統計的因果推論と因果探索
概要
機械学習を活用する際に「因果関係」と「相関関係」の違いを考える事は重要になる。
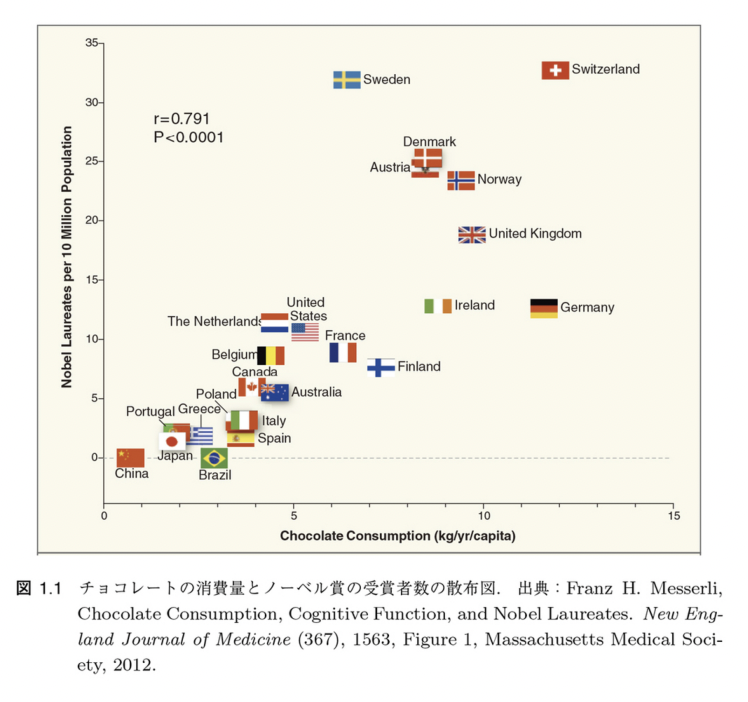
例えば、以下のようなチョコレートの消費量とノーベル賞の受賞者数のデータがある。

このデータを見ると、チョコレートの消費量とノーベル賞の受賞者数には明らかに相関があるように見え、ノーベル賞を取るにはチョコーレートを食べれば良いという結論も導けてしまう。
実際には、スイスには有名な国際研究機関が多々ありそこから多数のノーベル賞受賞者が出ているのであり、チョコレートの本場で一人当たりの消費量が多いという事実とはほぼ関係がない。元のデータについての考察がないままに機械学習を行い結果だけを見てしまうと、このようにたまたまそうなっている結果を「因果関係」や「相関関係」としてしまうことがある。
そのような間違いを犯さないため、一般的な自然科学系の実験では前提条件(実験条件)を明確に定義して固定した上で、原因として予測する条件を変化させた時の結果を見て因果関係を判定する。自然科学の世界ではこのように比較的容易に前提条件を固定することが比較的容易となる。
それに対して、人文系の実験(例えば前述のチョコレートとノーベル賞のような社会科学系やなんらかのトリガーを与えた時人のリアクションのような心理学のケース)では、結果に影響を与える要因を規定することが困難なため、考えられうる条件をランダムに変化させた上で、原因のパラメータを変化させる手法がよく使われる。他の条件をランダムにすることで効果の連鎖を断ち切るイメージとなる。
このような「相関関係」ではない「因果関係」に対して検討する技術が「因果推論」や「因果探索」となる。因果推論と因果探索は、両方とも因果関係を分析する方法だが、「因果推論」は因果関係を検証するための手法であるのに対して、「因果探索」は因果関係を発見するための手法となり、目的とそのアプローチに違いがある。
因果推論は、実験データや観察データから因果関係を特定するための形式的な手法となる。これは例えば、2つのグループに分けて実験を行い、2つのグループの間に統計的な差異があることを確認することで、特定の介入が因果効果を引き起こしていることを推論するものとなる。因果推論の主なアプローチとしては(1)介入変数をランダムに割り当てて実験を行う「ランダム化実験」、(2)自然界で起こる現象を介入変数とみなす「自然実験」、(3)統計的な処理で介入を受けたグループと介入を受けていないグループの間の混同を解消する「傾向スコアマッチング」、(4)観察データから統計的に因果効果を推定する「線形回帰モデル」などがある。
一方、因果探索は、潜在的な因果関係を発見するための手法であり、結果を予測する可能性がある変数を識別するためにデータを探索するものとなる。具体的なアルゴリズムとしては(1)2つの変数間の相関を計算し、相関係数を算出する「相関分析」、(2)変数間の因果関係を表す有向グラフを作成しグラフの構造から因果関係を推定する「因果グラフ理論」、(3)変数間の因果関係を表す構造方程式モデルを構築し、モデルに基づいてデータを解釈する「構造方程式モデル」、(4)適切な回帰モデルを選択することで、因果関係を推定する「回帰分析」などがある。因果探索はその他にも様々な機械学習アルゴリズムが適用されている。
これら因果推論の参考図書としては「因果論実世界のデータから因果を読む-岩波データサイエンス3」「統計的因果探索 (機械学習プロフェッショナルシリーズ)」「つくりながら学ぶ! Pythonによる因果分析 ~因果推論・因果探索の実践入門」「因果推論の科学 「なぜ?」の問いにどう答えるか」「哲学がわかる因果性」「時間の正体 デジャブ・因果論・量子論」等様々なものがある。






これらの図書は哲学的概念から、統計学的なアプローチ、様々な理論と具体的な実装まで幅広い範囲の情報が記載されている。本ブログではそれらからピックアップした様々なトピックについて以下に述べている。
実装
因果推論と強いAIの実現に向けた考察
因果推論と強いAIの実現に向けた考察。強いAI(または汎用人工知能、AGI: Artificial General Intelligence)は、特定の問題領域に限定されない広範な知能を持つAIを指す。AGIは、人間のように知識を学び、理解し、さまざまな環境や状況で柔軟に対応できるAIを目指しており、単なるパターン認識や最適化を超え、「知的推論」や「意図的な行動選択」ができる能力が必要とされている。強いAIが人間と同等の知的能力を持つためには、因果推論の能力が不可欠であると言われている。
因果推論と因果探索技術の概要と実装
