イントロダクション
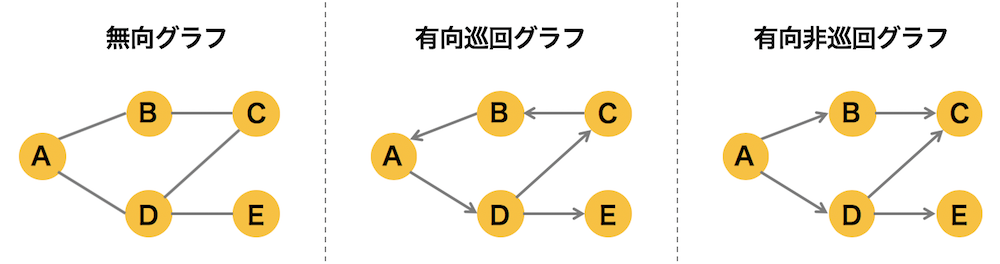
有向非巡回グラフ(Directed Acyclic Graph, DAG)は、様々なタスクの自動管理、あるいはコンパイラ等の処理など様々な場面で登場するグラフデータアルゴリズムとなる。今回は、このDAGについて述べてみたいと思う。
有向非巡回グラフについて
有向非巡回グラフ(Directed Acyclic Graph, DAG)とは、有向グラフの一種であり、任意の頂点から出発しその経路上にループ(巡回)がある”有向巡回グラフ”でなく、ループが存在しないものを指す。これは、ある頂点から出発して有向辺をたどっていくと、同じ頂点を二度以上通過することがないことを意味する。

DAGはこのような特徴を利用することで、以下に示すような様々な応用分野で使われている。
- 依存関係の表現: DAGは、タスクや処理の依存関係を表現するのに使用される。これは、各タスクや処理を頂点とし、依存関係を有向辺で表現することで、タスクの実行順序や依存関係を効率的に管理する使い方となる。具体的には、フトウェア開発での、ソースコードやモジュール間の依存関係を管理や、データ処理パイプライン、コンパイル処理等で利用されている。
- スケジューリング: DAGは、複数のタスクやジョブの実行順序を決定するために使用される。これは例えば、コンパイルやデータフロープログラミングなどでは、各処理や演算あるいはタスクを頂点とし、データの依存関係を有向辺で表現することで、最適な実行順序を求めるような使い方となる。
- プログラムフローチャート: プログラムの制御フローをグラフで表現する際に、DAGが使用されることがある。条件分岐やループを頂点や辺で表現することで、プログラムの構造を視覚的に理解しやすくなる。
- コンパイル処理: プログラミング言語のコンパイルでは、ソースコードをトークン化し、構文解析して構文木を構築する。このとき、依存関係をDAGとして抽出し、コンパイルの順序や最適化のための情報を得ることができる。
- データ解析や機械学習: DAGは、データフローや計算グラフの表現に利用され、特に、機械学習のモデルやアルゴリズムの計算グラフをDAGで表現することで、効率的な計算や自動微分などの高度な解析手法が可能になる。また、ビッグデータ処理やデータパイプラインでは、データのフローをDAGで表現することが一般的であり、各処理ステップやデータストリームを頂点とし、処理の依存関係を有向辺で表現することで、データの流れや処理の順序を制御するものとなる。
これらはDAGの一般的な応用例だが、実際には様々な分野で幅広く利用されているものとなる。DAGは、頂点と辺の組み合わせによって構成されるデータ構造であり、その特性を活かして様々な問題を効率的に解決することができる。
以下で詳細について述べる。
DAGによる依存関係の抽出の適用事例について
DAGは、依存関係の抽出や解析に幅広く使用されており、以下に、それらの適用事例について述べる。
- ソフトウェア開発プロジェクト: ソフトウェア開発では、ソースコードやモジュール間の依存関係を管理する必要がある。これにDAGを適用して、ソースコードのビルドやテストの順序を決定したり、変更の影響範囲を把握したりすることが可能となる。また、バージョン管理システムや依存関係管理ツール(例:MavenやGradle)もDAGを使用して依存関係を解決している。
- タスクスケジューリング: タスクやジョブの実行順序を決定するためにDAGが使用されている。これは例えば、プロジェクト管理やワークフローシステムで、各タスクを頂点とし、依存関係を有向辺で表現することで、タスクの実行順序や依存関係を効果的に管理するようなものとなる。
- データ処理パイプライン: ビッグデータ処理やデータパイプラインでは、データのフローをDAGで表現することが一般的となる。これは各処理ステップやデータストリームを頂点とし、処理の依存関係を有向辺で表現することで、データの流れや処理の順序を制御するものとなる。
- コンパイル処理: プログラミング言語のコンパイルでは、ソースコードをトークン化し、構文解析して構文木を構築している。このとき、依存関係をDAGとして抽出し、コンパイルの順序や最適化のための情報を得ることができる。
DAGは、依存関係の複雑さを可視化し、効率的な解析やタスクの実行順序の決定に役立つ強力なツールとなる。
