人工知能技術 ウェブ技術 知識情報処理技術 セマンティックウェブ技術 自然言語処理 機械学習技術 オントロジー技術 オントロジーマッチング技術
前回に引き続きオントロジーマッチングより自然言語の類似性について。前回は類似性の概要を述べ、類似性を見るアプローチには、文字列のみを考慮する方法と、文字列を解釈するために何らかの言語的知識を用いる方法の2つあることを述べた。今回は、文字列のみを考慮した手法について述べる。
文字列ベースのメソッドは、文字列の構造(文字の並びとして)を利用する。文字列ベースのメソッドでは、通常、クラス Book と Textbook は似ていると判断するが、クラス Book と Volume は似ていないと判断する。
文字列を比較する方法は、文字列の見方によって様々な方法がある。例えば、正確な文字の並び、誤った文字の並び、文字の集合、単語の集合などです。(Cohen et al. 2003b)では,距離類似関数からトークンベースの距離関数まで,様々な文字列照合技術を比較している.ここでは、最も頻繁に使用される手法について述べる。
ここでは、(1)比較する文字列を共通のフォーマットに縮小するために用いられる正規化技術、(2)文字列間の共通の文字に基づいて類似性を求める部分文字列または部分配列技術、(3)ある文字列が別の文字列の誤ったバージョンである可能性をさらに評価する編集距離、(4)2つの文字列の関係に重みをつけることで文字列内の単語の重要性を確立する統計的尺度、(5)パス比較を区別している。
(1)正規化
自然言語で意味を持つ実際の文字列を比較する前に、正規化を行うことで、その後の比較結果を改善することができる。具体的には
(a)大文字小文字の正規化では、文字列中の各アルファベット文字を小文字に変換する。例えば,CD は cd,SciFi は scifi となる。
(b)ジアクリティカルの抑制 ジアクリティカル記号を持つ文字を、最も一般的な置換文字に置き換える。たとえば、Montréal を Montreal に置き換える。
(c)空白の正規化 空白、タブ、キャリッジリターンなどのすべての空白文字、またはこれらの連続した文字を、1 つの空白文字に正規化する。
(d)リンクストリッピングでは、アポストロフェイズやブランクアンダーラインをダッシュやブランクに置き換えるなど、単語間のリンクを正規化する。例えば、peer-reviewed は peer reviewed になる。
(e)ディジットサプレッションは、数字を抑制する。例えば、book24545-18はbookになる。
(f)句読点の除去は、句読点を抑制する。例えばC.D.はCDになる。
これらの正規化操作にはいくつかの制約があり、特に以下のような場合に注意が必要となる。
– 言語に依存していることが多い(例:欧米の言語で動作する)
– 順序に依存している:どの順序で適用しても同じ結果になるとは限らない。
– 結果として、意味のある情報が失われることがある。例えば、炭素14が炭素になったり、構文解析に非常に有用な文の区切りが失われたりする。
– バリエーションは減るが、同義語は増える可能性がある。例えば、フランス語のlivre
とlivréは、それぞれ本と配達を意味する別の単語となる。
(2)文字列の等価性
文字列の等価性は、対象となる文字列が同一でない場合は0を、同一である場合は1を返す。これは、類似性の尺度として捉えることができる。
定義 8 (文字列の等質性) 文字列の等質性とは,∀x, y∈𝕊, σ (x, x) = 1であり, x ≠ y, σ (x, y) = 0であるような類似性σ : S × S → [0 1] である。
これは、文字列のダウンケーシング、エンコード変換、発音記号の正規化など、何らかの構文の正規化を行った後に実行できる。
この尺度は、文字列がどのように異なるかを説明するものではない。2つの文字列を比較するより直接的な方法は、2つの文字列が異なる部分の数をカウントするハミング距離(Haming 1950)となる。ここでは、最長の文字列の長さで正規化したものを紹介する。
