[su_button url=”https://deus-ex-machina-ism.com/?page_id=3553″ target=”blank”]機械学習技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?page_id=3707″ target=”blank”]人工知能技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=283″ target=”blank”]自然言語処理技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=10″ target=”blank”]セマンティックウェブ技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=4613″ target=”blank”]オントロジー技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=26″ target=”blank”]検索技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=610″ target=”blank”]データベース技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=6622″ target=”blank”]アルゴリズム[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?page_id=3551″ target=”blank”]デジタルトランスフォーメーション技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=17486″ target=”blank”]Visualization & UX[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=18736″ target=”blank”]ワークフロー&サービス[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=26912″ target=”blank”]ITインフラ技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=26883″ target=”blank”]暗号化とセキュリティ技術およびデータ圧縮技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?p=31257″ target=”blank”]マイクロサービス技術[/su_button] [su_button url=”https://deus-ex-machina-ism.com/?page_id=12232″ target=”blank”]本ブログのナビ[/su_button]
サマリー
「Microservice with Clojure」より。前回はClojureでのAuthとPedestalを使ったAPIを使ったマイクロサービスでのセキュリティについて述べた。今回はマイクロサービスシステム運用監視の為のElasticStashの活用について述べる。
ここで述べた監視システムはマイクロサービスシステム以外にも広く適用可能となる。ElasticStashを用いた検索エンジンへの活用は”検索ツールElasticsearch -立ち上げ手順“等に詳細述べているのでそちらも参照のこと。
マイクロサービスの監視
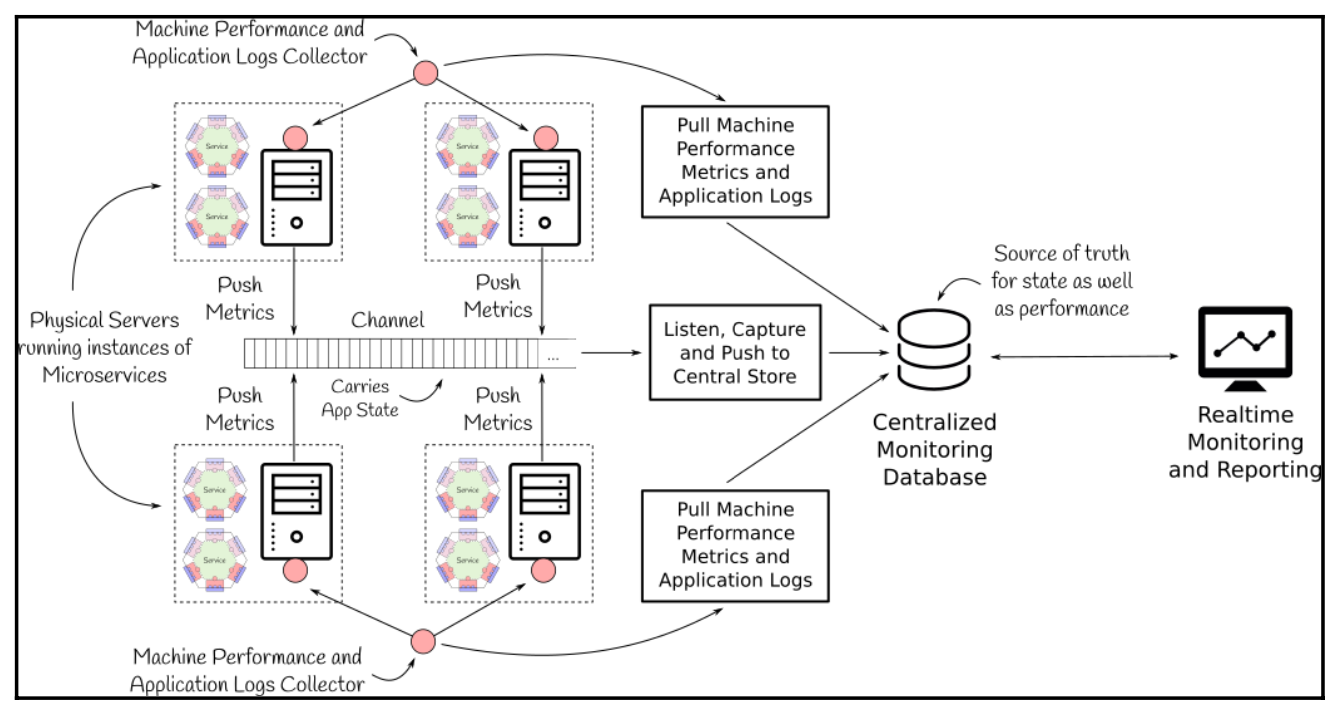
マイクロサービスベースのアプリケーションは、デプロイとスケーリングの面で非常に柔軟性がある。複数のサービスから構成され、ネットワーク上のマシンのクラスタ上で1つまたは複数のインスタンスが実行されている場合がある。このような高度に分散した柔軟な環境では、マイクロサービスの各インスタンスをリアルタイムで監視して、デプロイされたサービスやそのパフォーマンスを明確に把握し、問題が発生したらすぐに報告しなければならないような関心事を把握することが最も重要となる。マイクロサービスベースのアプリケーションへの各リクエストは、マイクロサービス間で1つまたは複数のリクエストに広がる可能性があるため、リクエストの流れを追跡し、根本原因の分析を行い、需要を満たすためにサービスをさらに拡大することで対処できるボトルネックの領域を特定するメカニズムが必要となる。

