Self Refine
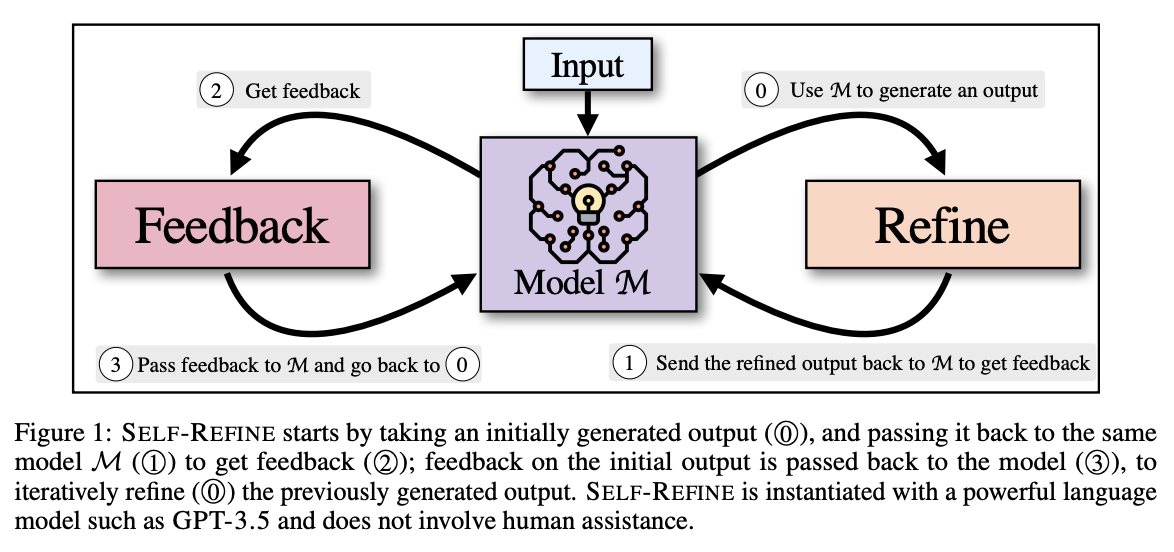
“GPT-4以上? 自分で何度も“推敲”し完成度を上げる言語生成AI「Self-Refine」“では米カーネギーメロン大学、Allen Institute for Artificial Intelligence、米ワシントン大学、米NVIDIA、米UC San Diego、米Google Researchに所属する研究者らが発表した論文「Self-Refine: Iterative Refinement with Self-Feedback」において、大規模言語モデル(LLM)が、より高品質な出力を生成するために、反復的な改良と自己評価を利用することを可能にする新しいフレームワークを提案したことが述べられている。
人間の問題解決の基本的な特徴である反復的な改良は、最初に草案を作成し、その後自己フィードバックによって改良するプロセスである。例えば、メールの文章でも何度も校正を行い、推敲することで仕上げるステップを持つ。
この研究では、LLMが反復的なフィードバックと改良を行うフレームワーク「Self-Refine」を提案することで、このような人間の認知プロセスを効果的に再現できるかを検証している。このアプローチは、先行研究とは異なり、教師ありの訓練データや強化学習を必要とせず、単一のLLMを使用する。
Self-Refineは、FeedbackとRefineの2つのコンポーネントによる反復ループで構成し、これらのコンポーネントが連携して高品質なアウトプットを生成する。モデルが生成した最初の出力案があると、それをFeedbackとRefineの2つのコンポーネントを何度も行き来し、何度も繰り返し改良する。このプロセスは、指定された回数、あるいはモデル自身がこれ以上の改良は必要ないと判断するまで、繰り返し行われる。

具体的には、初期出力を与えると、Feedbackはそれを評価し、修正に必要な実行可能なフィードバックを生成する。Refineは、そのフィードバックを考慮してアウトプットを改良する。これらを繰り返す。
実験では、物語生成やコードの最適化、略語生成など7つのタスクで大規模なテストを行い、結果、Self-RefineがGPT-3.5やGPT-4などの強力な生成器からの直接生成よりも少なくとも5%、最大で40%以上向上することを示されている。
以下にSelf Refineについてまとめてみる。
Self Refineに関連するアルゴリズム
人工知能技術における「self refine」機能に関連するアルゴリズムは、自己改善や反復的な学習を通じてモデルの性能を向上させることを目的としている。以下は、そのようなアルゴリズムのいくつかの例となる。
1. 再帰的ニューラルネットワーク (Recurrent Neural Network, RNN): “RNNの概要とアルゴリズム及び実装例について“で述べているRNNは、連続データを扱うのに適しており、特に時系列データや自然言語処理において効果的なアプローチとなる。RNNは過去の出力を現在の入力に反映させることで、自己改善を行っている。
2. 確率的勾配降下法 (Stochastic Gradient Descent, SGD): “確率的勾配降下法(Stochastic Gradient Descent, SGD)の概要とアルゴリズム及び実装例について“で述べているSGDは、モデルのパラメータを更新するために使用される最適化アルゴリズムとなる。データセット全体ではなく、小さなバッチでパラメータを更新することで、計算コストを削減し、モデルの収束を早めている。以下はSGDの基本的な手順となる。
import numpy as np
def stochastic_gradient_descent(X, y, theta, learning_rate=0.01, epochs=100):
m = len(y)
for epoch in range(epochs):
for i in range(m):
rand_index = np.random.randint(0, m)
xi = X[rand_index:rand_index+1]
yi = y[rand_index:rand_index+1]
gradients = 2 * xi.T.dot(xi.dot(theta) - yi)
theta = theta - learning_rate * gradients
return theta3. 自己注意機構 (Self-Attention Mechanism): “深層学習におけるattentionについて“で述べている自己注意機構は、Transformerアーキテクチャの一部として広く使われている。これは、入力シーケンス内の異なる部分間の関係をモデル化し、重要な情報に焦点を当てることができ、自己注意機構は、BERTやGPTなどのモデルで利用されている。
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out4. 強化学習 (Reinforcement Learning): “強化学習技術の概要と各種実装について“で述べている強化学習は、エージェントが環境との相互作用を通じて報酬を最大化するための方策を学習する方法で、Q-ラーニングやポリシーグラディエント法などのアルゴリズムが含まれている。
import numpy as np
class QLearningAgent:
def __init__(self, state_size, action_size, learning_rate=0.1, discount_factor=0.99, exploration_rate=1.0, exploration_decay=0.995):
self.state_size = state_size
self.action_size = action_size
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.exploration_rate = exploration_rate
self.exploration_decay = exploration_decay
self.q_table = np.zeros((state_size, action_size))
def choose_action(self, state):
if np.random.rand() <= self.exploration_rate:
return np.random.choice(self.action_size)
return np.argmax(self.q_table[state])
def learn(self, state, action, reward, next_state):
best_next_action = np.argmax(self.q_table[next_state])
td_target = reward + self.discount_factor * self.q_table[next_state][best_next_action]
td_error = td_target - self.q_table[state][action]
self.q_table[state][action] += self.learning_rate * td_error
self.exploration_rate *= self.exploration_decay5. メタラーニング (Meta-Learning): “Few-shot/Zero-shot Learningにも活用可能なMeta-Learnersの概要と実装例“や”Meta-Learnersを用いた因果推論の概要とアルゴリズム及び実装例“でも述べているメタラーニングは、「学習の学習」として知られ、モデルが新しいタスクに迅速に適応できるように学習している。MAML(Model-Agnostic Meta-Learning)はその代表的なアルゴリズムとなる。
import torch
class MAML:
def __init__(self, model, inner_lr, outer_lr, inner_steps):
self.model = model
self.inner_lr = inner_lr
self.outer_lr = outer_lr
self.inner_steps = inner_steps
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.outer_lr)
def inner_update(self, loss):
grads = torch.autograd.grad(loss, self.model.parameters(), create_graph=True)
updated_params = [param - self.inner_lr * grad for param, grad in zip(self.model.parameters(), grads)]
return updated_params
def outer_update(self, meta_loss):
self.optimizer.zero_grad()
meta_loss.backward()
self.optimizer.step()これらのアルゴリズムは、self refineのプロセスをサポートし、AIシステムが時間とともに自己改善するのに役立てられている。
Self Refineの適用事例
人工知能技術における「self refine」機能の具体的な適用事例として、以下のようなものが挙げられる。これらの事例は、AIシステムが自身の出力を評価し、改善するための反復的なプロセスを通じて、より正確で信頼性の高い結果を提供することを目指している。
1. 自然言語処理における文章生成:
GPTモデルによる自己改善:
– 適用例: OpenAIのGPT-3やGPT-4のような大規模言語モデルは、自己改善のプロセスを通じて、より一貫した、文法的に正しい、意味の通る文章を生成する。
– 方法:
1. 初期出力の生成: 入力テキストに基づいて初期の出力を生成する。
2. 評価: 生成された出力を評価し、特定の基準に基づいてスコアを付ける(例えば、文法チェック、意味の一貫性など)。
3. 再生成: 低評価の場合、モデルにフィードバックを与え、出力を再生成する。
4. 最終出力の確定: 高評価の出力を最終結果として選択する。
2. 画像認識における精度向上:
自動ラベル修正:
– 適用例: 画像認識システムにおいて、初期の予測結果を自己評価し、ラベルの精度を向上させる。
– 方法:
1. 初期予測: 画像に対して初期の予測を行う。
2. 評価: 予測結果を信頼度スコアに基づいて評価する。
3. 修正: 低信頼度の予測に対しては、前処理(例えば、画像の明るさやコントラストの調整)を変更し、再予測を行う。