定義 9 (ハミング距離) ハミング距離とは、以下の式のような非類似度δ : S×S→[0 1]である。
\[\delta(s,t)=\frac{\left(\displaystyle \sum_{i=1}^{min(|s|,|t|}s(i)\neq t(i)\right)+||s|-|t||}{max(|s|,|t|)}\]
(3)部分文字列テスト
例えば、ある文字列が別の文字列の部分文字列である場合、その文字列は非常によく似ていると考えるなど、文字列の等質性からさまざまなバリエーションを得ることができる。
定義 10(部分文字列テスト) 部分文字列テストとは、σ:S×S→[01]で、∀x,y∈Sにおいて、 x=p+y+sまたはy=p+x+sとなるp,s∈Sが存在する場合、σ(x,y)=1、 そうでない場合はσ(x,y)=0となるような相似性のことである。
これは明らかに類似しています。この尺度は、2つの文字列間の共通部分の比率を測定する部分文字列類似度に改良することができる。
定義 11 (文字列の類似性) 文字列の類似性は,類似性σ : S × S → [0 1] である。 S → [0 1] とし、∀x, y∈S, tをxとyの最長の共通部分文字列とする。 𝝈(x, y) = 2|t|/(|x|+|y|)
この尺度は確かに類似性です。また、部分文字列の類似性も同様に考えることができる。この定義は、最長公約数的な接頭辞や最長公約数的な接尾辞に基づいて関数を構築するために使用することができる。
例えば、articleとaricleの類似性は8/13=0.61、articleとpaperの類似性は1/12=0.08、articleとparticleの類似性は14/15=0.93となる。
このモデルでは、ある文字列が他の文字列の接頭辞や接尾辞であるかどうかをテストする接頭辞テストや接尾辞テストから、接頭辞や接尾辞の前類似性を定義することができる。これらの尺度は対称的ではないだろう。接頭辞と接尾辞の前類似性は、ある文字列が他の文字列よりも一般的な概念を表すかどうかをテストするのに役立つかもしれない(多くの言語では、ある用語に節を加えるとその範囲が制限される)。例えば、reviewed articleはarticleよりも具体的である。また、文字列と似たような略語(ordとorderなど)を比較するのにも使える。
n-gram類似度も文字列の比較によく使われる。n-gram類似度は、文字列を比較する際によく用いられる手法で、n個の文字からなる共通のn-gramの数を計算する。例えば、articleという文字列のトライグラムは、art, rti, tic, icl, cleとなる。
定義 12 (n-gram類似性) ngram(s, n)を長さnのsの部分文字列の集合とする。 n-gram類似性は、次のような類似性σ : S × S → Rである。 𝝈(s, t)=|ngram(s, n) ∩ ngram(t, n)| この関数の正規化されたバージョンは δ(s, t)=|ngram(s, n) ∩ ngram(t, n)|/(min(|s|-|t|)-n+1)
この関数は、いくつかの文字が欠けているだけの場合、非常に効率的となる。
例えば、articleとaricleの類似度は2/4 = 0.5となり、articleとpaperの類似度は0となる。また、articleとparticleの類似度は5/6 = 0.83となる。小さすぎる文字列に対応するために、文字列の最初と最後に余分な文字を追加することで小さすぎる文字列に対応することができる。
(4)編集距離
直感的には,2つのオブジェクト間の編集距離は,一方のオブジェクトを得るために他方のオブジェクトに適用される操作の最小コストである.編集距離は,スペルミスを含む可能性のある文字列間の類似性を測定するために設計されたものとなる。