効果的な監視システムを構築する方法の1つは、前の図に示すように、サービスとマシンにまたがるすべてのメトリクスを収集し、集中型リポジトリに保存することとなる。この集中型リポジトリは、収集したメトリクスの分析をサポートし、関心のあるイベントに対してリアルタイムでアラートを生成するのに役立つ。また、一元化されたリポジトリは、システムのリアルタイム表示を設定して、各サービスの挙動を把握し、スケールアップするかスケールダウンするかを決定する際にも役立つ。アプリケーションに集中リポジトリを設定するには、すべてのサービスと物理マシンからメトリクスをプルするか、物理マシン上で動作するサービスから集中リポジトリにプッシュする必要がある。
すべてのサービスは、アプリケーションの状態に関連するメトリクスを、Apache Kafka などの共通のチャネルに、共通のトピックでプッシュする必要がある。このチャネルは、その後、サービス全体のすべてのアプリケーションレベルのメトリクスを集約して、集中型リポジトリに格納するために使用することができる。物理サーバー上のファイルに書き込まれたアプリケーションレベルのログや、JMXなどの媒体を通じて公開されたアプリケーションレベルのメトリクスは、外部のコレクターによって取り出され、後で中央のストレージにプッシュすることができる。インフラのパフォーマンスを監視するには、外部コレクターも物理マシンの統計情報を取得する必要がある。CPU使用率、ネットワークスループット、ディスクI/Oなどが含まれ、これも中央リポジトリにプッシュして、アプリケーションのサービス全体のリソース使用率を全体的に把握することができる。
ELK Stackをモニタリングに利用する
Elasticsearch、LogStash、Kibanaは、ELK Stack または Elastic Stack と呼ばれ、リアルタイム監視インフラを構築し、キャプチャ、プル、集中リポジトリへのプッシュ、レポートやアラートのための監視ダッシュボード構築に必要なすべてのコンポーネントを持っている。それらを用いてアプリケーションとマシンレベルのメトリックを集中レポーティに取り込んでプッシュするためのリアルタイム監視インフラを構築する。以下のモニタリング・インフラストラクチャー図は、ELK Stackの各コンポーネントがどのような位置づけにあるかを示している。Collectdと Apache Kafkaは ELK Stack の一部ではありませんが、ELK Stack はこれらとシームレスな統合を提供する。

Collectdは、CPU、メモリ、ディスク、ネットワークなど、マシンレベルのすべての統計情報をキャプチャするのに役立つ。キャプチャされたデータは、Logstashを介してプルされ、Elasticsearchにプッシュされる。
Elasticsearchにプッシュすることで、アプリケーションのサービスが使用するインフラの全体的なパフォーマンスと使用率を分析することができる。Logstashは、アプリケーション・ログの標準セットを理解し、マシン上で生成されたログ・ファイルからログ・イベントを引き出し、Elasticsearchクラスタにプッシュすることもできる。Logstashはまた、Apache Kafkaとうまく統合されており、サービスによって公開されたアプリケーションの状態イベントをキャプチャし、それらを直接Elasticsearchにプッシュするために使用することができる。Elasticsearch はすべてのログ、イベント、およびマシン統計の中央リポジトリとして機能するため、Kibana を Elasticsearch 上で直接使用して、保存されたメトリクスを分析し、Elasticsearch にイベントが到着すると同時にリアルタイムで更新されるダッシュボードを構築することが可能となる。また、Kibana を使用して根本的な原因分析を行い、意図した受信者にアラートを生成することも可能となる。
ELK Stackはモニタリングに便利ですが、それだけが唯一の選択肢ではない。Prometheusのようなツールもモニタリングに使用できます。Prometheusは、次元データモデル、柔軟なクエリ言語、効率的な時系列データベースをサポートし、アラーリングも内蔵している。
Elasticsearch のセットアップ
Elasticsearchの設定は、Elasticsearchのダウンロードページから最新版をダウンロードし、以下の例のように展開する。今回は、Elasticsearch 6.1.1を利用する。
# download elasticsearch 6.1.1 tar
> wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.1.1.ta r.gz
# extract the downloaded tarball
> tar -xvf elasticsearch-6.1.1.tar.gz
# make sure that these directories are present
> tree -L 1 elasticsearch-6.1.1