DAGによるスケジューリングの適用事例について
DAGは、スケジューリング(タスクの実行順序の決定)の最適化にも広く適用されている。以下に、DAGを使用したスケジューリングの適用事例について述べる。
- プロジェクト管理: プロジェクトの実行やタスクのスケジューリングにDAGが使用されている。これは、プロジェクト内のタスクや作業パッケージを頂点とし、タスク間の依存関係を有向辺で表現したDAGを使用することで、各タスクの実行順序を決定し、プロジェクトの進捗管理やリソースの効率的な割り当てを行うことを可能としている。
- ワークフローマネジメント: ワークフローシステムでは、ビジネスプロセスやタスクの自動化にDAGが使用されている。これは、各タスクやアクションを頂点とし、タスク間の依存関係を有向辺で表現したDAGを使用することで、タスクの実行順序や条件付きの分岐などを制御し、ワークフローの効率化やエラーハンドリングを可能としている。
- バッチ処理やデータ処理: バッチ処理やデータ処理パイプラインでは、タスクや処理ステップをDAGで表現し、依存関係を定義することができる。これは、各タスクは頂点として表され、タスク間のデータフローを有向辺で表現したDAGを使用することで、データ処理のフローを最適化し、タスクの並列実行やデータ依存関係の解決を可能としている。
- ジョブスケジューリング: クラウドコンピューティングや分散システムでは、ジョブのスケジューリングにDAGが使用されている。これは、各ジョブを頂点とし、ジョブ間の依存関係やリソース要件を有向辺で表現したDAGを使用することで、ジョブの実行順序や並列実行可能性を決定し、リソースの最適な利用や処理時間の効率化を可能としている。
DAGを用いたプログラムフローチャートの適用事例について
DAGは、プログラムフローチャートの作成や可視化にも使用されている。以下に、DAGを使用した適用事例について述べる。
- アルゴリズムの可視化: 複雑なアルゴリズムの手順や条件分岐を視覚化するために、DAGを使用したプログラムフローチャートが利用されている。各手順や処理ステップを頂点とし、制御フローを有向辺で表現したDAGを使用することで、アルゴリズムの流れやロジックを明確にし、理解やデバッグを容易にする。
- 制御フローの解析: 大規模なプログラムや複雑な制御フローを持つソフトウェアの解析において、DAGを使用したプログラムフローチャートが役立つ。これは、制御フローグラフを作成し、ソフトウェアの動作を視覚化したDAGを使用することで、コードの実行パスや条件分岐の経路を追跡し、ソフトウェアの振る舞いを分析することを可能としている。
- プログラムの最適化: プログラムフローチャートを使用して、プログラムの実行パスや依存関係を可視化することで、プログラムの最適化やパフォーマンス改善が可能となる。DAGを使用して、ボトルネックとなる部分や不要な計算を特定し、効率的なプログラムの設計や最適化手法の適用をサポートすることができる。
- テストケースの設計: プログラムフローチャートを使用して、テストケースの設計やカバレッジの解析が行うためにDAGを使用して、各パスや条件分岐を網羅するテストケースを特定し、コードの網羅率や品質の評価を可能とする。
DAGを用いたデータ解析や機械学習の適用事例について
DAGは、データ解析や機械学習のさまざまな適用事例において有用となる。以下に、DAGを使用した適用事例について述べる。
- ベイジアンネットワーク(Bayesian Networks): ベイジアンネットワークは、確率モデルを表現するためのDAGの一形式となる。これは、変数や事象を頂点とし、条件付き依存関係を有向辺で表現されている。ベイジアンネットワークを使用して、データ解析や推論を行い、潜在的な関係や確率分布を推定することができる。
- 因果推論(Causal Inference): 因果推論は、DAGを使用して因果関係をモデル化し、因果関係の推定や因果効果の解析を行う手法となる。変数や要因を頂点とし、因果関係を有向辺で表現した因果推論を使用することで、観測データから因果関係を特定し、介入の効果や因果メカニズムを推論することができるようになる。