因果推論と因果探索技術の概要と実装。因果推論(Causal inference)は、ある出来事や現象が別の出来事や現象を引き起こす要因であるかどうかを推論するための方法論となる。因果探索(Causal exploration)は、因果関係を特定するためにデータを分析し、潜在的な因果関係の候補を探索するプロセスとなる。
ここではこの因果推論と因果探索に関して、様々な適用事例と時差総例について述べている。
Causal Forestの概要と適用事例とRとPythonによる実装例について
Causal Forestの概要と適用事例とRとPythonによる実装例について。Causal Forestは、観測されたデータから因果効果を推定するための機械学習モデルであり、ランダムフォレストをベースにしており、因果推論に必要な条件に基づいて拡張されたものとなる。ここでは、このCausal Forestの概要と適用事例およびRとPythonによる実装について述べている。
Doubly Robust Learners(二重ロバスト学習器)の概要と適用事例およびpythonによる実装例
Doubly Robust Learners(二重ロバスト学習器)の概要と適用事例およびpythonによる実装例。Doubly Robust Learnersは、因果推論の文脈で使用される統計的手法の一つであり、観測データから因果効果を推定する際に、二つの推定手法を組み合わせることでよりロバストな結果を得ることを目指すものとなる。ここではこのDoubly Robust Learnersに関する概要とアルゴリズム、適用事例と Pythonによる実装について述べている。
Meta-Learnersを用いた因果推論の概要とアルゴリズム及び実装例
Meta-Learnersを用いた因果推論の概要とアルゴリズム及び実装例。Meta-Learnersを用いた因果推論は、機械学習モデルを用いて因果関係を特定し、推論するためのアプローチを改善する方法の一つであり、因果推論は、ある変数が別の変数に対して直接的な因果関係を持つかどうかを判断することを目指すが、これには従来の統計的方法だけでなく、機械学習を活用することでより高度な推論が可能となる。Meta-Learnersは、異なる因果推論タスクに対して迅速に適応する能力を持つモデルを構築するために使用され、これにより、以下のような問題を効率的に解決できるようになる。
グラフニューラルネットワーク用いた反実仮想学習の概要と関連アルゴリズム及び実装例
グラフニューラルネットワーク用いた反実仮想学習の概要と関連アルゴリズム及び実装例。グラフニューラルネットワーク(GNN)を用いた反実仮想学習(counterfactual learning)は、グラフ構造を持つデータに対して「もし〜だったら」という仮定のもとで、異なる条件下での結果を推論する手法となる。反実仮想学習は因果推論と密接に関連しており、特定の介入や変更が結果に与える影響を理解することを目的としている。
GAN(Generative Adversarial Network)を用いた因果探索
GAN(Generative Adversarial Network)を用いた因果探索。GAN (Generative Adversarial Network) を用いた因果探索は、生成モデルと識別モデルの対立する訓練プロセスを活用し、因果関係を発見する方法となる。以下に、GANを用いた因果探索の基本的な概念と手法を示す。
Structural Agnostic Model(構造的無差別モデル)の概要とアルゴリズム及び実装例
Structural Agnostic Model(構造的無差別モデル)の概要とアルゴリズム及び実装例。SAMは、因果推論の文脈で使用される手法の一つであり、この手法は、データから因果関係を推定する際に、特定の仮定や事前知識に依存せずにモデルを構築することを目指すものとなる。従来の因果推論手法では、特定の因果構造や仮定に基づいたモデルが使用されることが一般的だが、これらの仮定が現実のデータに対して正確であるかどうかは明確ではない場合があった。また、因果関係の推定においては、仮定によってバイアスが生じる可能性もあった。SAMは、このような仮定や事前知識に依存せずに因果関係を推定する手法であり、具体的には、データから因果効果を推定するためのモデルを構築する際に、因果関係の仮定や制約を最小限に抑えることを重視するものとなる。
因果の概念(哲学的アプローチ)
comming soon
因果推論を中心とした話題
岩波データサイエンスシリーズvol.3「因果論-実世界のデータから因果を読む」読書メモ