elasticsearch-6.1.1
├── bin
├── config
├── lib
├── LICENSE.txt ├── modules
├── NOTICE.txt ├── plugins
└── README.textile
5 directories, 3 files
Elasticsearch は、bin/elasticsearch コマンドですぐに実行できるが、 Elasticsearch クラスタを効果的に運用するために、以下の重要なコンフィグレー ションおよびシステム設定を確認することを推奨する。ES Config と表記されているものは、全ての Elasticsearch の導入に共通する設定であり、System Setting と表記されているものは、Linux オペレーティング・システム用の設定となる。環境変数-$ES_HOME-は、展開されたElasticsearchのインストールフォルダを指す。
環境変数-$ES_HOME-は、展開されたElasticsearchのインストールフォルダ、つまり、先のコードスニペットに示されたコマンドのelasticsearch-6.1.1を指す。


前の表に示したシステム設定の中には、それらを有効にするためにシステムの再起動を必要とするものがあることに注意が必要となる。また、スワップスペースの設定などは、ホストOS上でElasticsearchのみが動作している場合のみ行う必要がある。すべての設定が完了したら、以下のコマンドで各 Elasticsearch ノードを起動することができる。
# change to the extracted elasticsearch directory
> cd elasticsearch-6.1.1
# start elasticsearch
> bin/elasticsearchなお、最初に起動したノードは自動的にクラスタのマスターに選ばれる。
Elasticsearchノードが稼働したら、インスタンスをテストするために、Elasticsearchが稼働しているマシンのデフォルトの9200ポートにcURLを使用してGETリクエストを送信する(前出の例)。すると、ノードのバージョンを示すレスポンスが返ってくる。それが正しいバージョンであること、つまりこの例では6.1.1であることを確認する。
> curl http://localhost:9200
{
"name" : "W6r6s1z",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "g33pKv6XRTaj_yMJLliL0Q",
"version" : {
"number" : "6.1.1",
"build_hash" : "bd92e7f",
"build_date" : "2017-12-17T20:23:25.338Z", "build_snapshot" : false,
"lucene_version" : "7.1.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}前述の構成は、Elasticsearch の典型的なクラスタ展開について述べていたが、ElasticsearchにはCross Cluster Searchという概念もあり、任意のノードがElasticsearchの複数のクラスタにまたがる連携クライアントとして機能することも可能となる。
Kibanaのセットアップ
Kibanaは、Elasticsearchの可視化およびダッシュボードインターフェースで、Discoverモジュールを使用してデータを探索し、リアルタイムのダッシュボードを構築することができる。可視化オプションも充実しており、Elasticsearch内に保存されているデータを集約し、ライン、バー、エリア、マップ、タグクラウドなど、様々なチャートを使って可視化することが可能となる。Kibanaを利用することで、Elasticsearch内に取り込まれた様々なメトリクスを利用した監視ダッシュボードを構築することができる。
Kibanaの設定は、Kibanaのダウンロードページから最新版をダウンロードし、以下の例のように展開します。本書ではKibana 6.1.1を使用する。
# download Kibana 6.1.1 tar
> wget https://artifacts.elastic.co/downloads/kibana/kibana-6.1.1-linux-x86_64.tar .gz
# extract the downloaded tarball
> tar -xvf kibana-6.1.1-linux-x86_64.tar.gz
# make sure that these directories are present
> tree -L 1 kibana-6.1.1-linux-x86_64
