機械学習技術 人工知能技術 デジタルトランスフォーメーション技術 確率的生成モデル 本ブログのナビ 深層学習技術 ノンパラメトリックベイズとガウス過程 サポートベクトルマシン Clojureと関数プログラミング
Clojureを使った中華料理店過程(Chinese resturant process:CRP)と混合ガウス分布への適用
Anglican exampleより。以前”トピックモデルでのトピック数の推定 -ディリクレ過程、中華料理店過程、棒折り過程“でも述べたCRP (Chinese resturant process) は,ある特定のデータ生成過程を記述する確率過程である.数学的には,このデータ生成過程は,各ステップで,可能な整数の集合から新しい整数をサンプリングし,その特定の整数がこれまでにサンプリングされた回数に比例する確率で,これまで見たことのない新しい整数をサンプリングする一定の確率で,その整数をサンプリングするものとなる。
そこで直感的に、このプロセスを(当然ながら)中華料理屋に入るお客さんの比喩で説明する。
この中華料理店には無限にテーブルがあり、12:00には客はいない。12:01に1人の客が入店し、1番テーブルに着席する。このとき,CRPの状態は単純に(1)であり,1つのテーブルに1人の客が座っている.12:02に別の客が入店し、料理を買って席につこうとする。しかし、この顧客は、前の顧客と一緒にテーブル1に座るか、新しく空いているテーブル2を選ぶかを選択しなければならない。この過程が延々と続く。各時点で,客が新しいテーブルを選ぶ確率は,CRPのパラメータαと,各テーブルに座っている人の数の関数である.客は、より多くの客が座っているテーブルに引き寄せられる。
このチャイニーズ・レストラン・プロセスは、無限パラメータ分類タスクのモデルの一部として実用化されている。ある属性に基づいてグループに分類したいN個の個体の列を前にしているとする。もし、存在するグループの数が分かれば、この問題は簡単に解決できる。基本的には、互いに最も似ている個体を見つけ、各グループの平均的な特性を推論すれば良い。しかし、グループの数があらかじめわからない場合は、この問題は単純ではない。真の母集団のグループの数には明らかな上限がないため、この問題を解決するためには、無限に多いグループの数を提案しなければならないかもしれないからである。
これがCRPが解決しようとする問題となる。直感的には、各個人をその分類を表す「テーブル」に割り当てる。新しい個体に直面したとき,その個体が既存の分類に割り当てられる確率は,その分類がどれだけ一般的であったかによって決まり,また,全く新しい分類に割り当てられる確率もある程度決まっている。
このCRPに関して、前回紹介したClojureの確率プログラミングフレームワークであるanglicanを用いたアプローチについて述べる。実装環境としては、Gorilla Replを用いる。前回と同様に“lein new app (gr-anglican;プロジェクトフォルダー名)”で新しいプロジェクトファイルを作成し、作成されたプロジェクトフォルダの中のproject.cljファイルを以下のように設定する。
(defproject gr-anglican "0.1.0-SNAPSHOT"
:description "FIXME: write description"
:url "http://example.com/FIXME"
:license {:name "EPL-2.0 OR GPL-2.0-or-later WITH Classpath-exception-2.0"
:url "https://www.eclipse.org/legal/epl-2.0/"}
:dependencies [[org.clojure/clojure "1.11.1"]
[anglican "1.1.0"]
[org.clojure/data.csv "1.0.1"]
[net.mikera/core.matrix "0.62.0"]
;[plotly-clj "0.1.1"]
;[org.nfrac/cljbox2d "0.5.0"]
;[quil "3.1.0"]
]
:main ^:skip-aot gr-anglican.core
:target-path "target/%s"
:plugins [[org.clojars.benfb/lein-gorilla "0.6.0"]]
:profiles {:uberjar {:aot :all