- データフローパイプライン: データ処理や機械学習のパイプラインでは、データフローや処理の依存関係をDAGで表現することができる。データ変換や特徴抽出のステップを頂点とし、データのフローを有向辺で表現したDAGを使用することで、データの前処理、特徴エンジニアリング、モデルトレーニングなどの一連の処理の効率化を可能とする。
- グラフニューラルネットワーク(Graph Neural Networks): グラフニューラルネットワークは、DAGを使用してグラフ構造のデータに対する機械学習を行う手法となる。ノードやエッジを頂点とし、グラフ内の情報伝播を有向辺で表現し、グラフニューラルネットワークを使用して、ノードやエッジの特徴量を学習し、グラフデータ上でのタスク(例:グラフ分類、グラフ生成)を実行することができる。
DAGの解析に用いられるアルゴリズムについて
DAGの解析には、いくつかの重要なアルゴリズムが存在する。以下にそれらの中から代表的なものについて述べる。
- トポロジカルソート(Topological Sort): トポロジカルソートはDAG内の頂点を線形な順序で並べるアルゴリズムとなる。これは、依存関係の解決やタスクの順序付けに利用される。
- 最短経路アルゴリズム(Shortest Path Algorithms): DAGにおいて、ある特定の頂点から他のすべての頂点への最短経路を求めるために使用される。代表的なアルゴリズムとしては、ダイクストラ法(Dijkstra’s algorithm)やベルマン-フォード法(Bellman-Ford algorithm)がある。
- 動的計画法(Dynamic Programming): DAG上での動的計画法は、部分問題の結果を再利用することで効率的に問題を解決する手法となる。これは、DAGのトポロジカルソート順に部分問題を解決し、その結果を利用して大局的な解を導く。
- 強連結成分分解(Strongly Connected Components): 強連結成分分解は、DAG内の頂点を互いに到達可能なグループに分解するアルゴリズムとなる。各グループは強連結成分と呼ばれ、強連結成分分解は、グラフの解析や分析においてサブグループの特性を把握するために使用される。
以下にそれらの詳細について述べる。
トポロジカルソートについて
<概要>
トポロジカルソートは、ある頂点から別の頂点への依存関係が存在する場合に、それらの頂点を適切な順序で並べることが目的のアルゴリズムで、DAGでの頂点の順序付けを行うものとなる。
トポロジカルソートは主に、グラフ内のタスクやイベントの依存関係を解決するために使用され、これは例えば、ソフトウェアのビルドシステムで依存関係の解決や、プロジェクトのタスクの実行順序の決定などに応用されている。
トポロジカルソートの手順は以下のようになる。
- 入次数(in-degree)が0の頂点を選び、出力列に追加する。入次数とは、ある頂点に入ってくる辺の数を意味する。
- 選択した頂点に隣接する頂点の入次数を1減らす。これは、選択した頂点に依存している頂点が一つ解決されたことを意味する。
- 入次数が0になった頂点を選び、出力列に追加し、これを繰り返す。
- グラフに残っている頂点がなくなるまで、手順2-3を繰り返す。
もし、グラフ内にサイクル(閉路)が存在する場合、その中の頂点同士で依存関係が循環するため、トポロジカルソートは実行できない。また、トポロジカルソートは一意な解を持つ場合と複数の解を持つ場合があり、一意な解を持つのは、DAGが1つの連結成分を持ち、かつその連結成分が有向木(DAGの特殊な形態)である場合であり、複数の解を持つのは、複数のノードが同じレベル(深さ)にある場合で、これは、それらのノード間に依存関係がないため、順序を入れ替えることができる場合となる。トポロジカルソートでは、このように同じレベルのノードの順序は特定されない。
トポロジカルソート(Topological Sort)は、有向非巡回グラフ(DAG)において、頂点を線形な順序で並べる操作です。この並び順は、グラフ内のすべての辺が指す先の頂点よりも前に来るように定義されます。つまり、ある頂点から出発して他の頂点に到達するためには、その他の頂点は必ずその頂点よりも後になければならないという特徴があります。
トポロジカルソートは、依存関係のあるタスクや処理の実行順序を決定するために使用されます。典型的な例としては、ソフトウェアのビルドやタスクスケジューリングなどが挙げられます。
<pythonによる実装>
以下にPythonでのトポロジカルソートの実装例を示す。