kibana-6.1.1-linux-x86_64
├── bin
├── config
├── data
├── LICENSE.txt ├── node
├── node_modules ├── NOTICE.txt ├── optimize ├── package.json ├── plugins ├── README.txt ├── src
├── ui_framework └── webpackShims
10 directories, 4 files
次に、Kibanaインスタンスの設定として、$KIBANA_HOME/config/kibana.ymlファイルに以下の設定パラメータを設定する。KIBANA_HOME/config/kibana.yml ファイルに設定する。環境変数$KIBANA_HOMEは、解凍したKibanaのインストールフォルダ、つまり、kibana-6.1.1-linux-xmlを指する。kibana-6.1.1-linux-x86_64(前のコードスニペットで示したコマンドの場合)となる。

すべての設定が完了したら、次の例に示すコマンドでKibanaを起動する。前の表にあるように、Elasticsearchがすでに稼働しており、設定されたelasticsearch.urlの設定でKibanaノードにアクセスできることを確認する。
# change to extracted kibana directory
> cd kibana-6.1.1-linux-x86_64
# start kibana
> bin/kibana
Kibanaが起動したら、ブラウザでURL http://localhost:5601にアクセスし、次のスクリーンショットに示すように、Kibanaインターフェースを開く。データを視覚化して探索するためのオプションを備えたKibanaのホームページが表示される。

Kibana の現在の構成では、ユーザーは閉じたネットワークで Elasticsearch を探索することができる。Kibana は基礎となる Elasticsearch クラスターとその中に保存されているデータを完全に制御するため、ユーザーが接続してダッシュボードにアクセスするには、SSLと、本番構成で定義されているロードバランシングオプションを有効にすることが推奨される。
Logstashのセットアップ
Logstashは、ログメッセージの収集、パース、変換を可能にする。これは、Logstashがさまざまなソースからログを収集し、それらをパースおよび変換し、サポートされているプラグインのいずれかに結果を書き込むことができるように、多くの入力よび出力プラグインをサポートしています。Logstashをセットアップするには、Logstashダウンロードページから最新バージョンをダウンロードし、次のコードスニペットに示すように展開する。今回はLogstash 6.1.1を利用する。
# download Logstash 6.1.1 tar
> wget https://artifacts.elastic.co/downloads/logstash/logstash-6.1.1.tar.gz
# extract the downloaded tarball
> tar -xvf logstash-6.1.1.tar.gz
# make sure that these directories are present
> tree -L 1 logstash-6.1.1
logstash-6.1.1
├── bin
├── config
├── CONTRIBUTORS ├── data
├── Gemfile
├── Gemfile.lock
├── lib
├── LICENSE
├── logstash-core
├── logstash-core-plugin-api ├── modules
├── NOTICE.TXT
├── tools
└── vendor
9 directories, 5 files
次の表は、Logstashに必要な主要構成設定の一覧となる。環境変数-$LOGSTASH_HOME-は、展開されたLogstashのインストールフォルダ、つまり、前のコードスニペットに示されたコマンドのlogstash-6.1.1を指す。


前の表は、主要な構成パラメータのみをリストアップしている。詳細とサポートされているすべての構成パラメータについては、Logstash設定ファイルガイドを参照のこと。すべての設定が完了したら、以下のように入力プラグインとしてstdinを使用してメッセージを受信し、出力プラグインとしてstdout を使用して受信メッセージを出力するサンプル Logstashパイプラインをテストする。