:jvm-opts ["-Dclojure.compiler.direct-linking=true"]}})今回は、CRPのハイパーパラメータである数αを推定することに焦点を当てる。αは擬似的な数であり,おおよそ,新しい個体を既存のグループではなく新しいグループに割り当てる可能性として解釈できる。重要なことは、あるαの値は、あるデータセットをモデル化するのに適している場合と、そうでない場合があるということになる。例えば、すべての個体が同じグループに属しているデータセット(1 1 1 1 1 1 1)に直面した場合、各個体が新しいグループ(新しいテーブル)に行く確率は低いと思われるので、αの値を高くすることは不適切となる。一方、(0 1 2 3 4 5 6 7 8 9)のようなデータセットでは、αの値を高くすることが非常に適切であると考えられる。
ベイズの設定では、αの値に事前分布を置き、真のデータが与えられたときのαの値の事後分布を計算し、この事後分布を用いて次の個体の分類の予測を返すことになる。
まず名前空間の設定は以下のようになる。
(ns gr-anglican
(:require [gorilla-plot.core :as plot]
[clojure.core.matrix :as m])
(:use clojure.repl
clojure.pprint
[anglican core runtime emit stat]))次にランダムプロセスとcrpのモデル(関数)の定義を行う。
(defprotocol random-process2
(evidence [this]
"returns the log model evidence of the current state of the process"))
(defn crp-evidence [counts alpha]
(let [N (reduce + (vals counts)) ;; this is the total # of customers, of samples seen
C (count counts)] ;; this is the # of tables used so far
(+
(* C (Math/log alpha))
(reduce + (map log-gamma-fn (vals counts))) ;; log-gamma-fn is factorial shifted by 1
(log-gamma-fn alpha)
(- (log-gamma-fn (+ alpha N))))))
(defproc CRP-new
[alpha] [counts {}]
(produce [this] (categorical-crp counts alpha))
(absorb [this sample]
(CRP-new alpha (update-in counts [sample] (fnil inc 0))))
random-process2
(evidence [this]
(crp-evidence counts alpha)))ここでCRPの推定を行うと以下のようになる。
;; train CRPs on some samples and return the predictions:
(defquery predict [samples alpha]
(declare :primitive CRP-new evidence)
(let [crp (loop [n 0
crp (CRP-new alpha)]
(if (= n (count samples))
crp
(recur (+ n 1)
(absorb crp (nth samples n)))))]
{:sample (sample (produce crp)), :evidence (evidence crp)}))
;; here are the samples we'll use:
(def samples '(0 1 1 1 1 2 2 3 3 3 3 1 1 2 2 3 3 3 3 4 4 5 5 6 6 6 6 6 6 7 7 8))上記のデータをどのようなα値でまとめるのが最適なのかは、すぐにはわからない。顧客は圧倒的に同じテーブルに座っているわけではないが、すでに座っているテーブルを好む傾向が顕著となる。パラメータαがどのような影響を与えるかを知るために、αの異なる値に対するCRPモデルの予測値を比較してみる。
(def S 10000)
(def results-1 (map :sample (map :result (take S (doquery :importance predict [samples 0.1])))))
(def results-2 (map :sample (map :result (take S (doquery :importance predict [samples 5])))))
(def results-3 (map :sample (map :result (take S (doquery :importance predict [samples 50])))))
(plot/compose