定義 13 (編集距離) 文字列操作の集合Op(op : S → S)と、文字列の任意のペアに対して、 1番目の文字列を2番目の文字列に変換する操作のシーケンスが存在するような コスト関数w : Op → Rが与えられ、文字列の任意のペアに対して、 最初の文字列を2番目の文字列に変換する(またはその逆)操作のシーケンスが 存在する場合、編集距離は非類似度δ : S × S → [0 1] であり、δ(s, t)は sをtに変換するよりコストの低い操作のシーケンスのコストとなる。 式としては以下のものとなる。
\[ \delta(s,t)=\min_{(op_i)_I;op_n(\dots op_1(s))=t}\left(\displaystyle \sum_{i\in I}w_{op_i}\right) \]
文字列編集距離において,通常考えられる操作は,文字の挿入 ins(c,i),文字の置換 sub(c,c′,i),文字の削除 del(c,i)である.これらの操作は、ins(c,i)=del(c,i)-1、sub(c,c′,i)=sub(c′,c,i)-1となることは簡単に確認できます。各操作にはコストが割り当てられており、2つの文字列の間の距離は、コストの低い方の操作セットの各操作のコストの合計となる。
Levenshtein距離(Levenshtein 1965)は、ある文字列を他の文字列に変換するのに必要な、文字の挿入、削除、置換の最小数である。Damerau-Levenshtein距離(Damerau 1964)は、隣り合う2つの文字を入れ替える転置操作を、他の操作と同じ重みで追加しています。一方、Needleman- Wunch距離 (Needleman and Wunsch 1970)は、insとdelのコストを高めに設定した編集距離となる。Levenstein距離の例を以下に示す。

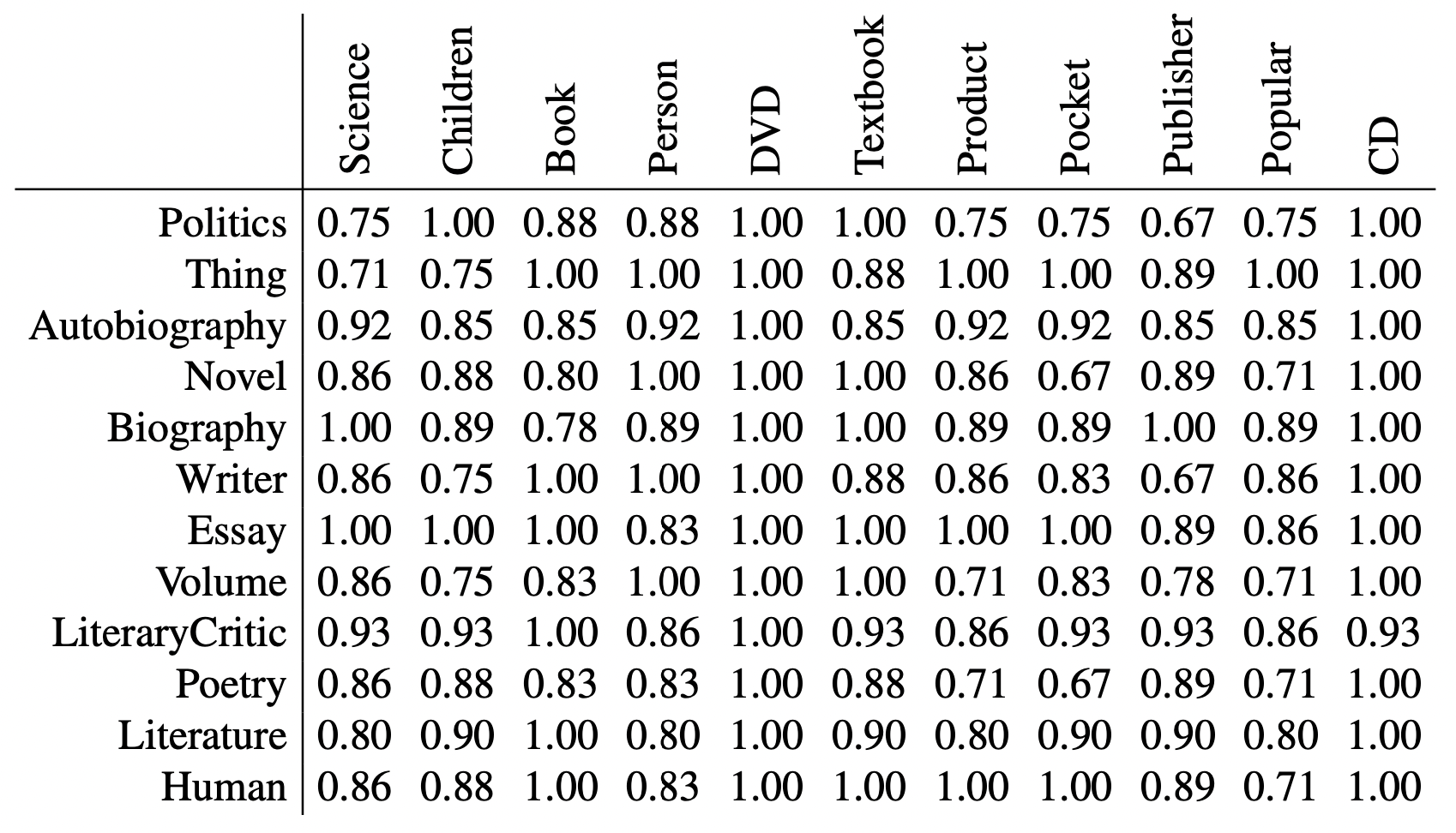
上記の例では、最も近い名前は、「Pocket」と「Novel」、「Pocket」と「Poetry」、そして「Writer」と「Publisher」、「Politics」と「Publisher」です。これらの名前は互いに比較的離れている(.67)。つまり、この場合、このような尺度だけでは対応関係は見出せません。しかし、性質に関する同じ尺度を使えば、例えば、著者と著者の間の対応関係は当然見つかる。
他の方法では、ある編集操作のコストを、その操作が適用される文字または部分文字列の関数として計算する。そのためには、各操作のコストマトリックスを使用する。このような尺度のよく知られた例は、Smith-Waterman尺度(Smith and Waterman 1981)で、操作される分子に基づいて生物学的配列間の距離を計算するように適応されている。また、Gotoh (Gotoh 1981) や Monge-Elkan (Mange and Elkan 1997) などの距離関数もある。
Jaro測度は、類似したスペルミスを含む可能性のある固有名詞をマッチングするために定義されている(Jaro 1976, 1989)。これは,編集距離モデルではなく,2つの文字列間の共通文字の数と近接度に基づいている.この尺度は対称的ではないので類似性ではない。以下にJaro尺度を示す。
定義 15 (Jaro尺度) Jaro measureは、以下のような非対称測度σ : S×S→[0 1]である。
例えば,articleとaricle,aritcleとpaperを比較すると,共通する文字の数はそれぞれ6,7,1となる(最後のケースでは,paperの「e」がarticleの「e」から離れすぎているため).転置された共通文字の数は、それぞれ0、1、0となります。その結果、これらの文字列の類似性は、0.95、0.90、0.45となります。
この尺度は、共通の接頭辞が長い文字列間のマッチを優先することで改善される(Winkler 1999)。
定義 16 (Jaro-Winkler尺度) Jaro-Winkler measure σ : S × S → [0 1] は次の通りである。