岩波データサイエンスシリーズvol.3「因果論-実世界のデータから因果を読む」読書メモ。実世界のデータから因果を読む観察データ,とくに再現不可能な現実データからいかに因果関係を読みとるか.データの欠失・バイアス・制約条件などのため解析は困難だが,それだけに現場からの強い期待がある.サイエンティストに必須でかつ市民の教養としても基本となる「因果の方向」「交絡」「介入」に関する入門解説から,すぐに役立つ解析手法までを紹介する.
因果推論イントロダクション(1)交絡因子とランダム化実験
因果推論イントロダクション(1)交絡因子とランダム化実験。因果関係に対しては、データサイエンスにおける因果推論(統計的因果推論)としてさまざまな方法論が検討されている。まず相関関係と因果関係の定義ついて述べる。
相関関係は、2つの変数の間に、一方の変数の値が大きい時に他方の変数の値も大きい(または小さい)といった直線的な関係がある場合に、この2変数は相関関係がある、もしくは相関しているという。
因果関係は、要因Xを変化させたときに要因Yも変化する場合にXとYの間に因果関係があるという。そして要因Xを原因、要因Yをその結果と呼ぶ。ここからは、原因を示す変数を原因変数、結果を示す変数を結果変数(アウトカム)と呼ぶ。また、要因を操作して変化させることを、介入(intervention)、処置(treatment)などという。介入というのは、治療をおこなうことだったり、広告を見せることだったりを想像すれば良い。
交絡因子の影響を調整して因果関係を検討する方法は様々あるが、その中でも因果関係を検証するための最適な方法は実験研究となる。因果推論の分野でいう実験研究とは、介入を実施するか、しないかを無作為に割り付けるもので、ランダム化比較試験(randomized controlled trial ,RCT)と呼ばれる。これに対して割り付けを無作為としない研究は観察研究と呼ばれる。
因果推論イントロダクション(2)層別解析と回帰モデルによる分析
因果推論イントロダクション(2)層別解析と回帰モデルによる分析。現実の問題では、何が交絡因子であるかが予め全てわかっていることはまずあり得ない。常に未知の交絡因子があると考えた方が良い。さらに、交絡因子であることがわかっていても、常にそれが測定されているとは限らないし、技術的、費用的などの様々な理由により測定が可能とも鍵来な。つまり測定されなかった交絡因子もあると考えた方が良い。
実験研究(RCT)では無作為割り付けを行うことで、上記に述べたような測定されなかった交絡因子や未知の交絡因子を含めたあらゆる交絡因子に悩まされることなく因果推論ができる。これは、観察研究による因果推論にはないRCTの大きなアドバンテージとなる。一方、観察研究による因果推論では一般に交絡因子が測定されていることが要求される。後述する手法の中には条件を満たせば、測定されていないもしくは未知の交絡因子への対応ができる可能性のある方法もあるが、層別解析と回帰モデルによる分析という2つの最も基本的な手法では交絡因子が測定されていることを前提とする。
相関と因果と関係構造(1)相関関係(回帰係数)と因果関係(介入効果)のズレ
相関と因果と関係構造(1)相関関係(回帰係数)と因果関係(介入効果)のズレ。「相関関係」と「因果関係」は異なり、ある要因Xともう一つの要因Yの間に高い相関が見られたからといって、その間に因果的な関係があるとは限らないこととなる。一方でそのような高い相関関係を因果関係として解釈できる場合もある。今回は、「ぱっと見の相関関係に囚われると因果関係を見誤る」4つの典型的な事例を取り上げ、それらの因果構造と構造方程式より、回帰係数と介入効果の値のズレについて述べる。
相関と因果と関係構造(2)バックドア基準
相関と因果と関係構造(2)バックドア基準。今回は「バックドア基準」について述べる。バックドア基準はフォーマルな記述をすると、以下のような2つの条件で示される。
因果ダイアグラムGにおいて、XからYへと有向道があるとする。このとき、次の2つの条件を満たす。頂点集合Sは、(X,Y)についてバックドア基準を満たすという(1)XからSの任意の要素に有向道がない、(2)因果ダイアグラムGよりXから出る矢線を除いたグラフにおいて、SがXとYを有向分離する。
またカジュアルな定義では以下のようになる。丸と矢印で描かれた因果構造において、Xから下流側に矢印を辿った時にYにつながる経路があったとする。X→Yの介入効果の推定において、以下の2つの条件を満たす「モデルに追加した説明変数の組」は、バックドア基準を満たすという。(1)追加した説明変数はXの下流側にない、ゅふょXから出る矢印を除いた時の因果構造において、追加した「説明変数の組」により、(XとYの)上流側の共通要因からXとYの両方に影響を与える流れがすべて遮断されている。
バックドア基準は広い一般性を持つものであり、統計的因果推論の分野全体を統一的に理解する上で重要なものとなる。
準実験のデザイン- 観測データからいかに因果関係を導き出すか
