サマリー
「Apache Spark入門 動かして学ぶ最新並列分散処理フレームワーク」より。 前回はApache Sparkの分散データ処理モデルについて述べた。今回はSparkを動作させる環境の整備について述べる。
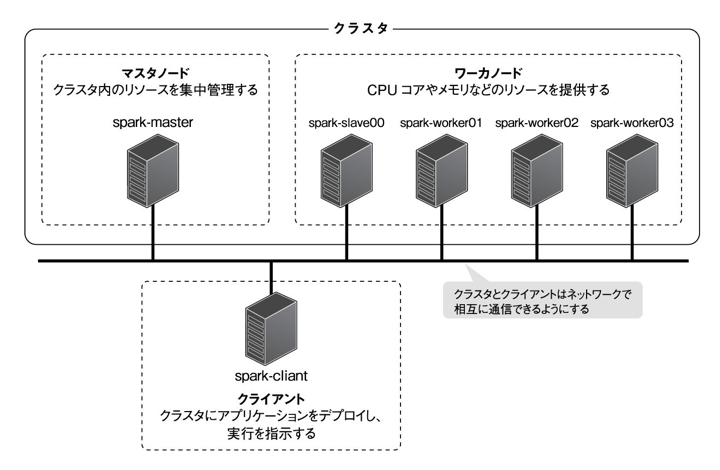
Sparkはクラスタ上での動作を前提としている。しかし作成中のアプリケーションの挙動を確認したい場合や、機能テストを行いたい場合はクラスタ環境を構築するのは大掛かりで面倒であるので、単一のマシン上でのsparkを動作さらることも可能となっている。今回はまず単一マシン上での環境構築について述べ、さらにクラスタ環境を構築する手順について述べる。
マシン構成
- spark-client :クライアントとして動作するマシンで、クラスタにアプリケーションをデプロイし、実行を指示する役割を担う(単一マシン環境ではこのマシンだけを使う)
- spark-master : クラスタ内のリソースを集中管理するマシン。マスターノード
- spark-worker : CPUコアメモリなど、アプリケーションの実行に必要なリソースを提供する。クラスタのワーカーノードの役割を担う
クラスタ環境ではHadoopのクラスタ管理システムYARNを利用する。また、Sparkのデータソースとして主に分散ファイルシステムHDFSをを利用する。これらはspark-masterおよびspark-worker上に構築する。また、HDFSへのファイルの投入や閲覧、取得を行うのに、spark-clientを利用する。

Sparkのパッケージ
SparkのインストールにはApache Software Foundationが配布しているコミュニティ版のバイナリに加えて米Clouderaや米Hortonworksなどのベンダが配布しているHadoop distributionのパッケージが利用できる。
ベンダ製パッケージを用いるとSparkだけではなくHDFSやYARNなどHadoopのコンポーネントもRPMで容易にインストールできる。またバグフィックスのパッチがバックポートされていたりコミュニティ版のSparkをベースに独自の改良が加えられたものとなっている。一方でSparkのリリースサイクルと各ベンダのディストリビューションのリリースサイクルが異なっている為、Sparkの最新バージョンが同梱されるのはコミュニティ版がリリースされた少し後になる傾向がある。今回はコミュニティ版のSparkをインストールする。
Sparkの開発環境の設定
Sparkは、Linux、Mac、Windowsでの動作をサポートしている。今回はCentOSを用いたケースについて述べる。環境構築や動作確認は一般ユーザーを作成しその上で行う。またSparkの動作やアプリケーションの開発にはJDK(Java Development Kit)が必要になるためインストールを行う。Linuxの場合はOracleのWebページから64ビット版Linux向けのJDKのRPMパッケージをダウンロードし、(/tmpにダウンロードした)ダウンロードしたRPMパッケージを用いてインストールを行う。
>sudo rpm -ivh /tmp/jdk-<HDKのバージョン>-linux-x64.rpm続いて、環境変数JAVA_HOMEとPATHを設定する。ここでは/etc/profile.d/java.shファイルをroot権限で作成し、以下のように編集する。
export JAVA_HOME=/usr/java/default
export PATH="$JAVA_HOME"/bin:"$PATH"編集が完了したら、設定内容を反映させる。
> source /etc/profile設定が完了したら、javaコマンドが使えることを確認する。
> java -version
java version "<JDKのバージョン>"
…Sparkのインストール
続いてSparkをインストールする。この手順はspark-clientだけで実施する。コミュニティ版のビルド済みバイナリは以下のページより入手する。