\[\sigma(s,t)=\sigma_{jaro}(s,t)+|pref(s,t)xQx\frac{(1-\sigma_{jaro}(s,t))}{10}\]
ここで,pref (s, t ) は,s と t に共通する最長の接頭辞であり,Q は定数となる。
この場合、Q=4の記事と比較した3つの文字列の類似度は .99、.98、.45です。これらの尺度は、比較のペナルティを少なくするようなミスのモデルを明示的に提供することで、これまでの尺度を改善したに過ぎないものとなる。
同様の尺度として、SMOA (Stoilos et al. 2005) があり、コンピュータユーザが識別子を定義する方法に適応している。これは、共通の部分文字列の長さと異なる部分文字列の長さに依存し、最初の部分文字列から2番目の部分文字列が差し引かれます。この尺度の値は-1から1の間となる。
(5)トークンベースの距離
以下の手法は情報検索に由来するもので、文字列を複数の単語の集合(bag of wordsとも呼ばれる)、つまり特定の単語が複数回現れる可能性のある集合とみなす。これらの手法は、通常、長いテキスト(多くの単語で構成されている)に対して有効となる。そのため、オントロジーエンティティに付けられた他の文字列を活用することが有効になる。これは以下のようにオントロジーエンティティに適応できる。
– 識別子、ラベル、コメント、文書など、さまざまな文字列のソースを集約する。さらに、接続されたエンティティに関連するトークンを集約するシステムもある(Qu et al.2006)。
– 例えば、InProceedingsはIn and Proceedingsに、peer-reviewed article(査読付き論文)はpeer, reviewed and articleにな.る。
オントロジーのエンティティは、情報検索技術を使って操作するのに適した単語のバッグ(またはマルチ集合)で識別される。エンティティの集合に適用される様々な類似性や非類似性は、これらの単語のバッグにも適用することができる。例えば、マッチング係数は集合のハミング距離を補完するものであり、Dice係数は多集合のハミング距離を補完するものとなる。つまり、集合の代わりに多集合の和、積、カーディナリティを用いる。
オリジナルの測定法は、このような文字列のコーパスに基づいたもので、すなわち、一方のオントロジーまたは両方のオントロジーで見つかったすべてのこのような文字列の集合となる。これらの尺度は、もはや比較対象の文字列に固有のものではなく、コーパスに依存する。
通常、単語の袋sを、各次元が用語(またはトークン)であり、ベクトルの各位置が対応する単語の袋におけるトークンの出現数である計量空間Vに属するベクトルsとみなす。これはマルチセットを表現する一つの方法となる。各文書は、座標ベクトルによって識別されるこの空間の点と考えることができる(Salton 1971; Salton and McGill 1983)。
エンティティがベクトルに変換されると、ユークリッド距離、マンハッタン距離(街区としても知られている)、ミンコフスキー距離の任意のインスタンス等の通常のメトリック空間の距離を使用することができる。ここでは、2つのベクトルのなす角の余弦を測定するコサイン類似性を紹介する。これは、情報検索によく使われている。
定義 17(コサイン類似度) ベクトル空間Vにおける2つの文字列sとtに対応するベクトルσV : V × V → [0 1]を考えると、 cosine similarityは次のような関数σV : V × V → [0 1]である。
\[\sigma_V(s,t)=\frac{\displaystyle\sum_{i\in|V|}\vec{s_i}x\vec{t_i}}{\sqrt{\sum_{i\in|V|}\vec{s_i}^2x\sum_{i\in|V|}\vec{t_i}^2}}\]
