機械学習技術 Clojure デジタルトランスフォーメーション技術 人工知能技術 セマンティックウェブ技術 オントロジー技術 確率的生成モデル サポートベクトルマシン スパースモデリング トピックモデル Python ウェブ技術 知識情報処理技術 自然言語処理 本ブログのナビ 深層学習技術 オンライン学習 チャットボットと質疑応答技術 ユーザーインターフェース技術 推論技術 禅と人工知能 本ブログのナビ
コンピューターでシンボルの意味を扱う
意味とは、以前「言語の意味に対する2つのアプローチ(記号表現と分散表現の融合)」で述べたように、文字(あるいは音声や画像)によって伝達される何らかの情報であると考えることができる。
この情報は存在することは確実だが、誰も見た事がないダークマターのようなもので、直接見ることはできず、それが及ぼす影響が現れる観測事象(文字や音声や画像等)から推定するアプローチしかできない。
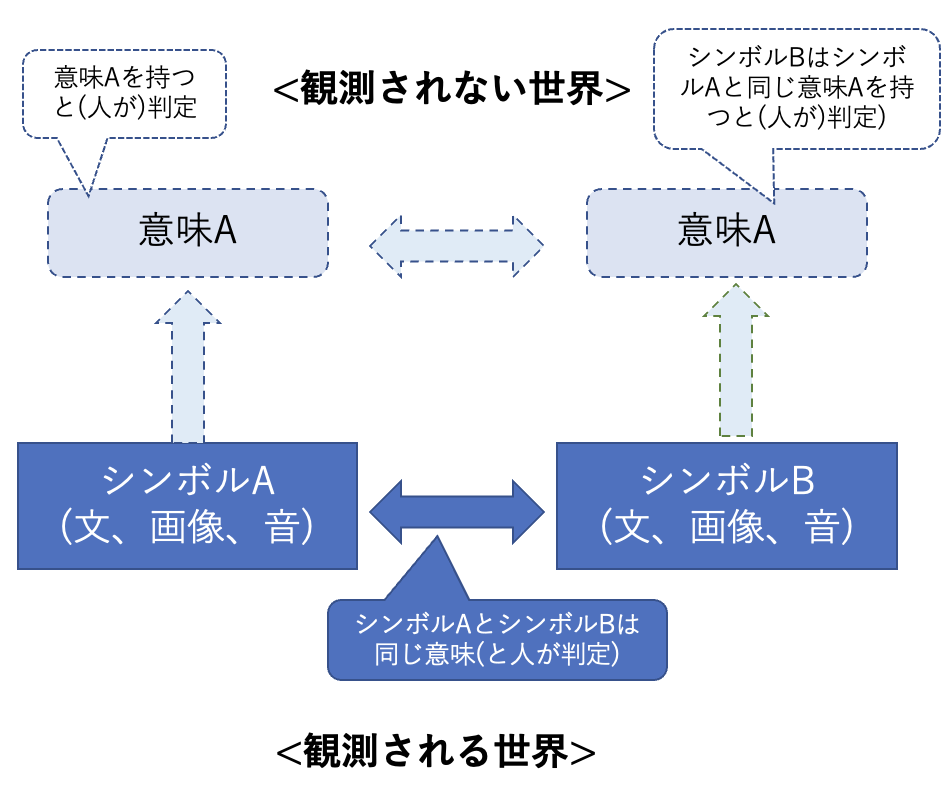
あるシンボルBがあったとき、その意味がAであることが分かるためには、それ単体では確認する事ができず、同じ意味を持つ(であろうと人が判断した)シンボルとの相対関係(含意、パラフレーズ、同一、類似等)でしか確認できない。つまり、ダークマターである「意味」はそれ単体では観測する事ができず、比較する対象が存在して初めてそのシンボルの意味が定義されるものとなる。

この関係は「具象と抽象 – 自然言語のセマティクスと説明」にも述べているように、抽象化のステップ(具体的な事物から抽象化されたものが上記で言うところのブラックマターという解釈)の観点から考えてもイメージすることができる。
また、「意味とは何か(1)哲学入門」や「ソシュールの言語学」でも、観測事象の基本構成要素であるシンボルの意味は、それ単体では構成されず、別のシンボルとの関係性により定義されると述べられていることからも分かる。
ここで、コンピュータでシンボルを扱う事を考える。「Python言語によるプログラミングイントロダクション(1)プログラミングとは」で述べたように、コンピューターの行っていることをつきつめると「計算をすること」と「計算結果を覚えること」の2つとなる。よってシンボルをコンピューターで扱えるようにするためには、対象を定量化(数値化)して何らかの計算を行えるようにする必要がある。
以上をまとめると、コンピュータでシンボルの「見えない世界にある」意味を扱うには、以下の図に示すように、シンボルに対して、何らかの定量化作業を行って中間データとし、2つのシンボルの間の意味的関係に合うように、それらの中間データを計算するように構成すれば良いこととなる。
また「具象と抽象 – 自然言語のセマティクスと説明」に述べているように、抽象化されたものは具体的な事物の「ある視点」での特徴が同じものを集めたものであり、さらにそれらの抽象物を「同じ特徴のもので集めていく」というステップを踏むことで階層構造を持つことが推察できる。またこれらの「同じ特徴のもので集めていく」という作業は、機械学習の手順で行うことができることも容易に推察できる。

つまり、シンボルAとシンボルBが等しい(あるいは類似している等)というような判断を人が行なったシンボルに対して、様々な手法を用いて計算可能な形(中間データ)に変換し、例えば等しい場合はそれらが等しくなるように計算を行う関数を定義すれば良い、ということになる。この時注意すべきことは、中間データそのものはあくまでもシンボルを変換したものあって、それが意味を表しているものではないということにある。意味は絶対的なものとしては与えられず、何らかの相対的なモノ同士の演算により与えられるということとなる。
この相対的な意味のアプローチとしては以下に示すようなパターンがある。
- 類似性(A〜B)
- 等号(A=B)
- 含有(A⊆B)
- 差分(A⋃B)-(A⋂B)
- 重なり(A⋂B)
- 合算(A⋃B)
それぞの関係性(含有、統合等)で集合の言葉が現れるが、以前「コンピューターの数学の基礎」で述べたように、集合論を用いることでものの関係性や定義を扱う事ができる(基礎数学)。