SparkをHDFSやYARNと組み合わせて使用する場合、Sparkはこれらのクライアントとして動作する。SparkはHDFSやYARNを利用する為に、内部にHDFSやYARNのクライアントAPIを使用している。それらのベースになっているHadoopのバージョンに合わせたバイナリが必要となる。今回はHDFSとYARNの環境はCDH5.4に同梱されているものを使う。
CDH5.4はHadoop2.6をベースとしているため、Hadoop2.6以上向けにビルドされたSpark1.5のバイナリをダウンロードする。
ダウンロードしたファイルを/opt/sparkディレクトリにインストールする。
> sudo tar zxvf /tmp/spark-1.5.0-bin-hadoop2.6.tgz -C /opt/
> cd /opt
> sudo ln -s spark-1.5.0-bin-hadoop2.6saprk続いて環境変数SPARK_HOMEを設定する。ここでは/etc/profile.d/spark/shファイルをユーザー権限で作成し、以下のように編集する。
export SPARK_HOME=/opt/spark編集が完了したら設定を反映させる。
> source /etc/profile設定が完了したら、spark-userがSparkのコマンドを使用できることを確認する。
> ${SPARK_HOME}/bin/spark-submit -- version
Welcome to
………続いて動作確認を行う。Spark本体には、サンプルプログラムがいくつか組み込まれている。その中の円周率の近似値をモンテカルロ法で計算するSparkPiというサンプルプログラムを利用する。
> ${SAPRK_HOME}/bin/spark-submit -- class org.apache.spark.examples.SparkPi
${SPARK_HOME}/lib/spark-examples-1.5.0-hadoop2.6.0.jar
Pi is roughly 3.14162開始後、円周率の近似値が出力されれば動作確認は完了する。
以上で、Sparkを単一のマシンを動作させる環境の構築が完了する。
Sparkのクラスタ環境の為の追加手順
追加の手順としてHDFSとTARNの構築について述べる。またクライアントにHDFSとYARNを追加するための追加設定を行う。
HDFSはHadoopの分散ファイルシステムで、HDFSもまたクラスタ環境で動作する前提で設計されており、NameNodeと呼ばれるマスターノードとDataNodeと呼ばれる複数のワーカーノードから構成されている。
NameNodeは、HDFSのマスターノードであり、ファイルをブロックに分割し各ブロックをDataNodeに分散して格納することで、数GB、数PBといった巨大なデータの格納を可能としている。一般的なファイルシステムと比較してブロックサイズがデフォルトで128MBと大きく、巨大なデータに対して高いI/Oスループットを実現するように設計されている。
HDFSはスレーブノードであるDataNodeを追加することでI/Oのスループットや格納容量を容易にスケールアウトできる。また、ブロックをデフォルトで3つのDataNodeに冗長化して格納することで、スレーブノードが故障してもデータ欠損しない構造が古風されている。
またHDFS上に格納されるファイルのメタデータや格納されているファイルの実態を分割した断片(ブロック)がどのDataNodeで管理されているかなどの情報を管理するものとなる。
DataNodeは、HDFSのワーカーノードであり、HDFS上に格納されているファイルのブロックを管理するものとなる。
YARNはHadoopのクラスタ管理システムとなる。Sparkに限らず、様々な分散処理フレームワークで実装されたアプリケーションを動作させる環境を提供/管理するための基盤となる。YARNはResourceManagerと呼ばれるマスターノードとNodeManagerと呼ばれる複数のワーカーノードから構成されている。
ResourceManagerは、クラスタ全体の計算リソースを管理し、クライアントから要求されたリソースをNodeManagerから確保するようスケジューリングする。Sparkでは、要求されたエグゼキュータの数やCPUコア数、メモリ数に応じたエグゼキュータを一つ以上のNodeManagerから確保する役割を担う。
NodeManagerは、自身がコントロールされているマシンの計算リソースを管理し、ResourceManagerからの要求に応じて、必要とする計算リソースを切り出したコンテナと呼ばれるアプリケーションの実行環境を提供する。要求されたコンテナの数に応じて複数のNodeManagerからコンテナが切り出され、分散処理を行う。Sparkでは、切り出されたコンテナ上でエグゼキュータが動作する。
下図のように各マシンにHDFSとYARNのコンポーネントをインストールする。

一般にDataNodeとNodeManagerは同じマシンにインストールする。これはデータローカリティを生かすためとなる。NameNodeとResourceManagerは可用性の観点や運用製の観点などを勘案し、同一マシンにインストールする場合と物理的に異なるマシンにインストールする場合がある。
今回はspark-masterにNameNodeとResourceManagerの両方をインストールする。また、spark-clientはHDFSに対するファイルのアクセスを行ったり、HDFSやYARNの状態確認を行うため、HDFSとYARNのクライアント用のコンポーネントをインストールする。
CDHのYumレポジトリの登録
HDFSとYARNのインストールにCDH5.4系を利用する。CDH5.4系パッケージのインストールのために、米Clouderaが提供しているYumリポジトリの登録をすべてのマシンに対して行う。
> sudo rpm --import

 archive.cloudera.com
RPM-GPG-KEY-cloudera
>sudo rpm -ivh
archive.cloudera.com
RPM-GPG-KEY-cloudera
>sudo rpm -ivh

続いて登録されたYumレポジトリの設定ファイル(/etc/yum.repos.d/cloudera-cdh5.repo)をroot権限で開き、次のようにCDH5.4系のリポジトリを参照するように編集する。
[clouderacdh5]
name=Cloudera’sDistributionfor
Hadoop,Version5
baseurl=http://archive.cloudera.com/cdh5
/redhat/6/x86_64/cdh/5.4/ ←5から5.4に修正する
gpgkey=