より粒度を細かくするには、より小さな次元を扱うために、コレスポンデンス分析で得られるような縮小された空間を使用し、同様の意味を持つ単語を同じ次元に自動的にマッピングすることができる。このような技術の有名な例は、”特異値分解(Singular Value Decomposition, SVD)の概要とアルゴリズム及び実装例について“で述べている特異値分解を使用した潜在的な意味のインデックスとして知られている(Deerwester et al. 1990)。
TFIDF (Term frequency-Inverse document fre- quency) (Robertson and Spärck Jones 1976)は、コーパス中の用語の出現頻度を考慮して、文書(bag of word)と用語との関連性を採点するために使用される、非常に一般的な尺度となる。これは通常、類似性の尺度ではなく、ある用語と文書との関連性を評価するものになる。ここでは、文書中の文字列の出現頻度とコーパス全体での頻度を比較することで、文字列に対する部分文字列の関連性を評価するために使用される。(参照:clojureでの実装)
定義 18 (Term frequency-Inverse document frequency)
多重集合のコーパスCが与えられたとき、以下の尺度を定義する。
∀t∈S,∀s∈C, tf(t,s)=t#s (termfrequency)
∀t∈S, idf(t)=log |{s∈C;t∈s}| (inversedocumentfrequency)
TFIDF(s, t) = tf (t, s) × idf (t) (TFIDF)
多くのシステムでは、TFIDFに基づいた尺度を使用している。これらの尺度は、文字列の各用語について、TFIDFに基づいてコーパスとの関連性を計算する。そして、2つの文字列の間の距離を計算するために、ベクトル空間技術を使用する。選択された空間に応じて、コーパス全体、2つの文字列でカバーされる用語の結合、または両方の文字列に含まれる用語の交点のみなど、いくつかのオプションがある。最もよく使用される集計方法は、コサイン類似度となる。
更にマルチセット間の関連性を見る手法として確率分布的なアプローチがある。これは、(他の手法で)あるトピックに対する特定の文書の関連性を確立することが可能な場合に確率分布として表されるものとなる。このアプローチの代表的なものとしては、Kullback-Leiber divergence measureがある(Kullback and Leibler 1951)。これは、2つの確率分布の間の分散を計算するものとなる。
定義 19 (Kullback-Leiber divergence) トピックの集合Tに対する確率分布πを持つドキュメントの集合Dが与えられたとき、 2つのドキュメントeとe′の間のKullback-Leiber divergenceは次のようになる。
\[\delta(e,e’)=\displaystyle\sum_{t\in T}\pi(t|e)xlog_2\left(\frac{\pi(t|e)}{\pi(t|e’)}\right)\]
この指標は、距離として使われることもあるが、実際には対称ではない。
(6)パス比較
パスの違いは、オブジェクトのラベルだけでなく、ラベルが付いているものが関係しているエンティティのラベルの並びを比較することで構成されている。例えば、下図の左側のオントロジーでは、ScienceクラスはProd- uct:Book:Scienceというパスで識別できる。

第一近似として、これらは順序付けられた方法でトークンを集約する特定の方法と考えることができる。簡単な(そして唯一の)例としては、クラスのスーパークラスの名前をすべて連結してから比較するものがある。つまり、結果は、何らかの方法で集約された個々の文字列の比較に依存しているのものになる。
定義 20 (経路距離) 2つの文字列の並び、⟨si⟩i=1 to nと⟨s'j⟩j=1 to mが与えられたとき、 それらの経路距離は以下のように定義される。
\[\delta(<s_i>_{i=1}^n,<s’_j>_{j=1}^m)=\lambda x\delta'(s_n,s’_m)+(1-\lambda)x\]