# change to extracted logstash directory
> cd logstash-6.1.1
# start logstash pipeline by specifying the configuration
# at command line using the -e flag
> bin/logstash -e 'input { stdin { } } output { stdout {} }'Logstashはパイプラインを開始するのに数秒かかることがあるので、Pipelineの実行メッセージがログに記録されるのを待つ。パイプラインが実行されたら、コンソールにメッセージを入力すると、Logstashは現在のタイムスタンプとホスト名を付加して同じものをコンソール上にエコーする。これは変換を行わない非常にシンプルなパイプラインだが、Logstashでは受信したメッセージに対して、シンクに出力する前に変換を適用することが可能となる。先のテストで示した基本的なパイプラインと同様に、ログ、イベント、データを取得し、ターゲットシンクに格納するためにLogstashが実行する必要があるパイプラインごとにLogstashパイプライン構成を作成する。
Logstashのプラグインは主にRubyで実装されている。そのため、Logstashのジョブ設定ファイルや変換コンストラクトはすべてRubyの構文が使われている。
ELK StackとCollectdの併用
Collectdは、Logstashなどの様々なソースプラグインからメトリクスを収集するための設定を行うことができるデーモンとなる。Logstashと比較するとCollectdは非常に軽量でポータブルだが、グラフを生成する機能は持たない。しかし、RRDファイルへの書き込みは可能で、RRDTool を使って読み込み、グラフを生成してログされたデータを可視化することができる。一方、CollectdはC言語で書かれているので、組み込みシステムからのメトリクス収集にも使用することが可能となる。
Collectdはソースからビルドする必要がある。まず、Collectd 5.8.0をダウンロードし、解凍する。
# download Collectd 5.8.0 tar
> wget https://storage.googleapis.com/collectd-tarballs/collectd-5.8.0.tar.bz2
# extract the downloaded tarball
> tar -xvf collectd-5.8.0.tar.bz2
# make sure that these directories are present
> tree -L 1 collectd-5.8.0
collectd-5.8.0
├── aclocal.m4
├── AUTHORS
├── bindings
├── build-aux
├── ChangeLog
├── configure
├── configure.ac
├── contrib
├── COPYING
├── m4
├── Makefile.am
├── Makefile.in
├── proto
├── README
├── src
├── testwrapper.sh └── version-gen.sh
6 directories, 11 files
次に、以下の例に示すように、Collectd をビルドディレクトリにインストールする。configureスクリプトが足りない依存関係を要求する場合は、CollectdのFirst steps wiki に従って、セットアップを続ける前にそれらをインストールする。
# change to extracted collectd directory
> cd collectd-5.8.0
# configure the target build directory
# give the fully qualified path as prefix
# $COLLECTD_HOME points to collectd-5.8.0 directory
> ./configure --prefix=$COLLECTD_HOME/build
# install collectd
> sudo make all install
# verify the build directories
> tree -L 1 build
build
├── bin
├── etc
├── include
├── lib
├── man
├── sbin
├── share
└── var
8 directories, 0 files
# own the entire collectd directory
# replace with your username
> sudo chown -R : .
