人工知能技術 ウェブ技術 知識情報処理技術 セマンティックウェブ技術 自然言語処理 機械学習技術 オントロジー技術 オントロジーマッチング技術
前回に引き続きオントロジーマッチングより。前回はアライメントの抽出について述べた。今回はアライメントの曖昧性改善について述べる。
アライメントの改善
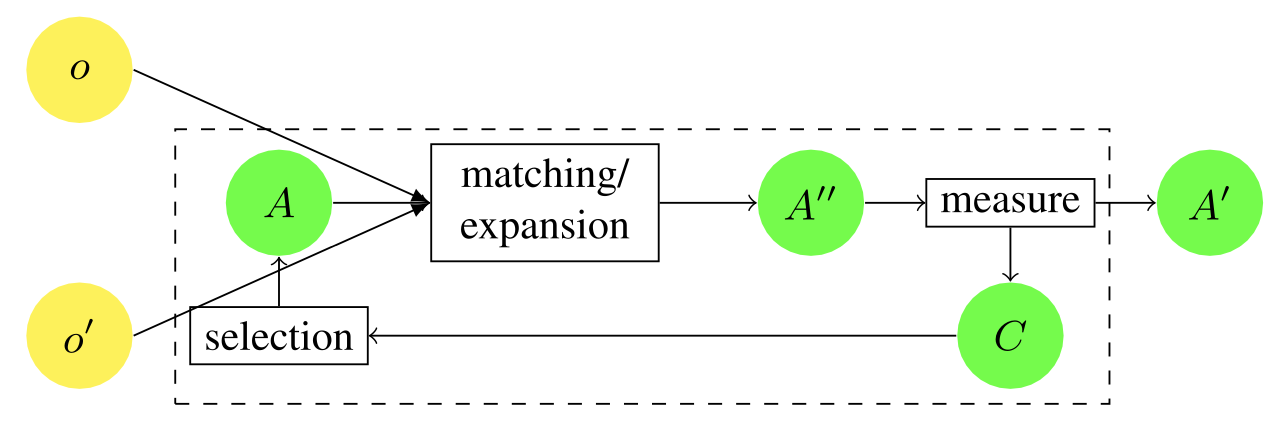
アライメントの改善とは、生成されたアライメントの品質を測定し、品質が向上するようにアライメントを縮小し、場合によっては結果のアライメントを拡大することを繰り返すこととなる。一般的な改善プロセスを下図に示す。最初のアラインメントの縮小にはいくつかの可能性があるため、使用するものを選択する必要がある。測定値が特定の閾値に達すると、このプロセスの結果としてアライメントが選択される。選択されたアライメントがマッチャーにフィードバックされるのではなく、 直接出力として提供される場合、改善はアライメントフィルターとして機能する。

一般的なアライメント改善のフレームワーク。最初のアラインメント(A′′)はマッチャーによって生成される。これを固有の尺度(一貫性、一致性、制約違反)に基づいて評価し、互換性のあるサブアラインメントのセット(C)を決定する。これらのうちの1つが選択され、入力アライメント(A)としてプロセスにフィードバックされ、マッチャーがそれを改善できるようにする。このプロセスは、尺度が満足のいく値を示すまで反復され、最後に計算されたアライメント(A′)が最終的に返される。
改良プロセスは、ユーザーが各ステップを制御し、場合によっては他の操作を織り交ぜて手動で行うことも、マッチャーが改良を埋め込んで自動的に行うこともできる。ユーザーは,(1)特定の対応関係のセットが正しくないことを示すことで(測定値の代わりに),または(2)選択コンポーネントの代わりに貢献することができる。
品質メジャーは、改善のための主な材料となる。これらはアライメントの本質的な尺度となる。このような尺度としては、以下のようなものが考えられる。
- 信頼度の閾値または平均信頼度。
- マッチングされたエンティティ間の凝集性測定、すなわち、隣接するエンティティが互いにマッチングされていることを意味する。
- 曖昧さの度合い、つまり、複数の他のクラスと一致するクラスの割合。
- 整列したオントロジー間の一致または不一致(d’Aquin 2009)。
- 制約の違反(例:対応するパスの非循環性
- 統語的アンチパターンの充足
- 一貫性とコヒーレンス
アライメントの曖昧さの解消
このような方法の例として、アライメント曖昧性解消がある。アラインメントは、あるエンティティが他の複数のエンティティと一致する場合(関係が等価であると仮定)、例えば、 ?:? アラインメントを探しているのに、*:*アラインメントが返された場合など、曖昧となる。
そのため、尺度としては、曖昧さの度合い、つまり、複数の他のクラスにマッチするクラスの割合や、ブール値の指標、つまり、アラインメントが曖昧であるか否かを示すものが考えられる。この問題に対処するための簡単な方法は、常に信頼度の高い対応関係を選択すること(貪欲なアルゴリズム)、または最大の重みを持つサブアラインメントを計算することとなる。
別の解決策は、2つのクラス間の正しいマッチングは、そのより一般的なエンティティとより特定的なエンティティの間で他の正しいマッチングを持つ傾向があるという考えに基づいている(Tordai 2012)。そこで、この手法では、曖昧な対応関係のそれぞれについて、関連するクラスのサブクラスによって両側から到達可能な対応関係の割合をカウントする。そして、その比率が最も高い対応関係を保持する。したがって、任意の曖昧な対応関係のペア ⟨e,f,=⟩と⟨e,g,=⟩については
もし|{⟨e′,f′,=⊑∈A;e′ ⊑e∧f′ ⊑f}|>|{⟨e′,g′,=⊑∈A;e′ ⊑e∧g′ ⊑g}|のとき,⟨e, g, =>⊑ が保存でき,そうでなければ,⟨e, f, =>が保存される。
より具体的にマッチしたエンティティの数が同じであれば、対応を選択することはできない。同じ手法は、サブクラスの代わりにスーパークラスなど、より一般的なエンティティでも使用できない。この手法は、マッチングやアラインメントの抽出に使用されたのと同じタイプの最適化技術の無効化に適用される。
アライメントのデバッグ
