Clojureを用いたシンプルな推薦アルゴリズムの実装(1)
Clojure for Machine Learningより。
推薦システムは、あるアイテムに対するユーザーの好みや嗜好を予測しようとする情報システムとなる。近年、多くのビジネスアプリケーションやソーシャルアプリケーションにおいて、ユーザーにより良い体験を提供するために、膨大な数の推薦システム(レコメンダーシステム)が構築されている。このようなシステムは、ユーザーが以前に評価した、あるいは気に入ったアイテムに応じて、ユーザーに有用な推薦を提供することができる。現在、既存の推薦システムの多くは、オンライン商品、音楽、ソーシャルメディアに関する推薦をユーザーに提供している。また、Web上の金融やビジネスアプリケーションでも、推薦システムを利用したものが数多く存在する。
推薦システムは、ユーザーに有用な情報を提供することを目的とした情報フィルタリングシステムでとなる。推薦システムは、ユーザーの行動履歴を利用したり、他のユーザーが気に入ったものを推薦したりする。この2つのアプローチが、推薦システムで用いられる2種類のアルゴリズム(コンテンツベースフィルタリングと協調フィルタリング)の基礎となっている。興味深いことに、この2つの手法を組み合わせてユーザーに推薦する推薦システムもある。これらの技術はいずれも、ユーザー中心のアプリケーションで管理・交換されるアイテムやドメインオブジェクトを、ユーザーに推薦することを目的としている。このようなアプリケーションには、オンラインショッピングやメディアなど、オンラインコンテンツや情報をユーザーに提供するウェブサイトがいくつか含まれる。
コンテンツベースフィルタリングでは、特定のユーザーの評価を用いて類似のアイテムを見つけることによって推薦が決定される。各アイテムは離散的な特徴や特性の集合として表現され、また、各アイテムは複数のユーザーによって評価される。したがって、各ユーザーに対して、各アイテムの特徴を表す入力変数の集合と、そのアイテムに対するユーザーの評価を表す出力変数の集合が複数存在することになる。これらの情報は、あるユーザが以前に評価したアイテムと同様の特徴や特性を持つアイテムを推薦するために利用できる。
協調フィルタリング法は、特定のユーザーの行動、活動、または嗜好に関するデータを収集し、この情報を使用してユーザーにアイテムを推奨することに基づく。推奨は、ユーザーの行動が他のユーザーの行動とどれだけ類似しているかに基づいて行われる。事実上、ユーザーの推薦文は、過去の行動と、システム内の他のユーザーによる決定に基づいている。協調フィルタリング技術は、類似したユーザーの嗜好を使用して、システム内のすべての利用可能なアイテムの特徴を決定する。
コンテンツベースのフィルタリング
先に述べたように、コンテンツベースフィルタリングシステムは、与えられたユーザーが肯定的に評価したり、好んだりした項目の特徴だけでなく、過去の行動に基づいて、ユーザーに推薦を行う。また、与えられたユーザーによって嫌われたアイテムも考慮することができる。アイテムは一般にいくつかの離散的な属性によって表現される。これらの属性は、分類または線形回帰に基づく機械学習モデルの入力変数または特徴に類似している。
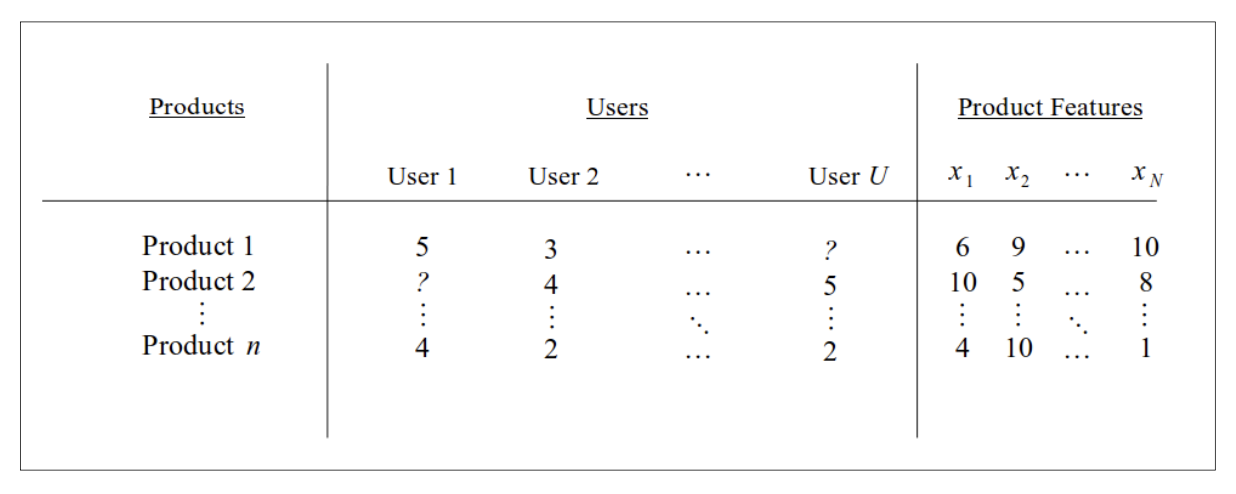
例えば、コンテンツベースのフィルタリングを利用して、オンライン商品をユーザーに推薦するシステムを構築したいとする。各商品はいくつかの既知の特徴によって特徴づけられ識別されることができ、ユーザーはすべての商品の各特徴に対して評価を提供することができる。商品の特徴量は0から10の間の値を持ち、ユーザーが商品に対して提供する評価は0から5の範囲内の値を持つ。このレコメンデーションシステムのサンプルデータを表形式で可視化すると、以下のようになる。