準実験のデザイン- 観測データからいかに因果関係を導き出すか。データが先にあって、そこから次にリサーチクエッションが出てくるという、実世界では多いシナリオに対して、どのように因果関係を検証するのかについて述べる。
観察データから因果関係を導き出す方法の中でも、比較的ロバストである研究手法を準実験(Quassi-experiment)と呼ぶ。ランダム化比較試験のような実験では因果関係を証明できるが、観察データではしばしば因果関係を示すことはできない。しかし、その観察データでも実験に似た状況を作り出すことで、因果関係を示す手法が準実験となる。準実験デザインの具体的な例としては以下のようなものがある。(1)操作変数法(IV design: Instrumental variable design)、(2)回帰分断デザイン(RDD; Regression discontinuity design)、(3)中断時系列デザイン(ITS; Interupted time-series analysis)、(4)差の差分析(DID; Difference-in-deferrences analysis 差の差分法とも言う)、(5)傾向スコア・マッチング(PS; Propensity score matching)
統計的因果効果の基礎(1)ルービン効果モデルに基づく因果効果の定義
統計的因果効果の基礎(1)ルービン効果モデルに基づく因果効果の定義。今回は統計的因果効果としてもっとも広く用いられているルービン効果モデルに基づく因果効果の定義と活用について述べる。
ある行動や選択が結果にどのように影響を与えるかを考える際には「もし実際と違って〜していた場合の結果」と現状を比べる反実仮想の考え方は極めて自然なものとなる。統計学では標準的な因果効果推定の枠組みとなっているルービン効果モデルは、この反実仮想をただの想像ではなくデータから行う統計学の枠組みとなっている。
ここで、ハーバード大学のルービン教授が1970年に提案したルービン因果モデルを説明するための記号について述べる。まず説明の簡便のために”もし〜”として考える条件は2つだけとする。また変数Zを2値変数(Z=1,0)の介入有無のインディケータ変数(またはどちらの群に属するかを表す変数)とする。Yを結果変数(アウトカム)の値とするが、反実仮想の考え方を利用するので、Yは本来2変数あると考える。具体的にはY0を”もしその人がZ=0という条件を受けた場合の結果変数”そしてY1を”もしその人がZ=1という条件を受けた場合の結果変数”とする。
統計的因果効果の基礎(2)回帰モデルを用いた手法とマッチングと層別解析を用いた手法
統計的因果効果の基礎(2)回帰モデルを用いた手法とマッチングと層別解析を用いた手法。因果推定を行う際にはランダムな実験を行うことで潜在的結果変数を考慮せずに行うことができるが、現実的な実験ではRCTそのものが難しかったり、RCTでは推定できなかった理するケースが多々ある。そのような場合には、潜在的結果変数をすべて観測することができないので、ATEを推定するには何か追加的な仮定が必要となる。それらに対しては一般的には「強い意味での無視可能性(strong ignorability)」と呼ばれる仮定をおく。
こう仮定が成立する場合に回帰モデルを用いた手法とマッチングと層別解析を用いた手法を用いて因果効果を推定することができる。
統計的因果効果の基礎(3)操作変数法とまとめ
統計的因果効果の基礎(3)操作変数法とまとめ。操作変数法は計量経済学では非常に古くから使われている手法となるが、いくつかの条件のもとで因果効果の推定にも利用することが可能となること、さらに後述する局所的処置効果の回帰分析デザインとの関係から、近年「傾向スコア解析などの共変量調整では不可能な、隠れた共変量(交絡要因)が存在するば場合でもバイアスのない推定が可能な方法である」として因果効果推定の代表的な方法の一つとなる。ここでは操作変数法で因果効果を推定するとはどういうことか?について述べる。
また「相関と因果は異なる」とはよく言われることだが、背後のメカニズムそのものと、我々がそれをどこまで峻別できるかは別の問題であり、限られたデータと過去の知見から我々が行えるのはせいぜい「因果関係である可能性が高いかどうか」の程度の判断となる。
因果効果推定の応用 – CM接触の因果効果と調整効果
因果効果推定の応用 – CM接触の因果効果と調整効果。今回は、因果効果の推定の実例としてCM接触(視聴)のアプリ使用状況に対する因果効果の推定例について述べる。具体的には「テレビCMの接触有無」と「スマートフォンのアプリ利用」が同一対象者から得られているシングルソースパネルデータを利用する。ここで述べる方法はCM以外のマーケティング施策でも有効だし、マーケティング以外の分野でもよそんや資源制約が存在する状況で、最も効率の高い施策を実施する際に有用だと思われる。