from collections import defaultdict
def topological_sort(graph):
# 頂点の訪問状態を管理する配列
visited = defaultdict(bool)
# トポロジカルソート結果を格納するリスト
result = []
# 深さ優先探索を実行する関数
def dfs(node):
visited[node] = True
for neighbor in graph[node]:
if not visited[neighbor]:
dfs(neighbor)
result.append(node)
# 各頂点を出発点として深さ優先探索を実行
for node in graph.keys():
if not visited[node]:
dfs(node)
# 結果を逆順にしてトポロジカルソート結果を返す
return result[::-1]この実装では、グラフは辞書型で表現されており、キーは頂点を表し、値はその頂点から出る辺の先の頂点のリストであり、graph変数にはこの辞書が渡される。topological_sort関数は、深さ優先探索を使用してトポロジカルソートを行い、visited辞書は各頂点の訪問状態を管理し、resultリストにはソートされた頂点が逆順で追加され、最後に、resultリストを逆順にしてトポロジカルソートの結果を返す。以下は実行例となる。
# 有向非巡回グラフの定義(辞書型)
graph = {
'A': ['B', 'C'],
'B': ['D'],
'C': ['D', 'E'],
'D': ['E'],
'E': []
}
# トポロジカルソートの実行
sorted_vertices = topological_sort(graph)
# 結果の表示
print(sorted_vertices)上記の例では、与えられたグラフに対してトポロジカルソートを行い、結果を表示している。出力は['A', 'C', 'E', 'D', 'B']となる。
ダイクストラ法(Dijkstra’s algorithm)とベルマン-フォード法(Bellman-Ford algorithm)
<概要>
ダイクストラ法(Dijkstra’s algorithm)とベルマン-フォード法(Bellman-Ford algorithm)は、グラフ内の最短経路問題を解決するためのアルゴリズムとなる。これらのアルゴリズムは、グラフの頂点とエッジの重みを考慮して、ある出発点から他の頂点までの最短経路を見つけることができる。
ダイクストラ法は、単一始点最短経路問題を解決するために使用され、具体的には、非負の重みを持つ有向グラフ内で最短経路を見つけることができるものとなる。アルゴリズムは、始点からの最短距離が確定されていない頂点の中で、最も距離の短い頂点を選択して、その頂点から直接繋がっている頂点の距離を更新していくという手法を用いる。この過程を繰り返し、すべての頂点の最短距離が確定するまで続ける。
一方、ベルマン-フォード法は、負の重みを含む有向グラフ内で最短経路を見つけるために使用される。アルゴリズムは、頂点の集合に対して反復的な更新を行い、より短い経路が見つかるかどうかを確認するものとなる。ベルマン-フォード法は、負の重みの辺を持つ場合にも動作する一方で、ダイクストラ法は負の重みを持つグラフでは正しい結果を得ることができない。
ダイクストラ法とベルマン-フォード法の主な違いは、実行時間の効率性と扱えるグラフの制約となる。ダイクストラ法は、負の重みを持たないグラフにおいて最短経路を高速に求めることができるが、負の重みを持つ場合には正しい結果が得られない。一方、ベルマン-フォード法は負の重みを含むグラフでも動作するが、より遅い実行時間を要することがある。
<pythonによる実装>
以下に、Pythonでのダイクストラ法とベルマン-フォード法の実装例を示す。
ダイクストラ法の実装例:
import heapq
def dijkstra(graph, start):
distances = {node: float('inf') for node in graph} # 各ノードの距離を無限大で初期化
distances[start] = 0 # 始点の距離を0に設定
queue = [(0, start)] # (距離, ノード)のタプルを格納する優先度付きキュー