先の表で、システムにはn個の製品とU人のユーザーがいる。各製品はN個の特徴によって定義され、それぞれは0から10の範囲の値を持つことになり、また各製品はユーザによって評価される。ユーザuによる各製品iの評価をYu,iとする。
を推定し、それを用いてユーザの評価を予測することができる。このように、コンテンツベースフィルタリングでは、各ユーザーの評価と各商品の特徴量に線形回帰を適用して回帰モデルを推定し、それを使って未評価の商品に対するユーザーの評価を推定しているのです。事実上、我々は独立変数Xiと従属変数Yu,iを用いて、システムのすべてのユーザーについて、パラメータβμを学習する。推定されたパラメータβμと独立変数に対するいくつかの与えられた値を用いて、任意の与えられたユーザーに対する従属変数の値を予測することができる。したがって、コンテンツベースフィルタリングの最適化問題は、以下のように表すことができる。
\[arg\min_{\beta_u}\left[\displaystyle\sum_{i:r(i,u)=1}\left((\beta_u)^TX_i-Y_{u,i}\right)^2+\frac{\lambda}{2}\sum_{j=1}^n\beta_{u,j}^2\right]\\where\ r(i,u)=1\ if\ user\ u\ has\ rated\ product\ i=0\ otherwise\\and\ \beta_{u,j}\ is\ the\ j^{.th}\ value\ in \ the\ vector\ \beta_u\]
前式で定義された最適化問題をシステムの全ユーザに適用すると、Uユーザについて以下の最適化問題を生成することができる。
\[arg\min_{\beta_1,\beta_2\dots,\beta_u}\left[\displaystyle\sum_{u=1}^U\sum_{i:r(i,u)=1}\left((\beta_u)^T)X_i-Y_{u,i}\right)^2+\frac{\lambda}{2}\sum_{u=1}^U\sum_{j=1}^n\beta_{u,j}^2\right]\]
簡単に言えば、パラメータベクトルβは、入力変数をモデルの出力変数に一致するようにスケーリングまたは変換しようとするものである。追加される第2項は正則化のためのものである。興味深いことに、後退式で定義される最適化問題は線形回帰のそれと類似しており、したがってコンテンツベースフィルタリングは線形回帰の拡張として考えることができる。
コンテンツベースフィルタリングの重要な問題は、与えられた推薦システムがユーザーの嗜好や評価から学習できるかどうかである。直接的にフィードバックを行うには、システム内のアイテムのうち好きなものの評価を求める方法があるが、これらの評価はユーザの過去の行動から推測することも可能である。また、あるユーザーと特定のカテゴリのアイテムに対して学習させたコンテンツベースフィルタリングシステムは、同じユーザーの異なるカテゴリのアイテムに対する評価を予測するために使用することはできない。例えば、あるユーザーのニュースに対する好みを利用して、そのユーザーのオンラインショッピング商品に対する好みを予測することは難しい問題である。
協調フィルタリング
もう一つの主要なレコメンデーションは協調フィルタリングで、同じような興味を持つ複数のユーザーの行動に関するデータを分析し、そのユーザーに対するレコメンデーションを予測するものである。この手法の主な利点は この手法の主な利点は、システムがアイテムの特徴変数の値に依存しないことであり、その結果、システムは提供されるアイテムの特徴を知る必要がない。アイテムの特徴は、ユーザーの評価とシステムユーザーの行動から動的に決定される。
協調フィルタリングで使用されるモデルの本質的な部分は、そのユーザーの行動に依存する。この部分を構築するために、モデル内の項目に対するユーザの評価を明示的に決定するために、以下の方法を用いることができる。