4. 最終予測の確定: 高信頼度の予測を最終結果として選択する。
3. 強化学習におけるポリシー改善:
Qラーニングによるポリシー最適化:
– 適用例: 強化学習エージェントがゲームのプレイ戦略を自己改善する。
– 方法:
1. 初期ポリシーの生成: 初期のポリシーに基づいて行動を選択する。
2. 評価: 各行動に対する報酬を評価し、Q値を更新する。
3. ポリシーの修正: Q値に基づいて、より良い行動を選択するポリシーに修正する。
4. 反復: このプロセスを複数回繰り返し、ポリシーを最適化する。
4. メタラーニングによる新しいタスクへの適応:
MAMLによるモデル適応:
– 適用例: 新しいタスクに迅速に適応する必要があるアプリケーション(例:新しい種類の画像分類)。
– 方法:
1. 内側の更新: 新しいタスクに対してモデルを迅速に調整するための内側の更新を行う。
2. 評価: タスクに対するパフォーマンスを評価する。
3. 外側の更新: メタラーニングアルゴリズムに基づいて、全体的なモデルパラメータを更新する。
4. 反復: このプロセスを複数回繰り返し、モデルを新しいタスクに適応させる。
5. 自動運転車における経路計画:
自己評価による経路最適化:
– 適用例: 自動運転車が経路計画を自己改善し、安全かつ効率的な走行を実現する。
– 方法:
1. 初期経路の計画: 現在の状況に基づいて初期の経路を計画する。
2. 評価: 経路の安全性や効率性を評価する(例えば、交通量、道路状況、予測時間など)。
3. 再計画: 低評価の経路に対しては、新しい情報を考慮して再計画を行う。
4. 最終経路の選択: 高評価の経路を最終的な走行経路として選択する。
これらの事例は、self refineの具体的な適用方法を示しており、各分野でAIの性能を向上させるために利用されている。
Self Refineの実装例
人工知能技術における「self-refine」機能の実装例としては、以下のような方法がある。この機能は、AIモデルが自身の出力を評価し、改善するための反復的なプロセスを通じて、より正確で信頼性の高い結果を提供することを目指している。
自然言語処理におけるself-refineの実装例:
初期出力生成:入力データに基づいて初期の出力を生成する。
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
input_text = "人工知能技術におけるself refineの実装例を教えてください。"
inputs = tokenizer.encode(input_text, return_tensors='pt')
outputs = model.generate(inputs, max_length=100)
initial_output = tokenizer.decode(outputs[0], skip_special_tokens=True)出力の評価:生成された出力を評価し、特定の評価基準に基づいてスコアを付ける。
def evaluate_output(output_text):
# ここでは仮の評価関数として、文字数をスコアとして使用
return len(output_text)
score = evaluate_output(initial_output)出力の修正:評価結果をもとに出力を修正する。たとえば、特定の基準に基づいて出力を再生成する、または修正点を反映する。
refined_output = initial_output
while score < threshold:
refined_output = model.generate(tokenizer.encode(refined_output, return_tensors='pt'), max_length=100)
refined_output = tokenizer.decode(refined_output[0], skip_special_tokens=True)
score = evaluate_output(refined_output)
最終出力の確定:修正を繰り返した後、最も高い評価を得た出力を最終結果として確定する。
final_output = refined_output
print(final_output)画像認識におけるself-refineの実装例:
初期予測:入力画像に対して初期の予測を行う。
import torch
from torchvision import models, transforms
from PIL import Image
model = models.resnet18(pretrained=True)
model.eval()
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_image = Image.open("path_to_image.jpg")
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
initial_output = model(input_batch)出力の評価:予測結果に対して評価基準を適用し、スコアを計算する。
def evaluate_output(output):
# 仮の評価関数として、確信度の高い予測のスコアを使用
return torch.max(output).item()
score = evaluate_output(initial_output)出力の修正:確信度が低い場合、画像前処理を変更して再予測する。