Collectd のインストールが完了したら、次のステップでは build/etc/collectd.conf ファイルを更新し、必要な設定とプラグインを追加する。以下は、cpu、df、interface、network、memory、syslog、load、swap プラグインを有効にする collectd.conf ファイルのサンプルとなる。利用できるプラグインとその設定の詳細については、Collectd Table of Pluginsを参照のこと。
# Base Configuration
# replace all paths below with fully qualified
# path to the extracted collectd-5.8.0 directory
Hostname "helpinghands.com"
BaseDir "/collectd-5.8.0/build/var/lib/collectd"
PIDFile "/collectd-5.8.0/build/var/run/collectd.pid"
PluginDir "/collectd-5.8.0/build/lib/collectd"
TypesDB "/collectd-5.8.0/build/share/collectd/types.db"
CollectInternalStats true
# Syslog
Load
<Plugin syslog>
LogLevel info
</Plugin>
# Other plug-ins
LoadPlugin cpu
LoadPlugin df
LoadPlugin disk
LoadPlugin interface
LoadPlugin load
LoadPlugin memory
LoadPlugin network
LoadPlugin swap
# Plug-in Config
<Plugin cpu>
ReportByCpu true
ReportByState true
ValuesPercentage false
</Plugin>
# replace device and mount point
# with the device to be monitored
# as shown by df command
<Plugin df>
Device "/dev/sda9"
MountPoint "/home"
FSType "ext4"
IgnoreSelected false
ReportByDevice false
ReportInodes false
ValuesAbsolute true
ValuesPercentage false
</Plugin>
<Plugin disk>
Disk "/^[hs]d[a-f][0-9]?$/"
IgnoreSelected false
UseBSDName false
UdevNameAttr "DEVNAME"
</Plugin>
# report all interface except lo and sit0
<Plugin interface>
Interface "lo"
Interface "sit0"
IgnoreSelected true
ReportInactive true
UniqueName false
</Plugin>
<Plugin load>
ReportRelative true
</Plugin>
<Plugin memory>
ValuesAbsolute true
ValuesPercentage false
</Plugin>
# sends metrics to this port i.e.
# configured in logstash to receive
# the log events to be published
<Plugin network>
Server "127.0.0.1" "25826"
<Server "127.0.0.1" "25826">
</Plugin>
<Plugin swap>
ReportByDevice false
ReportBytes true
ValuesAbsolute true
ValuesPercentage false
</Plugin>設定ファイルを配置したら、このようにCollectdデーモンを起動する。
# start collectd daemon with sudo
# some plug-ins require sudo access % sudo build/sbin/collectd
# make sure it is running
> ps -ef | grep collectd
# verify syslog to make sure that collectd is up
> tail -f /var/log/syslog次に、Logstashのパイプラインの設定ファイルを作成する。ファイル $LOGSTASH_HOME/config/helpinghands.confを作成し、Collectd Codecプラグインを使って Collectdからデータを受け取り、その出力プラグインでElasticsearch にデータを送信するようにする。
input {
udp {
port => 25826
buffer_size => 1452
codec => collectd {