アライメントのデバッグまたはアラインメントの修復は、生成されたアラインメントの一貫性と協調性を回復することを目的としている。整合性とは、整列したオントロジーがモデルを持たないことであり、一貫性とは、整列したオントロジーのモデルが特定のクラスにインスタンスを持たせないこととなる。適用される尺度は、アライメントに与えられたセマンティクスに依存する。
診断理論に基づいたアライメント修復のための包括的なフレームワークは(Meilicke and Stuckenschmidt 2009; Meilicke 2011)らにより開発された。(Minimal inco-herence, or unsatisfiability, preserving subalignments (MIPS))は、不整合や不整合を発生させる対応関係のミニマルセットと定義され、診断は整合性や一貫性を回復させるためのアライメントの包含ミニマルサブセットと定義している。これらの概念の関係は、(各MIPSから1つの対応関係を取る)最小のヒットセットが診断であるということになる。
診断の最適性の概念は、修復されたアライメントの信頼性を最大化することと定義される。この最適化は、各MIPSから抑制する対応関係を個別に選択する場合(局所的最適診断)と、グローバルに選択する場合(グローバル最適診断)に適用できる。一般に、大域的に最適な診断は、局所的に最適な診断よりも小さくなる。
アライメントのデバッグの例 下図のようなアライメントを考えてみる。

支離滅裂な配置となる。これが支離滅裂なのは、クラス「Person」がインスタンスを持つことができないからである。そうでなければ「Biography」になってしまい、「Person」から分離していると想定される「Book」になってしまうからとなる。
アライメントAには4つの対応関係がある。
\[ \begin{eqnarray} &c_1& &Book\geq_{.8}Essay&\\&c_2&&Person\geq_{.7}Biography&\\&c_3&&topic=_{.6}subject&\\&c_4&&Person\geq_{.9}foaf:Person& \end{eqnarray}\]
システムは{X⊥Y, ⟨X ≤ Z⟩, ⟨Y ≥ W ⟩, Z ⊑ W }のような支離滅裂なパターン(またはアンチパターン)を使用することができる。縮小セマンティクスを使用すると、このパターンは、Xが任意の拡張を持つことができないことを意味する。なぜなら、そうでなければ、この拡張は、それが不連結であると仮定されているYのものに含まれてしまうからとなる。このパターンはアライメントAの2つの対応点c2とc1でインスタンス化されている。このようなパターンを使用するマッチャーは、c2の信頼度が低い(.7)ため、c2を破棄することを決定することができる。
しかし、これだけではアラインメントを首尾一貫したものにするには不十分である。実際、トピック・プロパティが値を持つことはない。このアラインメントには、{c1, c2}と{c1, c3, c4}の2つの最小不満足保存サブアラインメント(MUPS)が含まれている。その結果、3つの診断が存在することになる。({c1}, {c2,c3}, {c2,c4}の3つの診断が存在する) 一般的には、変更がアライメントに与える影響を再確認し、c1を引き戻すことになる(グローバルに最適)。しかし、システムは別の診断、例えば{c2 , c3 }を選択することができる。しかし、システムは、平均信頼度やその他の指標に基づいて、{c2 , c3 }(局所的に最適)などの別の診断を選択することができる。
PersonがBiographyとfoaf:Personの両方にマッチしているため、このアライメントも曖昧である。最も信頼度の低い対応関係を選択することで曖昧さを解消すると、c2は破棄される。
使用例 LogMap システムは、矛盾や支離滅裂なクラスを特定するために、論理的推論機能を使用する。大規模なオントロジーに対応するために、LogMap は不完全な推論器を使用している。このシステムでは、不整合の原因となっている最小の対応関係のセットの中から、信頼度が最も低い対応関係を選択する。ASMOVシステムは、不整合パターンによって不整合を検出し、最終的な配信前に アライメントを修正する。ASMOVが使用する不整合パターンは意味的には正しいが、完全なものではない。つまり、残りのアラインメントはまだ不整合である可能性がある。ASMOVは、これらのパターンに含まれるいくつかの対応関係を、その信頼度に基づいて拒否し、マッチングプロセスを繰り返す。ContentMapは、ユーザが提供した制約を用いた制約ベースのデバッグツールと考えることもできる。