以降のインストール手順において確実にCDH5.4系のリポジトリを最少するため以下のコマンドを実行する。
> sudo yum clean allこれでYumレポジトリの登録が完了する。
マスターノードの構築
saprk-masterにName-nodeとResourceManagerをインストールする。はじめにNameNodeを以下のようにインストールする。
> sudo yum install -y hadoop-hdfs-namenode続いてResourceManagerをインストールする。
> sudo yum install -y hadoop-yarn-resourcemanagerワーカーノードの構築
次にspark-workerにDataNodeとNodeManagerをインストールする。はじめにDataNodeをインストールする。
> sudo yum install -y hadoop-hdfs-datanode次にNodeManagerをインストールする。
> sudo yum install -y hadoop-yarn-nodemanagerクライアントの構築
HDFSへのファイルの投入や参照を行ったり、HDFSとYARNの状態管理を行う為に前述のシングルクライアントのspark-clientにHDFSとYARNを操作する為のコンポーネントをインストールする。
> sudo yum install -y hadoop-hdfs hadoop-yarnまた$SPARK_HOME/confにspark-env.vshをrootユーザーてせ作成し、HDFSを利用する為の変数HADOOP_CONF_DIRを設定する。
HADOOP_CONF_DIR=/etc/hadoop/conf. ← この行を追加するHDFSとYARNの環境設定と動作確認
最後に必要なディレクトリの作成や設定ファイルなどの環境設定をすべてのマシンで行う。
/etc/hadoop/conf以下に配置されているcore-site.xml、hdfs-site.xml、yarn-site.xmlをそれぞれrootユーザー権限で以下のように編集する。
// core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://spark-masater:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>h/hadoop/tmp</value>
</property>
</configuration>// hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///hadoop/hdfs/data</value>
</property>
</configuration>// yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>spark-master</value>
</property>
<property>
<name>yarn.nodemanager.log-dir</name>
<value>file:///hadoop/yarn/nodemanager/logs</value>
</property>
<property>
<name>yarn.nodemanager.local-dir</name>
<value>file:///hadoop/yarn/node-manager</value>
</property>
</configuration>続いてHDFSやYARNの動作に必要なディレクトリをOS上に作成する。
> sudo mkdir /hadoop
> sudo mkdir /hadoop/hdfs
> sudo chown hdfs:hadoop /hadoop/hdfs
> sudo chmod 775 /hadoop/hdfs
> sudo mkdir /hadoop/yarn
> sudo chown yarn:hadoop /hadoop/yarn
> sudo chmod 775 /hadoop/yarn
> sudo mkdir /hadoop/tmp/
>sudo chmod 777 /hadoop/tmp通常のファイルシステムにフォーマットが必要なのと同様に、HDFSも構築直後はフォーマットが必要となる。
> sudo -u hdfs hdfs namenode -formatHDFS上にYARNが利用するディレクトリや、sparkが利用するディレクトリを作成する。はじめにHDFSを起動する。まずはspark-worker上でDataNodeを起動する。
> sudo service hadoop-hdfs-datanode start続いてspark-master上でNameNodeを起動する。
> sudo service hadoop-hdfs-namenode startNameNodeとDataNodeを起動したら、HDFSが起動したことを確認する。
> sudo -u hdfs hdfs dfsadmin -report上記コマンドを実行した結果、Safe mode is onと出力されていないこと、Live datanode(・)でDatanodeがすべて起動していることが確認できたらHDFSは正常に起動している。HDSFが起動したら、各種ディレクトリを作成する。
> sudo -u hdfs hdfs dfs -mkdir -p /hadoop/tmp > sudo -u hdfs hdfs dfs -chmod 777 /hadoop/tmp > sudo -u hdfs hdfs dfs -mkdir /tmp > sudo -u hdfs hdfs dfs -chmod 777 /tmp > sudo -u hdfs hdfs dfs -mkdir -p /hadoop/yarn/app-logs > sudo -u hdfs hdfs dfs -chmod 777 /hadoop/yarn/app-logs > sudo -u hdfs hdfs dfs -mkdir -p /user/<一般ユーザー名> > sudo -u hdfs hdfs dfs -chown <一般ユーザー名>:<一般ユーザー名>/user/<一般ユーザー名>
続いてYARNを起動する。はじめにspark-worker上でNodeMamanerを起動する。
> sudo service hadoop-yarn-nodemanager start続いて、spark-master上でResourceManagerを起動する。
> sudo service hadoop-yarn-resourcemanager startすべての起動を終えたらYARNが動作したことを確認する。
> sudo -u yarn yarn node -list -all上記コマンドを実行したのち、NodeManagerが全てRUNNINGのステータスになっていればYARNが動作している。
以上でSparkの動作に必要な環境構築が終了する。
次回はApache Sparkの活用としてアプリケーションの開発と実行について述べる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

コメント
[…] 分散データ処理を可能とするApache Sparkの導入と環境設定 […]
[…] 分散データ処理を可能とするApache Sparkの導入と環境設定 […]