while queue:
current_distance, current_node = heapq.heappop(queue) # 最小距離のノードを取得
if current_distance > distances[current_node]:
continue
for neighbor, weight in graph[current_node].items():
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(queue, (distance, neighbor))
return distances
使用例:
graph = {
'A': {'B': 5, 'C': 2},
'B': {'D': 4, 'E': 2},
'C': {'B': 8, 'E': 7},
'D': {'E': 6, 'F': 3},
'E': {'F': 1},
'F': {}
}
start_node = 'A'
distances = dijkstra(graph, start_node)
print(distances)ベルマン-フォード法の実装例:
def bellman_ford(graph, start):
distances = {node: float('inf') for node in graph} # 各ノードの距離を無限大で初期化
distances[start] = 0 # 始点の距離を0に設定
for _ in range(len(graph) - 1):
for node in graph:
for neighbor, weight in graph[node].items():
distance = distances[node] + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
# 負の重みのサイクルの検出
for node in graph:
for neighbor, weight in graph[node].items():
if distances[node] + weight < distances[neighbor]:
raise ValueError("負の重みのサイクルが存在します。")
return distances
使用例:
graph = {
'A': {'B': -1, 'C': 4},
'B': {'C': 3, 'D': 2, 'E': 2},
'C': {},
'D': {'B': 1, 'C': 5},
'E': {'D': -3}
}
start_node = 'A'
distances = bellman_ford(graph, start_node)
print(distances)上記の実装例では、グラフは辞書として表現されており、各ノードとその隣接ノードの重みが辞書の形式で格納されている。ダイクストラ法では優先度付きキュー(heapq)を使用してノードを選択し、ベルマン-フォード法では二重のループを使用して最短経路を更新する。
動的計画法について
動的計画法(Dynamic Programming)は、複雑な問題をより小さなサブ問題に分割し、それぞれのサブ問題の解を保存して再利用することで効率的に解を求める手法となる。動的計画法は、再帰的な関係や最適性の原理を利用して問題を解決するアルゴリズムの設計手法である。
動的計画法の基本的なアイデアは、「最適な部分構造」と呼ばれる性質を利用することで、最適な解が複数の部分問題の最適な解から構成される場合、それぞれの部分問題の解を保存しておくことで、重複した計算を回避し効率的に解を求めることができるものとなる。
動的計画法の一般的な手順は以下のようになる。
- 問題を小さな部分問題に分割し、部分問題は重複しないように設計される。
- 部分問題の解を再帰的または反復的に計算し、計算された解はメモ化(保存)される。
- 最終的な解を構築するために、部分問題の解を組み合わせるか、再帰的に結果を取得する。
動的計画法は、最適化問題や組み合わせ問題、最短経路問題などさまざまな問題に適用することができ、代表的な動的計画法の例としては、フィボナッチ数列の計算やナップサック問題の解決などがある。
動的計画法の利点は、再帰的な関係性を効率的に扱える点であり、一度計算した部分問題の解はメモ化されるため、同じ部分問題が複数回現れても再計算を行わずに済む。ただし、動的計画法はすべての部分問題を網羅的に解く必要があるので、問題の性質によっては指数的な時間やメモリを必要とすることがある。