- ユーザーにアイテムを特定の尺度で評価するように依頼する。
- ユーザーにアイテムをお気に入りとしてマークしてもらう。
- ユーザーに少数のアイテムを提示し、これらのアイテムの好き嫌いに応じて順序付けるよう依頼する。
- 好きなアイテムやアイテムの種類をリストアップしてもらう。
また、この情報は、ユーザーの行動から暗黙的に収集することも可能である。このように、与えられたアイテムや製品のセットに対するシステムのユーザーの行動をモデル化する方法の例としては、以下のようなものがある。
- ユーザーが閲覧するアイテムを観察する。
- 特定のユーザーが閲覧した回数の分析。
- ユーザーのソーシャルネットワークを分析し、同じような興味を持つユーザーを発見する。
例えば、前節で説明したオンラインショッピングの例に対する推薦システムを考えてみる。協調フィルタリングを用いて、入手可能な商品の特徴量を動的に判断し、ユーザが興味を持つであろう商品を予測することができる。このような協調フィルタリングを用いたシステムのサンプルデータは、以下のような表を用いて可視化することができる。

前表のデータでは、製品の特徴は不明である。利用者の評価と利用者の行動モデルだけが利用可能なデータとなる。
協調フィルタリングと商品のユーザーに対する最適化問題は以下のように表すことができる。
\[arg\min_{x_i}\left[\displaystyle\sum_{i:r(i,u)=1}\left((\beta_u)^TX_i-Y_{u,i}\right)^2+\frac{\lambda}{2}\sum_{j=1}^NX_{i,j}^2\right]\\where\ X_{i,j}\ is\ the\ j^{?th}value\ in\ the\ vector\ X_i\]
この式は、コンテンツベースフィルタリングで定義した最適化問題の逆であると見なされている。協調フィルタリングでは、パラメータのベクトルβμを推定する代わりに、製品Xiの特徴の値を決定することを目指す。同様に、複数ユーザーに対する最適化問題も以下のように定義できる。
\[arg\min_{X_1,X_2\dots,X_N}\left[\displaystyle\sum_{i=1}^n\sum_{i;r(i,u)=}\left((\beta_u)^TX_i-Y_{u,i}\right)^2+\frac{\lambda}{2}\sum_{i=1}^n\sum_{j=1}^NX_{i,j}^2\right]\]
協調フィルタリングを用いると、商品の特徴量X1,X 2 , … X N を推定し、これらの特徴量を用いてユーザβ1,β2 ,…βUの行動モデルを改善する。そして、改善されたユーザーの行動モデルを用いて、再度、より良い品目の特徴量を生成することができる。ここで特徴量と行動モデルがある適切な値に収束するまで、このプロセスを繰り返す。
なお、このプロセスでは、アルゴリズムはそのアイテムの初期特徴値を知る必要はなく、ユーザの行動モデルを最初に推定するだけで、ユーザに有用な推薦を行うことができる。
協調フィルタリングは、特殊なケースにおいてコンテンツベースフィルタリングと組み合わせることもできる。このようなアプローチは推薦のハイブリッド手法と呼ばれる。この2つのモデルを組み合わせる方法として、以下のようなものがある。
- 2つのモデルの結果を重み付けして数値的に組み合わせることができる。
- 2つのモデルのどちらかをその時々で適切に選択することができる。
- 2つのモデルからの推薦を組み合わせた結果をユーザーに見せることができる。
Slope One アルゴリズムについて
ここでは、Clojureを使った協調フィルタリングのためのSlope Oneアルゴリズムについて述べる。