前述で、因果効果として平均処置効果ATEや処置群での平均処置効果ATTについて述べた。ATEは対象母集団の「(すべての人がCMを見た場合のアプリ利用時間の平均)-(すべての人がCMを見なかった場合のアプリ利用時間の平均)」。ATTはCM視聴者に対して「(CMを見た)現状の利用時間の平均)-(彼らにCMを見せなかった場合の利用時間の平均)」を表す。
傾向スコアを用いたバント効果の推定
傾向スコアを用いたバント効果の推定。今回は、傾向スコアによる共変量調整の理論を、野球でのバント作戦の効果推定に応用するケースについて述べる。ノーアウト1塁のバントは「1塁にいる走者をアウトカウント1つと引き換えに、2塁(得点圏=ヒットを打てばホームベースに帰れる)ランナーを送る」ことを意図して行われる。つまり、得点をもぎ取りたいというときに用いられる作戦となる。しかし、バント作戦が本当に得点する確率を上昇させるのかについては、野球経験者の間でも意見が分かれる。そこで、今回は大リーグの2006年から2014年までのノーアウト1塁のデータを用いて、バント作戦が有効であるかどうか(=得点する確率を上昇させるか?)について述べる。
差の差分で検証する「保育所整備」の効果
差の差分で検証する「保育所整備」の効果。社会科学における因果推論の一つの特徴は非実験データの利用にある。近年、フィールド実験や実験室実験も取りいられる様になってきて注目を集めているが、費用や倫理的な問題から実験を行えないことが多く、大部分の社会科学の研究では非実験的なデータを分析する。実験を行えない、というのは因果推論を行う上で大きな足枷となる。しかし、こうした制約の下で因果推論をおこなうための手法の開発が経済学の一分野である計量経済学の中で進められてきた。ここでは、その中でもとりわけよく使われる手法の一つである「差の差分」を取り上げ、非実験データを用いた社会科学における因果推論について述べる。
差の差分は、英語ではDifference in Differrenceとよばれ、しばしばDIDと略される。その基本的な考え方は、高度な数学を必要としない比較的単純なものであるが、その応用範囲は広く、社会科学の専門家でなくとも社会問題を考える上では身につけておくべきツールとなる。
ここで育児休業政策や保育政策等が女性の労働に及ぼす影響を評価することを目的とした研究の一環で、認可保育所の整備が母親の就業増につながるかどうかについての因果推定の例について述べる。
AAAI2019での因果推論に関する報告(外部ブログリンク)
AAAI2019での因果推論に関する報告(外部ブログリンク)
因果探索を中心とした話題
機械学習プロフェッショナルシリーズ「統計的因探索」読書メモ
機械学習プロフェッショナルシリーズ「統計的因探索」読書メモ。膨大なデータから、いかにして原因と結果の関係を見いだすのか? 「LiNGAM」(線形非ガウス非巡回モデル)を開発した第一線の研究者が、基礎事項から発展的話題まで平易に説き起こす。因果推論・因果探索に必携
統計的因果探索 – イントロダクション
統計的因果探索 – イントロダクション。チョコレートの消費量とノーベル賞の受賞者数を例とした、データ相関と因果関係の違い。チョコレートの消費量とノーベル賞の受賞者数はデータが相関しているように見えても、因果関係にあるわけではないことを、未観測共通原因を想定した異なる因果モデルでの検証により説明。
統計的因果推論の基礎(1)-反事実モデルによる因果の定義と構造方程式モデル
統計的因果推論の基礎(1)-反事実モデルによる因果の定義と構造方程式モデル。実質科学(substantial science)の主な目的は、因果関係を明らかにすることとなる。実質科学とは、自然科学や社会科学などの基礎科学や工学・医学などの応用化学を指す。実質科学の研究者は、解明したい現象や解決したい問題を具体的に持っている。たとえば「この薬を飲むと、あの病気うきが治るのか」「睡眠時間を長くすると、抑うつ気分が減少するのか」「研究開発費を増やすと、利益は減るのか」「チュコレートを食べるとノーベル賞が増えるのか」等になる。
実質科学に対して、統計学や機械学習などは方法論(mrthodology)と呼ばれる。方法論の研究者は、実質科学の目的を達成するための方法そのものを研究している。例えば、統計学や機械学習の研究者は、データ解析法を作ったり、精緻化したりしている。
統計的因果推論は、因果関係についてデータから推測するための方法論となる。大まかに言えば、何かを変化させた時に、何か他のものが変化すれば、その2つは因果関係にあるとする。では、この「何かを変化させたとき、何かほかのものが変化する(しない)とは、数学的にはどう表せるのか?
