか
- どこで必ず止めるか
- どの条件で人に戻すか
- 人は何を選べるか
を明示的に定義できます。
これにより、AIは Signal を生成し、
Orchestrator が判断フローを制御し、
必要なところで人間が責任ある介入を行う、という
明確な役割分担が可能になります。
つまり、AI と人間は競合するのではなく、
境界の明確な分業関係として設計できるようになります。
4. 分散意思決定
単一のモデルだけで複雑な判断を行おうとすると、
意図理解、リスク評価、文脈補完、候補生成など、
異なる役割が一つに混ざってしまいます。
その結果、
- モデルの役割が不明確になる
- どの観点が効いたのか分からない
- 部分的な改善がしにくい
という問題が起こります。
Multi-Agent 構造では、各 Agent が異なる観点から Signal を生成し、
Orchestrator がそれらを統合して意思決定を実行します。
これにより、
- 意図理解は Intent Agent
- リスク評価は Risk Agent
- 文脈補完は Context Agent
といったように、役割を分離したまま連携できます。
つまり、意思決定は単一の巨大なブラックボックスではなく、
複数の視点を持つ分散構造として設計できるようになります。
そして、その分散した判断材料を
最終的に一つの意思決定フローとして統合できる点が、
Orchestrator の大きな価値です。
5. 監査可能性
従来のシステムでは、問題が起きたときに
「結果」は見えても、
「判断過程」は見えないことが少なくありません。
しかし、意思決定を業務で使う以上、
本当に必要なのは最終結果だけではなく、
- どんな入力があり
- どんな評価が行われ
- どんなルールが適用され
- どこで人が関与し
- なぜその結論になったのか
を説明できることです。
Decision System では、これらが Ledger に trace として残るため、
あとから判断経路を追うことができます。
その結果、
- 監査に耐えられる
- 説明責任を果たせる
- 問題発生時に原因を特定しやすい
- 改善のための分析ができる
ようになります。
つまり、判断はブラックボックスな処理ではなく、
説明可能で検証可能な行為になります。
ユースケース
この構造は抽象的なアーキテクチャではありません。
実際の業務に当てはめると、Decision System がどのように動くのかは、かなり具体的に見えてきます。
たとえば、次のようなユースケースが考えられます。
1. 不正検知
金融取引や決済処理では、単にスコアを出すだけでは不十分です。
重要なのは、その取引を承認するのか、保留するのか、あるいは人間レビューに回すのかを、明確な構造で決めることです。
流れとしては、たとえば次のようになります。
transaction → Risk Agent → Boundary → Human Gate → Decision → Ledger
しかし、その Signal 自体が最終判断ではありません。
Orchestrator は、その結果を受けて、
- リスクが低ければ自動承認する
- 一定以上なら保留する
- 高リスクまたは例外的なケースなら人間レビューへ回す
といった判断フローを実行します。
このとき Boundary は、自動処理をどこで止めるかを決めます。
Human Gate は、必要に応じて担当者や審査者の承認・却下をフローに組み込みます。
そして最終的な判断結果だけでなく、
- どの取引が入力だったか
- Risk Agent がどのような Signal を出したか
- どの Boundary が発動したか
- 誰が承認または却下したか
が Ledger に trace として記録されます。
つまり不正検知において重要なのは、
「怪しいかどうかを予測すること」だけではなく、
その予測を、責任ある判断フローに変換することです。
2. カスタマーサポート
カスタマーサポートでも、単に自動応答を返すだけでは十分ではありません。
問い合わせには、よくある定型的なものもあれば、複雑で人間対応が必要なものもあります。
そのため、重要なのは
「何に答えるか」だけでなく、
その問い合わせを自動で処理してよいのか、それとも人へ渡すべきかを判断することです。
流れとしては、たとえば次のようになります。
問い合わせ → Intent Agent → Complexity判定 → 自動応答 or 人対応
たとえば、
- 配送状況の確認
- 返品依頼
- 契約変更
- クレーム
- 障害報告
といった種類を識別し、必要な Signal を生成します。
さらに、複雑性やリスクを評価することで、
- FAQで十分対応可能か
- 追加確認が必要か
- オペレーター対応に回すべきか
- 上位担当者へエスカレーションすべきか
を判断できます。