Slope Oneアルゴリズムはアイテムベース協調フィルタリングの最も単純な形の一つで、基本的にユーザーが好きなアイテムを明示的に評価する協調フィルタリング技術となる。一般に、アイテムベースの協調フィルタリング技術は、ユーザの評価とユーザの過去の行動を用いて、各ユーザの単純な回帰モデルを推定することになる。したがって、システム内のすべてのユーザーuについて、関数fu (x) = ax + bを推定する。
Slope Oneアルゴリズムは、より単純な予測変数fu (x) = x + bを用いて、ユーザーの行動の回帰パターンをモデル化するため、計算量が少なくてすむ。パラメータbは2つのアイテム間のユーザー評価の差を計算することによって推定できる。Slope Oneアルゴリズムの定義は単純であるため、簡単かつ効率的に実装することができる。興味深いことに、このアルゴリズムは他の協調フィルタリング手法に比べてオーバーフィッティングの影響を受けにくい。
例として、2つのアイテムと2人のユーザーを持つ単純な推薦システムを考える。このサンプルデータを以下の表で可視化することができる。

前表のデータにおいて、ユーザー1が提供した評価を用いて、項目Aと項目Bの評価の差を求めることができる。この差は、4-2=2であることがわかる。したがって、この差をユーザ2のアイテムAの評価に加えれば、ユーザ2のアイテムBの評価は3+2=5と予測できる。
先ほどの例を3つの項目と3人のユーザーに拡張してみる。このデータは、次のように表せる。

この例では、ユーザー2(-1)とユーザー1(+2)のアイテムAとアイテムBの評価の差の平均は、(-1+2)/ 2 = 0.5となる。したがって、平均して、項目Aは項目Bよりも0.5だけ良い評価を得ていることになる。同様に、項目Aと項目Cの平均評価差は3である。項目Bに対するユーザ3の評価と項目Aと項目Bの平均評価差は2 + 0.5 = 2.5となることから、項目Aに対するユーザ3の評価を予測することができる。
Clojureによる実装
Slope One アルゴリズムの Clojure による簡潔な実装について述べる。まず最初に、サンプルデータを定義する。これは次のコードに示すように、ネストされたマップを使って行うことができる。
(def ? nil)
(def data
{"User 1" {"Item A" 5 "Item B" 3 "Item C" 2 "Item D" ?}
"User 2" {"Item A" 3 "Item B" 4 "Item C" ? "Item D" 4}
"User 3" {"Item A" ? "Item B" 2 "Item C" 5 "Item D" 3}
"User 4" {"Item A" 4 "Item B" ? "Item C" 3 "Item D" ?}})ここでは、?シンボルにnilという値を結びつけ、これを用いて、各キーがユーザを表し、その値が項目名をキーとするユーザの評価マップを表す、入れ子マップdataを定義しています。dataで表現されたネストされたマップを操作するために、以下のいくつかのユーティリティメソッドを定義する。
(defn flatten-to-vec [coll]
(reduce #(apply conj %1 %2)
[] coll))flatten-to-vec 関数は、reduce および conj 関数を用いて map をフラットなベクトルに変換するだけのものとなる。また、標準的なvec、flatten、seq関数の関数合成を使って、(def flatten-to-vec (comp vec flatten seq)) のように、flatten-to-vecを定義することができる。ここでは写像を扱っているので、任意の関数をこれらの写像の値に写像するために、 以下のいくつかの関数を定義することができる。
(defn map-vals [f m]
(persistent!