while score < threshold:
# 例えば、画像のコントラストを変更して再処理
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ColorJitter(contrast=2.0), # コントラストを調整
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
refined_output = model(input_batch)
score = evaluate_output(refined_output)
最終予測の確定:修正を繰り返した後、最も高い評価を得た予測を最終結果として確定する。
final_output = refined_output
print(final_output)self refineの課題と対応策
人工知能技術における「self refine」機能には、いくつかの課題が存在する。以下に主要な課題とその対応策を示す。
1. 訓練データのバイアス:
課題: 訓練データに存在するバイアスが、self refineプロセスを通じて増幅され、出力結果に偏りが生じる可能性がある。
対応策:
– データの多様性確保: 訓練データを多様かつバランスの取れたものにする。
– バイアス検出と修正: データの前処理段階でバイアスを検出し、修正するための手法を導入する。
– アクティブラーニング: ユーザーや専門家のフィードバックを活用して、データセットを継続的に改善する。詳細は”機械学習におけるアクティブラーニング技術について“も参照のこと。
2. オーバーフィッティング:
課題: モデルが訓練データに過剰に適応し、汎化性能が低下する。
対応策:
– 正則化手法: L1/L2正則化やドロップアウトなどの手法を用いて、モデルの複雑さを抑制する。
– クロスバリデーション: データを分割してクロスバリデーションを行い、モデルの汎化性能を評価する。
– データ拡張: データセットを増やすためにデータ拡張技術を使用し、オーバーフィッティングを防ぐ。
3. 計算コストの増大:
課題: self refineプロセスは計算リソースを大量に消費し、処理時間が長くなる。
対応策:
– 効率的なアルゴリズム: 計算コストの低いアルゴリズムを選定し、最適化を行う。
– 分散処理: クラウドコンピューティングやGPUクラスタを利用して、計算を分散処理する。
– インクリメンタルラーニング: 新しいデータに対してのみモデルを再訓練するインクリメンタルラーニングを活用する。
4. フィードバックループの不安定性:
課題: 自己評価と改善のループが不安定になることがあり、モデルの収束が難しくなる。
対応策:
– フィードバック制御: フィードバックループに適切な制御を導入し、安定した収束を確保する。
– 適応的学習率: 学習率を動的に調整することで、安定した学習を実現する。
– エラーチェックポイント: 各ステップでのエラーを監視し、改善の方向性を調整する。
5. 不確実性の扱い:
課題:モデルが出力する結果に対する不確実性を適切に評価し、扱うことが難しい。
対応策:
– ベイズアプローチ: ベイズ推定を用いて、出力の不確実性を明示的にモデル化する。
– アンサンブル学習: 複数のモデルを組み合わせることで、個々のモデルの不確実性を相殺し、より信頼性の高い結果を得る。
– 確信度スコア: 各予測に対して確信度スコアを計算し、不確実性の高い予測には注意を払う。
6. スケーラビリティ:
課題: 大規模なデータセットや複雑なモデルに対してself refineを適用する際のスケーラビリティの問題がある。
対応策:
– 分散学習: データや計算を分散させて、大規模なデータセットに対する学習を効率化する。
– 効率的なデータ処理: データの前処理やフィルタリングを効率的に行い、必要な部分のみをself refineプロセスに投入する。
– ハードウェアの活用: 高性能なハードウェアや専用のアクセラレータ(例:TPU、FPGA)を活用して、計算効率を向上させる。
参考情報と参考図書
機械学習による自動生成に関しては”機械学習による自動生成“に詳細を述べている。そちらも参照のこと。
参考図書としては“機械学習エンジニアのためのTransformer ―最先端の自然言語処理ライブラリによるモデル開発“

“

“

“Reinforcement Learning: An Introduction“ by Richard S. Sutton and Andrew G. Barto
“Deep Learning“ by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
“The Fifth Discipline: The Art and Practice of the Learning Organization“ by Peter M. Senge
“Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation“ by Jez Humble and David Farley
“Atomic Habits: An Easy & Proven Way to Build Good Habits & Break Bad Ones“ by James Clear

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