今回は、統計的因果推論で採用されている因果の考え方である反事実モデルについて述べ、データ生成過程を記述するための道具として、構造方程式モデルという数理モデルについて述べ、それら2つを基礎にして、因果推論のための数学的枠組みである構造的因果モデルについて述べる。
統計的因果推論の基礎(2) – 構造的因果モデルとランダム化実験
統計的因果推論の基礎(2) – 構造的因果モデルとランダム化実験。前回は反事実モデルによる因果の定義と構造方程式モデルについて述べた。今回は構造的因果モデルとランダム化実験について述べる。
因果推論のための代表的な枠組みである構造的因果モデル(structural casusal model)は、2つのモデルを基礎としている。一つは反事実モデルという因果のモデルで、もう一つは構造方程式モデルというデータ生成過程のモデルとなる。ここでは反事実モデルで定義される因果関係を、構造方程式モデルを用いて数学的に表現する。
まず、反事実モデルにおける集団レベルの因果を、構造方程式モデルを用いて表現する。最初に「介入(intervention)」と呼ばれる行動を、構造方程式モデルを用いて定義する。ある変数xに介入するとは、「ほかのどの変数がどんな値をとろうとも、変数xの値を定数cにとる」ことを意味する。他の変数とは、観測される変数も観測されない変数も含めてすべてとなる。このような介入を、doという記号を用いて、do(x=c)と現す。ちなみに、介入をどこからするのかといえば、モデルの外からとなる。どの変数をモデルに含めるかは分析者が判断する。つまりモデルの内と外を決めるのは分析者となる。
統計的因果探索の基礎(1)因果探索の枠組みと基本問題への3つのアプローチ
統計的因果探索の基礎(1)因果探索の枠組みと基本問題への3つのアプローチ。統計的因果推論の研究は、大きく2つに分かれる。一つは、因果グラフを既知として、どのような条件で因果に関する予測や説明が可能なのかを明らかにする研究。もう一つは、因果グラフを未知として、どのような条件で因果グラフが推測可能なのかを明らかにする研究となる。分かれる観点は、因果グラフを既知とするか未知とするかとなる。因果グラフを未知とするアプローチを特に、統計的因果探索と呼ぶ。
因果探索の基本問題へのアプローチは大きく分けて3つある。一つ目は、関数形にも外政変数の分布にも仮定を「おかない」ノンパラメトリックアプローチ(non-parametric approach)、2つめは、分析者の事前知識を過程としてモデルに取り入れ、関数形にも外生変数の分布にも仮定を置くパラメトリックアプローチ(parametric approach)、3つ目は、関数形には仮定をおく一方で、外生変数の分布には仮定を置かないセミパラメトリックアプローチ(semi-parametric approach)となる。
統計的因果探索の基礎(2)3つのアプローチの識別可能性
統計的因果探索の基礎(2)3つのアプローチの識別可能性。ノンパラメトリックアプローチ、パラメトリックアプローチ、セミパラメトリックアプローチの3つのアプローチほ、因果グラフの識別可能性(identifiability)の観点から比較する。ある仮定の下で「因果グラフの構造が異なれば、関数近似の分布が異なる」場合、その仮定の下で因果グラフが識別可能であるという。一方、「因果グラフの構造が異なっても、関数近似の分布が同じになることがある」場合、因果グラフは識別可能ではないという。
ここで制約が緩すぎて不明瞭なモデルとなってしまうため、制約を加える。追加する仮定として典型的なものが「誤差変数ei(i=1,…,p)は独立である」というものとなる。この仮定は未観測共通原因がないことを意味している。次に一般的なのが、因果関係が非巡回であるというものとなる。
統計的因果探索の基礎(3)因果的マルコフ条件、忠実性、PCアルゴリズム、GESアルゴリズム
統計的因果探索の基礎(3)因果的マルコフ条件、忠実性、PCアルゴリズム、GESアルゴリズム。統計的因果探索のためのノンパラメトリックアプローチ、パラメトリックアプローチ、セミパラメトリックアプローチの比較を行う。
まず、ノンパラメトリックアプローチの特徴をまとめる。因果グラフを推測するための標準的な原理に、因果的マルコフ条件(causal Markov condition)と呼ばれる観測変数間の条件付き独立性に基づく推測原理がある。因果的マルコフ条件とは「変数それぞれが、その親にあたる変数で条件付けると、その非子孫の変数と独立になる」こととなる。