(reduce (fn [m [k v]]
(assoc! m k (f k v)))
(transient m) m)))
(defn map-nested-vals [f m]
(map-vals
(fn [k1 inner-map]
(map-vals
(fn [k2 val] (f [k1 k2] val)) inner-map)) m))map-vals 関数は、与えられたマップの値を変更するために使用することができる。この関数は、マップ内の与えられたキーによって格納された値を置き換えるためにassoc!関数を使用し、マップ内のすべてのキーと値のペアにassoc!関数を合成して適用するためにreduce関数を使用する。Clojureでは、マップを含むほとんどのコレクションは永続的で不変となるTransient関数を使用して、永続的で不変なマップを不変なマップに変換し、persistent関数を使用して、永続的なマップを不変なマップに変換することに注意が必要である。さらに、トランジェントなミュータブルコレクションをパーシステントなものに変換するpersistent!関数を使用することに注意が必要となる。変異を分離することで、この関数の性能を向上させるとともに、この関数を使用するコードには不変性の保証を保持する。前のコードで定義された map-nested-vals 関数は、map-vals 関数をネストされたマップの第2レベルの値に単純に適用する。
REPLでmap-vals関数とmap-nested-vals関数の動作を調べるには、以下のようにする。
> (map-vals #(inc %2) {:foo 1 :bar 2})
{:foo 2, :bar 3}
> (map-nested-vals (fn [keys v] (inc v)) {:foo {:bar 2}})
{:foo {:bar 3}}REPL出力に示すように,map{:foo 1 :bar 2}と{:foo {:bar 3}}の値に対してinc関数が適用されている.Wenowdefineafunctionでは,サンプルデータからSlope Oneアルゴリズムを用いて,以下のように学習済みモデルを作成する.
(defn train [data]
(let [diff-map (for [[user preferences] data]
(for [[i u-i] preferences
[j u-j] preferences
:when (and (not= i j)
u-i u-j)]
[[i j] (- u-i u-j)]))
diff-vec (flatten-to-vec diff-map)
update-fn (fn [[freqs-so-far diffs-so-far]
[item-pair diff]]
[(update-in freqs-so-far
item-pair (fnil inc 0))
(update-in diffs-so-far
item-pair (fnil + 0) diff)])
[freqs
total-diffs] (reduce update-fn
[{} {}] diff-vec)
differences (map-nested-vals
(fn [item-pair diff]
(/ diff (get-in freqs item-pair)))
total-diffs)]
{:freqs freqs
:differences differences}))train関数は、まずforマクロでモデル内の全項目の評価の差を求め、update-fnクロージャで項目の評価の頻度と評価の差を加算している。(関数とマクロの主な違いは、マクロは実行中にパラメータを評価しないこととなる。また、マクロはコンパイル時に解決・展開され、関数は実行時に呼び出される。)
update-fn 関数は、update-in 関数を使用して、マップのキーとなる値を置き換えるために使用する。fnil関数の使用に注意が必要となる。これは、本質的に値nilをチェックし、それを第2引数に置き換える関数を返すものとなる。これは、ネストされたマップデータの中で、値がnilである「?」記号で表される値を処理するために使用される。最後に、train関数は、前のステップで返された評価差のマップに、map-nested-vals関数とget-in関数を適用する。最終的に、:freqs と :differences をキーとするマップが返される。このマップには、モデル中のアイテムの頻度と他のアイテムに対する評価の差がそれぞれ格納されている。
この学習されたモデルを用いて、様々なユーザによるアイテムの評価を予測することができる。そのために、以下のコードで、前のコードで定義された train 関数によって返された値を使用する関数を実装する。
(defn predict [{:keys [differences freqs]