オントロジーには不分離公理がないため、不整合検出によるオントロジー修復技術を適用することができない。不統一公理の生成方法を学習するために、ナイーブベイズ分類器を使用することができる(Meilicke et al. 2008)。このような分類器は,様々なデータセットで学習され,クラスのペアの異なる類似性の特徴(経路距離,共有特性,類似性,インスタンスセット)を用いて,どのクラスが不連結であるかを決定する.
この種の技術は、オントロジーに意味論が与えられれば、オントロジーのネットワークにも適用できる。このような規模で整列を修復することは、計算上もユーザにとっても非常に困難であるため、(Zurawski et al. 2008)は、オントロジーと整列のローカルセットである球体の中でのみ一貫性を回復することを提案した。
ALCOMO6(Applying Logical Constraints On Matching Ontologies)は、これらの研究成果をもとに開発されたものとなる。ALCOMO6はオントロジー・マッチャーとしてではなく、MIPS、MUPS、診断を完全または制約ベースで計算するツールのライブラリを提供する。これにより、図7.16の測定と選択の部分をマッチャーから独立して実装することができる。また、コヒーレンス検出をマッチングプロセスの一段階前に進めることで、類似性マトリックスから最適なインコヒーレンス回避アライメントを前もって生成する方法も含まれている。
アライメント改善のまとめ
アライメントの改善は、マッチャーに統合することもできるし、別個の、事後的な活動として考えることもできる。アライメント改善は、マッチング技術やアライメント抽出技術とは独立しており、どのような技術で作られたアライメントにも適用できるため、別個に考えることにした。したがって、どのようなシステムであっても、そのような技術に基づいてアラインメントを改善することができる。我々は、アラインメントを改善するための明確に規定された技術のみを提示した。このセクションの冒頭で述べた基準のリストからわかるように、他の技術も同じ精神で開発することができる。
similarity まとめ
基本的なマッチャーを使用する場合と、より高度なグローバルな手法を使用する場合とで、マッチングシステムを作成する際の戦略的な問題を紹介しました。具体的には、基本的なマッチャーの組み合わせ、その結果の集約、アラインメントの抽出などが挙げられる。また、抽出されたアラインメントを改善するための学習アルゴリズムや戦略の使用についても説明した。
オントロジーマッチングシステムの技術は、基本的なマッチャーを最も有利な方法で組み合わせる繊細な技術となる。本章では、マッチングシステムのコンポーネントを組み立てるためのテクニックを紹介している。ほとんどの場合、適切なアーキテクチャは、解決すべき問題に依存する。そのデータに適用できる独立した基本的なマッチャーはあるのか?データは非常に複雑であるのか?結果を評価できるユーザーはいるのか?期待される結果は注入可能でなければならないのか?これらの質問は、方法論の重要な構成要素であり、これらの質問に答えることで、さまざまな構成要素が集まることとなる。
本章で紹介する手法は、様々な要件に対して、閾値アプリケーションにおけるアライメントの完全性と正しさの間、グローバルな類似性計算の選択における品質と計算時間の間など、トレードオフの問題であることが多い。
下図は、いくつかの手法を組み合わせた架空の例です。具体的には (1)複数の基本的なマッチャーを並行して実行し、(2)それらの結果を集約し、(3)類似性の(非)類似性に基づいていくつかの対応関係を選択し、(4)アラインメントを抽出し、(5)このアラインメントを修復または曖昧さを排除し、(6)必要に応じてこのプロセスを繰り返す。

ontology Matchingの他の章では、様々な実装されたシステムが、議論された技術をどのように利用し、それらをどのように一貫したシステム・テムに構成しているかを説明されている。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