<動的計画法を用いたトポロジカルソートのpythonによる実装>
動的計画法を用いてトポロジカルソートを行う場合、各ノードのトポロジカルソート順を計算して保存し、再利用するアプローチをとる。以下にPythonでの動的計画法を用いたトポロジカルソートの実装例を示す。
def topological_sort(graph):
# 各ノードのトポロジカルソート順を保存する辞書
order = {}
def dfs(node):
if node in order:
return order[node]
max_order = 0
for neighbor in graph[node]:
neighbor_order = dfs(neighbor) + 1
max_order = max(max_order, neighbor_order)
order[node] = max_order
return max_order
# 全てのノードに対してdfsを実行
for node in graph:
dfs(node)
# トポロジカルソート順にノードをソート
sorted_nodes = sorted(graph, key=lambda x: order[x], reverse=True)
return sorted_nodes使用例:
graph = {
'A': [],
'B': ['A'],
'C': ['A'],
'D': ['B', 'C'],
'E': ['D'],
'F': ['D'],
'G': ['E', 'F']
}
sorted_nodes = topological_sort(graph)
print(sorted_nodes)上記の実装例では、topological_sort関数が与えられたグラフをトポロジカルソートして、ソートされたノードのリストを返す。関数内部で再帰的にdfs関数を呼び出し、各ノードのトポロジカルソート順を計算してorder辞書に保存している。最終的に、order辞書に基づいてノードをソートし、ソートされたノードのリストを返す。
強連結成分分解(Strongly Connected Components)
<概要>
強連結成分分解(Strongly Connected Components)は、有向グラフをより小さな強連結成分(強連結な頂点の集合)に分割する手法となる。強連結成分は、互いに相互に到達可能な頂点の集まりであり、グラフ内の部分構造として特徴付けられる。
強連結成分分解は、有向グラフにおける重要なアルゴリズムであり、さまざまな応用がある。これは例えば、グラフ内の依存関係の解析や、コンパイラの最適化などで利用されるものとなる。
強連結成分分解アルゴリズムは、通常、「深さ優先探索(DFS)」と「逆辺グラフの探索」の2つのフェーズで実行される。以下は、強連結成分分解の基本的なアルゴリズムの手順となる。
- 与えられた有向グラフに対して、深さ優先探索(DFS)を行う。この探索では、各頂点に訪問時刻や終了時刻を記録する。
- グラフのすべての辺の向きを逆転させ、逆辺グラフを作成する。
- 逆辺グラフに対して、訪問時刻の降順に深さ優先探索(DFS)を行う。この探索では、各頂点に所属する強連結成分の情報を記録する。
- 得られた強連結成分の集合が強連結成分分解の結果となる。
<Pythonによる実装>
以下にPythonでの強連結成分分解の実装例を示す(Tarjanのアルゴリズムを使用)
def tarjan_scc(graph):
index_counter = [0]
index = {}
lowlink = {}
on_stack = set()
stack = []
result = []
def strongconnect(node):
index[node] = index_counter[0]
lowlink[node] = index_counter[0]
index_counter[0] += 1
stack.append(node)
on_stack.add(node)
for neighbor in graph[node]:
if neighbor not in index:
strongconnect(neighbor)