id => "helpinghands.com-collectd"
typesdb => [ "/collectd-5.8.0/build/share/collectd/types.db" ]
}
}
}
output {
elasticsearch {
id => "helpinghands.com-collectd-es"
hosts => [ "127.0.0.1:9200" ]
index => "helpinghands.collectd.instance-%{+YYYY.MM}"
}
}次に、Logstashのパイプラインを実行して、CollectdプロセスからUDPでデータを受信しElasticsearchに送信する。上記UDPの設定で指定した25826ポートが、Collectdの設定のネットワークプラグインのポートと一致することを、Logstashを実行する前に確認し、ElasticsearchとCollectdの両方が起動していることを確認する。
# change to $LOGSTASH_HOME directory and run logstash
> bin/logstash -f config/helpinghands.confLogstashが起動したら、Elasticsearchのログを観察すると、LogstashのElasticsearch出力プラグインで設定したhelpinghands.collectd.instance-%{+YYYY.MM}パターンに基づいて新しいインデックスが作成されたことがわかる。インデックス名は、現在の月と年によって異なることに注意が必要となる。時系列データセットを格納するインデックスには、時間ベースのインデックスパターンを維持することが推奨される。これはクエリーのパフォーマンスに役立つだけでなく、組織のデータ保持ポリシーに基づくバックアップとクリーンアップにも役立つ。以下は、LogstashがCollectdから取得したデータに対して必要なインデックスが正常に作成された場合に、Elasticsearchのログファイルで確認できるログメッセージとなる。
[2018-01-16T02:04:12,054][INFO ][o.e.c.m.MetaDataCreateIndexService]
[W6r6s1z] [helpinghands.collectd.instance-2018.01] creating index, cause
[auto(bulk api)], templates [], shards [5]/[1], mappings []
[2018-01-16T02:04:15,259][INFO ][o.e.c.m.MetaDataMappingService] [W6r6s1z]
[helpinghands.collectd.instance-2018.01/9x0mla-mS0akJLuuUJELZw] create_mapping [doc]
[2018-01-16T02:04:15,279][INFO ][o.e.c.m.MetaDataMappingService] [W6r6s1z]
[helpinghands.collectd.instance-2018.01/9x0mla-mS0akJLuuUJELZw]
update_mapping [doc]
[2018-01-16T02:04:15,577][INFO ][o.e.c.m.MetaDataMappingService] [W6r6s1z]
[helpinghands.collectd.instance-2018.01/9x0mla-mS0akJLuuUJELZw]
update_mapping [doc]
[2018-01-16T02:04:15,712][INFO ][o.e.c.m.MetaDataMappingService] [W6r6s1z]
[helpinghands.collectd.instance-2018.01/9x0mla-mS0akJLuuUJELZw]
update_mapping [doc]
[2018-01-16T02:04:15,922][INFO ][o.e.c.m.MetaDataMappingService] [W6r6s1z]
[helpinghands.collectd.instance-2018.01/9x0mla-mS0akJLuuUJELZw]
update_mapping [doc]パイプラインを実行させ、Collectd-Logstash-Elasticsearchパイプラインで取得したマシンメトリクスを保存する。ここで、URL http://localhost:5601 を使ってブラウザで Kibana インターフェイスを開き、右上の Set up index patterns ボタンをクリックする。以下のスクリーンショットのように、新しく作成されたインデックス helphands.collectd.instance-2018.01 が自動的にリストアップされる。

前のスクリーンショットに示すように、インデックスパターン helphands.collectd.instance-* を追加し、Collectd で取得したメトリクス用に作成されたすべてのインデックスを含める。右側の[Next step]ボタンをクリックし、次のスクリーンショットに示すように、[Time filter field name]を[@timestamp]に選択する。