ここで大事なのは、自動応答と人対応の切り替えが、曖昧な運用ではなく、Boundary と Human Gate を含むフローとして明示的に定義されることです。
たとえば、
- 簡単な問い合わせは自動応答
- 感情的なクレームや高難度案件は人へエスカレーション
- 契約や返金など責任の重い対応は必ず人間承認
といった構造が可能になります。
その結果、カスタマーサポートは単なるチャットボットではなく、
意図理解と対応判断を備えた意思決定システムになります。
3. 製造業
製造業では、異常検知そのものよりも、
異常をどう判断し、どの作業指示につなげるかが重要です。
たとえば設備監視や検査工程では、センサー、画像認識、過去履歴、稼働条件など、複数の情報源が存在します。
そのため、単一のモデル出力だけで決めるのではなく、複数の Agent が異なる視点から Signal を生成する構造が有効です。
流れとしては、たとえば次のようになります。
異常検知 → Signal(複数Agent) → 判断 → 作業指示
- 画像検査 Agent が外観異常を検出する
- センサー解析 Agent が振動や温度の異常を検出する
- 履歴 Agent が過去の故障パターンとの類似を評価する
- 文脈 Agent が現在の工程条件や稼働状況を補完する
といった形で、複数の Signal を生成できます。
Orchestrator は、それらを統合して、
- 継続運転
- 注意喚起
- 一時停止
- 点検依頼
- 保全担当へのエスカレーション
といった判断へ変換します。
さらに重要なのは、その判断がそのまま現場の作業指示につながることです。
つまり、異常検知は単独の分析機能ではなく、
現場のアクションを引き起こす意思決定フローの一部になります。
そしてその過程が Ledger に残れば、
- なぜ停止判断になったのか
- どの Signal が強く効いたのか
- どの条件で作業指示が発行されたのか
をあとから追跡できるようになります。
これは、製造現場における改善、標準化、技能継承にも非常に大きな意味を持ちます。
4. リテール
リテールの現場では、需要予測そのものより、
予測をどう業務判断につなげるかが重要です。
たとえば、需要予測モデルが「来週この商品が伸びる」と出したとしても、
それだけでは発注や値引きや販促を自動で決められるわけではありません。
必要なのは、
- 在庫制約
- キャンペーン方針
- 利益率
- 地域特性
- 店舗裁量
- 本部ポリシー
といった要素を含めて、実際の施策を決めることです。
流れとしては、たとえば次のようになります。
需要予測 → Policy判断 → 人間承認 → 実行
しかし、どの施策を実行するかは、Orchestrator 側の Policy 判断に委ねられます。
たとえば、
- 需要上昇が見込まれるなら追加発注候補を出す
- 需要減少が予測されるなら値引き候補を出す
- 粗利条件や在庫制約に反する場合は自動実行しない
- 一定以上の価格変更や在庫移動は人間承認を必須にする
といったルールが考えられます。
このとき Human Gate を入れることで、
価格変更、キャンペーン適用、店舗間移動など、影響の大きい施策についてはマネージャーや本部担当者が確認してから実行できます。
つまりリテールでは、需要予測モデルは「答え」を出すのではなく、
意思決定の材料を出す存在になります。
その材料をもとに Policy と Human Gate を通じて施策へ落とし込むことで、
はじめて業務として使える構造になります。
この4つのユースケースに共通しているのは、
AIが直接すべてを決めているのではないという点です。
どのケースでも、
- Agent が Signal を生成し
- Orchestrator が判断フローを実行し
- Ledger がその過程を記録する
という構造が働いています。
つまり、このアーキテクチャの価値は、
特定業務のための個別ロジックにあるのではなく、
異なる業務領域に共通して適用できる意思決定の実行構造にあるのです。
結論
AIは「答え」を出すことはできる。
しかし、
意思決定を実行し、記録することはできない。
必要なのは、
- Agent(Signal生成)
- Orchestrator(意思決定の実行)
- Ledger(意思決定の記録)
からなる
Decision System です。
Decision Trace Modelが「構造」を定義し、
Orchestratorがそれを「実行」し、
Ledgerがそれを「記録」する。
この3つが揃ってはじめて、
意思決定はシステムになります。
Multi-Agent Orchestrator Coreはこちら(GitHubリンク)


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