lowlink[node] = min(lowlink[node], lowlink[neighbor])
elif neighbor in on_stack:
lowlink[node] = min(lowlink[node], index[neighbor])
if lowlink[node] == index[node]:
scc = []
while True:
w = stack.pop()
on_stack.remove(w)
scc.append(w)
if w == node:
break
result.append(scc)
for node in graph:
if node not in index:
strongconnect(node)
return result使用例:
graph = {
'A': ['B'],
'B': ['C'],
'C': ['A', 'D'],
'D': ['E'],
'E': ['F'],
'F': ['D']
}
sccs = tarjan_scc(graph)
for scc in sccs:
print(scc)上記の実装例では、tarjan_scc関数が与えられた有向グラフの強連結成分分解を行い、関数内部でTarjanのアルゴリズムを使用し、深さ優先探索(DFS)と逆辺グラフの探索を行いながら、強連結成分を見つけている。最終的に、強連結成分のリストが返される。実行結果は以下のようになる。
['E', 'F', 'D']
['C', 'B', 'A']この結果から、グラフ内の強連結成分が2つ見つかり、1つ目の強連結成分は’E’, ‘F’, ‘D’であり、2つ目の強連結成分は’C’, ‘B’, ‘A’となる。
最後に、DAGと関連のあるブロックチェーン技術について述べる。
ブロックチェーン技術とDAG
ブロックチェーン技術とDAGは、両方とも分散型台帳技術の一形態が、いくつかの重要な違いがある。
ブロックチェーンは、トランザクションをブロックという単位にまとめ、それらのブロックを連結させることでトランザクションの履歴を記録する。各ブロックは直前のブロックのハッシュ値を参照し、チェーンとして繋がっている。このブロックの連結は、一連のトランザクションの順序性と信頼性を確保するために重要であり、主な利点としては、セキュリティと信頼性が高いことが挙げられる。しかし、ブロックチェーンはブロックが順次追加されるため、トランザクションのスケーリングに課題を抱えることがある。
一方、DAGは、ブロックチェーンのような直線的なチェーンではなく、グラフ構造を持つものとなる。DAGでは、トランザクションがブロックにまとめられるのではなく、個々のトランザクションが互いに参照し合う形で接続される。この接続性により、トランザクションの非同期的な承認が可能となり、スループットの向上とスケーリングの改善が期待される。
DAGの主な利点は、ネットワークのスケーリングとトランザクションの高速化であり、DAGでは、複数のトランザクションが同時に処理され、トランザクションの承認時間が短縮される。また、トランザクションの手数料も削減される場合がある。
ただし、DAGにはいくつかの課題も存在している。これは例えば、トランザクションの順序性が保証されないため、二重支払いや不正な操作のリスク等になる。また、DAGの設計やセキュリティの確保が難しい場合もある。
要約すると、ブロックチェーンはトランザクションの順序性と信頼性を重視し、DAGはスケーリングと高速化を重視している技術となる。それぞれの技術は異なる利点と課題を持っており、適切な使用ケースに応じて選択する必要がある。
参考情報と参考図書
DAGを含めたグラフデータのハンドリングに関する詳細情報としては”グラフデータ処理アルゴリズムと機械学習/人工知能タスクへの応用“がある。こちらも参照のこと。またブロックチェーン技術に関しては”ブロックチェーンの衝撃 ビットコイン、FinTechからIoTまで社会構造を覆す破壊的技術 – 読書メモ“にも詳細を述べている。
参考図書としては”グラフ理論“

“アルゴリズムイントロダクション 第3版 第2巻: 高度な設計と解析手法・高度なデータ構造・グラフアルゴリズム“

“Pythonで学ぶアルゴリズムとデータ構造 データサイエンス入門シリーズ“等がある。


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