ここで、「具象と抽象 – 自然言語のセマティクスと説明」に述べたように、抽象化という観点で考えると、例えばシンボルが似ていると言ったときに、どの意味的な特徴が似ていて、似ていない意味的な特徴は何かというものは、それらを判定する視点によって異なってくるという観点は非常に重要となる。
これらの関係性に対して実際に計算を行う為に、それぞれに対応する演算する関数を定義することで、中間データを用いた意味の判定(計算)ができるようになる。例えば「類似している:similarity)」では、「similarity(類似性)の基礎(1)概要」で述べたように以下のような式で定義する事ができる。
定義 1 (類似性) 類似性 σ : o × o → R は,一対の実体から実数への関数であり, 次のような 2つの対象物の類似性を表す。 ∀x,y ∈o, σ(x, y) ≥ 0 (正性) ∀x∈o,∀y,z ∈o, σ(x, x) ≥ σ(y, z) (極大性) ∀x,y ∈o, σ(x, y) = σ(y, x) (対称性)
また、類似していないというものに対しては以下のように定義できる。
定義2(非類似性)
一組の実体が与えられたとき、非類似性δ:o×o→Rは、
一組の実体から次のような実数に変換する関数である。
∀x, y ∈ o, δ(x, y) ≥ 0 (正性)
∀x ∈ o, δ(x, x) = 0 (極小性)
∀x, y ∈ o, δ(x, y) = δ(y, x) (対称性)
δ(x,y)に関してはデータの形式(ベクトル、グラフ等)に合わせて様々な関数を定義する事ができる。例えば、「言葉の意味をコンピューターに教える(各種言語モデルについて)」や「similarity(類似性)の基礎(2)文字列ベースのアプローチ」で述べたようにコサイン類似度等のベクトル間の距離測定の尺度やPMMI、TF-IDF、Kullback-Leiber divergence measure等がある。また「分類(3)確率的識別関数(ロジスティック,ソフトマックス回帰)と局所学習(K近傍法,カーネル密度推定)」で述べたようにより汎用的な距離の評価の手法としてマハラノビス距離を求める手法もある。
このようにシンボルと関係性を数学的に定義して計算可能な形とし、元のシンボルの持つ意味の関係性を教師データとして、それらに合致するようにデータ構造と計算方法を最適化することで、シンボルの意味を扱うことができる。
ここで意味の関係性の教師データについて、あるシンボルAとBが似ているとした時、似ているという観点も様々な切り口がある。例えば図形の場合であれば、色や形、またそれらが指し示す概念のカテゴリ(生物に対するものか、非生物に対するもの等)等だし、テキストであれば、主語が似ているのか、述語が似ているのか、カテゴリが似ているのか等々、似ていると判断しようとする切り口により解釈は異なってくる。
このように計算の要となる教師データが揺らいでいては、結果も大きく揺らいでしまう。それらの観点は、意味解釈を何に利用するかというアプリケーションの観点から定義されるのがベストであり、それらの視点から観点の候補を並べて(アプリケーションの観点から似ているサンプルと似ていないサンプルを抽出して比較するものでもよい)、再現性の良い人の判定ができるようにする必要がある。
以上まとめるとコンピューターで意味を扱うためのステップとしては、まず正解データ(similarityの場合は意味が近い文のペア)を厳格な(ユースシーンにあった)基準で準備したのち、「similarity(類似性)の基礎(2)文字列ベースのアプローチ」で述べたようにデータのクレンジング処理(正規化処理)を行い、さらに「言語の意味に対する2つのアプローチ(記号表現と分散表現の融合)」で述べたように、それぞれのモデルに合わせた記号表現や分散表現での選択を行なって特徴量(中間表現)化し、それぞれの意味のアプローチをユースケースと共に確定して、それらに適切な特徴量と計算手法を最適化していくこととなる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