この条件は、未観測共通原因がなく非巡回の構造方程式モデルであれば(つまり因果グラフが有向非巡回グラフ)、式(5)のような線形の場合だけでなく、非線形の場合や離散変数の場合も含めて一般的に成り立つ。そのため、関数形や誤差変数の分布に仮定をおかないノンパラメトリックアプローチでは、因果的マルコフ条件を用いて因果グラフを推測する。
因果グラフを推測するためには、因果的マルコフ条件だけでは不十分で、忠実性とよばれる追加の仮定が必要となる。
ノンパラメトリックアプローチの枠組みで、実際にデータから因果グラフを推測するためのアプローチについて述べる。大きく分けると2つの推測アプローチがある。
一つは、制約に基づくアプローチ(constrained-based approach)と呼ばれる。このアプローチでは、まず関数近似にどのような独立性が成り立つかをデータから推測する。次に、推測された条件付き独立性を制約として、それを満たすような因果グラフを探索する。代表的な推定アルゴリズムに、PCアルゴリズム(Peter and Clark, PC algorithm)がある。
もう一つは、スコアに基づくアプローチ(score-based approach)と呼ばれるもので、このアプローチでは、同じ条件付き独立性を与える因果グラフの集合であるあるマルコフ同値類ごとに、モデルの良さを評価するものとなる。
LiNGAM(1)独立成分分析について
LiNGAM(1)独立成分分析について。未観測共通原因がない場合のセミパラメトリックアプローチの代表的なモデルであるLiNGAMモデルについて述べる。LiNGAMモデルでは、観測変数の分布の非ガウス性を利用して、因果グラフを一意で推測可能となる。
今回は、LiNGAMモデル(linear non-Gaussian acyclic model)と呼ばれる構造的因果モデルについて述べる。そのために、まず独立成分分析と呼ばれる信号処理技術について述べる。
独立成分分析(Independent component analysis,ICA)は、信号処理分野で発展してきたデータ解析法となる。独立成分分析では、未観測変数の値が混ざり合って、観測変数の値が生成されると考える。たとえば、複数の話者の声が混ざり合って、複数のマイクによって観測されるという状況となる。
LiNGAM(2)LiNGAMモデルの理論
LiNGAM(2)LiNGAMモデルの理論。セミパラメトリックアプローチのうち、因果グラフが識別可能なモデルであるLiNGAMモデルについて述べる。
アプローチとしては、前述の独立成分分析をベースに、構造方程式モデルでの係数行列の推論について、係数行列と関係のある復元行列の対角成分が0でないように因果順序を並べ替える変換行列を求めることで行う。
LiNGAM(3)LiNGAMモデルの推定(1)独立成分分析と回帰分析を用いたアプローチ
LiNGAM(3)LiNGAMモデルの推定(1)独立成分分析と回帰分析を用いたアプローチ。LiNGAMモデルの係数行列Bの推定方法について詳しく述べる。アプローチとしては、大きく分けると2つある。一つは、独立成分分析の手法を採用するもの、もう一つは、回帰分析と独立性の評価を繰り返すもの。どちらの推定アプローチも、2段階で係数行列Bを推定する。一段目では、観測変数xiの因果的順序K(i)(i=1,…,p)を推定しする。前述のように、因果的順序k(i)(i=1,…p)に従って観測変数を並べ替えると、係数行列Bは厳密な下三角行列となる。従って、係数行列の上三角の成分はすべて0と推定できる。そこで二段目では、残りの下三角の成分を推定する。
今回は独立成分分析(ハンガリアン法)と回帰分析(適応型Lasso)を用いた具体的なアプローチについて述べる
LiNGAM(4)LiNGAMモデルの推定(2)回帰分析とを用いたアプローチ
LiNGAM(4)LiNGAMモデルの推定(2)回帰分析とを用いたアプローチ。回帰分析(regression analysis)と独立性の評価(examination of independence)を繰り返すことにより、観測変数xiの因果的順序を早い方から一つずつ推定するアプローチについて。