次に、先のスクリーンショットに示すように、Create index patternボタンをクリックする。Kibana が Elasticsearch のインデックスマッピングから取得できたフィールドのリストが表示される 。ここで、左側のメニューにある「Discover」をクリックすると、次のスクリーンショットに示すように、キャプチャされているすべてのメッセージのリアルタイム・ダッシュボードが表示される。

Discover画面の左側のパネルには、キャプチャされているすべてのフィールドが一覧表示される。例えば、ホストとプラグインのフィールドをクリックすると、以下のスクリーンショットのように、Collectdによってデータがキャプチャされ、Logstashパイプラインを介してElasticsearchに送信された、監視対象のホストとすべてのプラグインを確認することができる。

Kibanaダッシュボードでは、さまざまな可視化オプションでダッシュボードを構築できる。例えば、Collectdが監視を開始してからのCPU使用率を見るには、以下の手順を実行する。
- Kibanaアプリケーションの左パネルにある「Visualize」をクリックする。
- Create a visualization ボタンをクリックする。
- Line をクリックして、折れ線グラフを選択
- 左側のセクションから、index helpinghands.collectd.instance-* パターンを選択する。
- 上部の検索バーの下にある「Add a filter +」オプションをクリックする。
- plugin.keyword is cpuとしてフィルタを選択し、保存する。
- Y軸をクリックし、AggregationをAverageに変更する。
- フィールドをValueに選択
- 次に、X軸の「Buckets」をクリックする。
- 集計を「日付ヒストグラム」にする。
- デフォルトで@timestampフィールドが選択されている。
- 間隔をAutoにする
- Metricsパネルの上部にある、変更を適用する再生アイコンをクリックする。
- 次のスクリーンショットに示すように、右側にチャートが表示される。
- チャートエリアの下にある矢印アイコンをクリックすると、表が表示される

これらの手順を実行すると、上のスクリーンショットに示すように、過去15分間(デフォルト)のCPU使用率の経時変化を見ることができる。作成した可視化機能は保存し、後でダッシュボードに追加して、取り込んだすべてのメトリクスをリアルタイムで監視する本格的なダッシュボードを構築することができる。
ログ収集と監視のガイドライン
マイクロサービスでは、ELK Stackで取得可能なアプリケーションログと監査ログの両方を生成する必要がある。アプリケーションログは、標準のlog4jスタイルの構文でメッセージを記録するClojure の tools.logging ライブラリを使用してサービスによって生成することができる。Logstashは一般的なロギングフォーマットのほとんどでうまく動作するが、代わりに構造化ロギングを使用することが推奨される。
構造化されたログは、Logstashのようなツールを使って、一元化されたリポジトリ内で解析し、ロードすることが容易になる。timbre などのライブラリは、構造化されたログをサポートし、ファイルにログを記録する代わりに、リモートサービスに直接ログを公開することも可能となる。構造化ロギングに加えて、次の表に示すように、ログメッセージ内に事前定義された標準タグを含めることも必要となる。

タグは、関心のあるサービスから発生するログメッセージをフィルターするのに特に有用で、また、起動時、シャットダウン時、または例外の結果として記録されたログメッセージなど、特定の状態レベルのタグを介してログをさらに掘り下げるのに役立つ。
タグに加えて、ログメッセージを生成している間、常に UTC を使用することも推奨される。これらのログメッセージはすべて一元管理されたリポジトリに集約されるため、タイムゾーンが異なると、異なるタイムゾーンで動作している可能性のあるホストマシンのタイムゾーンのために同期が取れなくなり、分析が困難になる。
ログメッセージは問題をデバッグし、アプリケーションの状態に関する情報を提供するのに非常に有用だが、アプリケーションのパフォーマンスに大きく影響する。そのため、できるだけ非同期で、慎重にログを記録する必要がある。また、ディスクI/Oを必要とするファイルにログを記録するのではなく、Apache Kafkaなどのチャネルに非同期でログイベントを発行することが推奨される。LogstashにはKafka用の入力プラグインがあり、Kafkaトピックからイベントを読み込んで、Elasticsearchのような対象の出力プラグインにパブリッシュすることが可能となる。
Riemann は、ELK スタックの代替品となる。マイクロサービスベースのアーキテクチャに基づくものなど、分散システムを監視するために使用される。Riemann は非常に高速で、ロールアップとスロットル構造 を使って、受信者を圧倒することなくほぼリアルタイムでアラートを生成することが可能となる。
次回はマイクロサービスのデプロイと運用としてDockerとKubernetesについて述べる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