例えば、文字列の等距離をδ′とし、文字列が等しい場合は0、λとして0.7を採点することができる。そうすると、Product:Book:ScienceとBook:Essay:Science、Product:Cultural:Book:Scienceを比較しなければならない場合、その距離はそれぞれ0.273と0.09となる。
この尺度は、各パスの最後の要素間の類似性に依存しています。この類似性は、λペナルティの影響を受けるが、後続の各ステップは、λ×(1 – λ)nペナルティの影響を受ける。つまり、この計測はプレフィックスを考慮しているが、プレフィックスが結果に与える影響は、シーケンスの最後からの距離が長くなるにつれて小さくなる程度に過ぎない。このように、この尺度は、パスの中で比較する要素のランクに依存する。より正確だがコストのかかる測定法では、両方のパスの中で最もマッチしたものを選択し、パスの最後から離れたアイテムにペナルティを課すことになる。これらのパスを考慮に入れる別の方法は、Valtchev (1999)で説明されているように、単純にシーケンス上の距離として適用することになる。
文字列ベースの手法に関するまとめ
これまでの文字列比較の結果は、同じ概念を表すのに非常に似通った文字列が使われている場合に有効になる。構造の異なる同義語が使用されている場合は、類似度が低くなる。例えば、Inpro- ceedingsとproceedingsのように、非常によく似た2つの文字列が、相対的に異なる概念を表すことがあるため、類似度の低い文字列のペアを選択すると、逆に多くの誤検出が発生する。
これらの尺度は、非常に似通った2つの文字列が使用されているかどうかを検出するために使用されることがほとんどになる。そうでなければ、マッチングにはより信頼性の高い情報源を使用しなければならない。
文字列の距離を計算するソフトウェアパッケージはいくつかある。下表は、4つのJavaパッケージで利用可能な距離の簡単な比較となる。SimMet- rics,1 SecondString,2 OntoSim3 and SimPack.4 2番目のパッケージのメトリクスの比較は、(Cohen et al. 2003b)に記載されている。

以上文字列ベースの類似度について述べた。次回は言語ベースの手法について述べる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

コメント
[…] これらを行う処理の流れとしては大きく分けると4つの領域が存在する。一つ目がウェブまたはwordやpdf等のドキュメントからのデータの取得から始まり、それらからのtextデータの抽出と、正規化からなる生テキストの処理と構造化であり、二つ目が構造化されたデータへの機械学習/コーパス等による情報付与、そして最後がそれらの情報の活用(UXを含む)になる。 […]
[…] 次回は、文字列をベースとした類似性について述べる。 […]
[…] 生テキストからの処理の処理ツールに関しては、openrefineのようなデータクレンジングツールや類似性の評価のツール等がある。 […]
[…] オントロジーマッチングより自然言語の類似性について。前回は文字列ベースの類似度のアプローチについて述べた。今回は言語ベースのアプローチについて述べる。 […]
[…] 類似性(similarirtyについて(2)文字列からのアプローチ […]
[…] 1.類似性(similarity)の基礎(1) 概要 2.類似性(similarity)の基礎(2)文字列からのアプローチ […]
[…] 単語ベクトルを使うことで、例えば2つの単語の意味的な近さ(類似度)を推定することができる。ここでは、コサイン(cos)を使った類似度を説明する。2つのベクトルuとvがあり、そのなす角をθとする。ベクトルの内積の定義より、次の式が成り立つ。 […]
[…] 類似性(similarity)の基礎(2)文字列からのアプローチ […]