未観測共通項がある場合のLiNGAM(1) 独立成分分析で未観測共通原因を明示的にモデルに組み込むアプローチ
未観測共通項がある場合のLiNGAM(1) 独立成分分析で未観測共通原因を明示的にモデルに組み込むアプローチ。未観測共通原因がある場合のLiNGAMモデルとその推定法を考えるために、データを用いて因果関係を推測する例から考え始める。2つの観測変数x1とx2の因果関係に興味があるとする。ここでは、非巡回性を仮定して、2つの変数間の因果の向きと因果効果の大きさを推定することを考える。このような因果関係を表現するために、構造的因果モデルという枠組みを用いて、3つのモデルを比較する。
独立成分分析のアプローチは、未観測共通原因を明示的にモデルに組み込むものとなるが、この場合、未観測共通原因の数を特定する必要があるが、一般にそれらは無数にあると考えるのが自然で、データから適切な数を推定することは困難である場合が多くなる。
未観測共通項がある場合のLiNGAM(2)未観測共通原因を和としてモデル化するアプローチ
未観測共通項がある場合のLiNGAM(2)未観測共通原因を和としてモデル化するアプローチ。未観測共通原因を明示的にモデルに組み込まないアプローチとして、未観測共通原因の和を導入することで、未観測共通原因の変数を導入しないものを行う。
この混合モデルに基づくアプローチの特徴は、未観測共通原因を個別にモデルに入れるのではなく、和としてモデルに入れる点にある。そのおかげで、未観測共通原因の分布をそれぞれモデル化する必要もなく、そして、その数や係数も推定する必要もない。その代わり、観測ごとの切片をパラメータとしてモデルに入れる必要がある。変数x1とx2のそれぞれに切片はあるので、観測の下図の2倍の切片パラメータが必要となる。
統計的因果推論 – 拡張アプローチ
統計的因果推論 – 拡張アプローチ。線形性、非巡回性、非ガウス性というLiNGAMアプローチの仮定をどこまでゆるめられるかについての研究が行われている。ここでは、その代表的な拡張モデルについて述べる。
現状では、未観測共通原因はないとする場合の研究が大半だが、それらの研究をもとに、未観測共通原因のある場合への研究へと徐々に移行しつつある。未観測胸痛原因をなんとかしなければ、疑似相関の問題という因果探索の根本的な課題が残ったままになる
VARモデルによる因果関係の推論(1)欠測の補間とDF、ADF検定
VARモデルによる因果関係の推論(1)欠測の補間とDF、ADF検定。ある時系列から別の時系列に対して因果関係があるかという問いは、少なくとも2つの時系列データが関心事であることを前提としている。時系列に基づく因果推論は、本質的に多変量時系列の問題であり、モデルとしては多変量自己回帰モデル(Vector AutoRegression model, VARモデル)が用いらられることが多い。
ここでは、内閣支持率と株価の因果関係を例に、VARモデルに基づく因果関係の分析の手順を、フリーソフトウェアRを用いて述べる。データにはしばしば欠損が伴うが、今回取り上げる内閣支持率も例外ではない。ここではRのtimsacパッケージに含まれる関数decompを使った欠陥値補間を取り上げる。またVARモデルによる因果分析では時系列の定常性を仮定するので、定常・非定常のチェックや、定常化のための前処理が必要となる。そのための手順とそこで用いられる単位根検定(unit root test)の使い方についても述べる。制御なし/制御付きVARモデルの推定、ラグ選択、因果検定、インパルス応答関数の算出などには、Rのパッケージvarsを利用する。
VARモデルによる因果関係の推論(2)多変量自己回帰(VAR)モデルとVARモデルを使った因果推定
VARモデルによる因果関係の推論(2)多変量自己回帰(VAR)モデルとVARモデルを使った因果推定。ここでは、時系列の因果性を分析する枠組みとして、多変量自己回帰モデル(VARモデル)を導入する。RパッケージでVARモデルを扱うことができるものがいくつか存在するが、ドキュメントも充実していてよく使われるものはBernhard Pfaffによるパッケージvarsとなる。時系列ytを予測するのに、他の時系列xtの過去の値が役に立つとき、時系列xtからytに「グレンジャーの意味で因果性がある」という。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