:as model}
preferences
item]
(let [get-rating-fn (fn [[num-acc denom-acc]
[i rating]]
(let [freqs-ji (get-in freqs [item i])]
[(+ num-acc
(* (+ (get-in differences [item i])
rating)
freqs-ji))
(+ denom-acc freqs-ji)]))]
(->> preferences
(filter #(not= (first %) item))
(reduce get-rating-fn [0 0])
(apply /))))predict関数は、train関数が返すマップの各項目の頻度と差の和を取得するためにget-in関数を使用している。そして,この関数はreduce関数と/(除算)関数の合成を利用して,これらの評価差分を平均化する.predict関数の動作は、以下のコードに示すようにREPLで調べることができる。
> (def trained-model (train data))
> (predict trained-model {"Item A" 2} "Item B")
3/2REPL出力に示すように、predict関数はtrain関数によって返された値を使用して、アイテムAに2のレーティングを与えたユーザによるアイテムBのレーティングを予測している。次のコードでpredict関数をラップして、モデル内のすべてのアイテムのレーティングを見つける関数を実装することができる。
(defn mapmap
([vf s]
(mapmap identity vf s))
([kf vf s]
(zipmap (map kf s)
(map vf s))))
(defn known-items [model]
(-> model :differences keys))
(defn predictions
([model preferences]
(predictions
model
preferences
(filter #(not (contains? preferences %))
(known-items model))))
([model preferences items]
(mapmap (partial predict model preferences)
items)))mapmap関数は,与えられたシーケンスに2つの関数を単純に適用し,最初の関数kfで作成したキーと2番目の関数vfで生成した値を持つマップを返す.もし,1つの関数が1つだけ渡された場合、mapmap関数はidentity関数を使用して、返されるマップのキーを生成する。先のコードで定義されたknown-items関数は,train関数が返す値の:differencesキーで表されるマップ上でkeys関数を用いてモデル内の全項目を決定する。最後に、predictions関数はtrain関数とknown-items関数から返された値を用いて、モデル内の全項目を決定し、特定のユーザーについて未評価の項目をすべて予測する。また、この関数はオプションの第3引数として、評価を予測するアイテム名のベクトルを取り、itemsベクトルに存在する名前を持つすべてのアイテムの予測値を返すようになっている。
以上の動作をREPLで調べてみると、次のようになる。
> (known-items trained-model)
("Item D" "Item C" "Item B" "Item A")出力にあるように、known-items関数はモデル内の全項目の名前を返す。次にprediction関数を試すと、次のようになる。
> (predictions trained-model {"Item A" 2} ["Item C" "Item D"])
{"Item D" 3, "Item C" 0}
> (predictions trained-model {"Item A" 2})
{"Item B" 3/2, "Item C" 0, "Item D" 3}predictions関数の最後のオプションパラメータをスキップすると、この関数が返すマップには、特定のユーザーによって以前に評価されていないすべてのアイテムが含まれることに注意が必要となる。このことは、REPLでkeys関数を用いて、以下のようにアサートすることができる。
> (keys (predictions trained-model {"Item A" 2}))
("Item B" "Item C" "Item D")次回は、k-meansアルゴリズムを用いたテキスト文書のクラスタリングに用いられる、テキスト文書間の類似性の尺度を使った推薦システムについて述べる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