(plot/histogram results-1 :normalize :probability :bins 10 :plot-range [[0 10] [0 1]] :color "blue")
(plot/histogram results-2 :normalize :probability :bins 10 :plot-range [[0 10] [0 1]] :color "green")
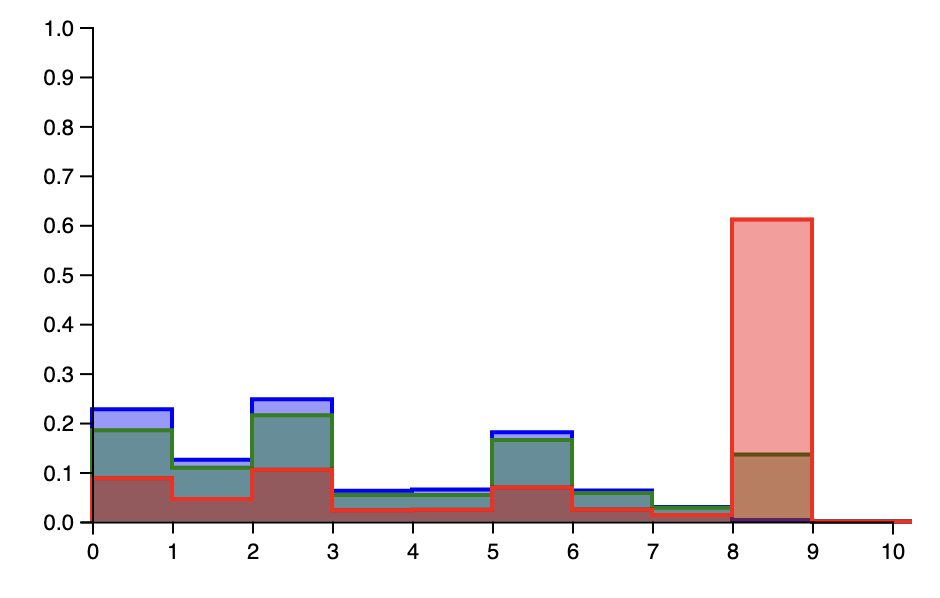
(plot/histogram results-3 :normalize :probability :bins 10 :plot-range [[0 10] [0 1]] :color "red"))これらから出力されるグラフを見ると、3つのモデルに著しい違いがあることがわかる。

青いモデル(α= 0.1)は、ある意味で最も「保守的」なモデルとなる。新しい顧客に対して、その顧客がすでに定着しているテーブルに加わることを予測する可能性が極めて高い。対照的に、赤のモデル(α = 50)は、より「冒険的」なものとなる。顧客が、まだ決済されていない新しいテーブルに参加すると予測する可能性が圧倒的に高い。緑モデルは、これらの結果にそれぞれ中程度の確率を割り当てており、既存のテーブルに明らかに、しかし圧倒的に偏っているわけではないもモデルとなる。
しかし、これらのCRPの中には、我々の特定のデータセットを予測する上で、他のものより優れているものがあることは事実です。以下に、ハイパーパラメータαの範囲について、CRPモデルの対数信頼度をプロットするコードを示す。
(def alphas [0.01 0.05 0.1 0.5 1 5 10 50 100])
(defn find-evidence [alpha]
(:evidence (:result (first (doquery :importance predict [samples alpha])))))
(def evidences (map find-evidence alphas))
(plot/list-plot (map (fn [a e] [(/ (Math/log a) (Math/log 10)) e])
alphas evidences))以下に出力されたグラフを示す。

最適なCRPは,およそ0.1から20の間のαであるように見えます(上のグラフのX軸は対数スケールで,10を基準にしている)。ここで、0と20の間の一様な事前分布をとって、正しいalphaの値を推論する。
(def alpha-prior (uniform-continuous 0 20))
(defquery predict [samples]
(declare :primitive CRP-new)
(declare :primitive evidence)
(let [alpha (sample alpha-prior)
crp (loop [n 0
crp (CRP-new alpha)]
(if (= n (count samples))
crp
(recur (+ n 1)
(absorb crp (nth samples n)))))]
(observe (flip (exp (evidence crp))) true)
{:sample (sample (produce crp)), :alpha alpha}))
(def S 25000)
(def results (take S (map :result (doquery :smc predict [samples] :number-of-particles S))))
(def projections (map :sample results))
(def alphas (map :alpha results))
(plot/compose
(plot/histogram (repeatedly S #(sample* alpha-prior)) :normalize :probability :color "green" :plot-range [[0 20] [0 0.3]])
(plot/histogram alphas :normalize :probability))
(plot/histogram projections :normalize :probability :bins 10 :plot-range [[0 10] [0 1]])
下図に、パラメータαに関する事前分布と、パラメータαに関する事後分布を比較したものを示す。

この結果より、αの正しい値はおよそ5であることが確認できる。しかし、事後予測は歪んだ分布であり、14や15といったより高いαの値を完全に排除するものとはならない。しかしながら、低いアルファの値は非常に排除されている。
更に下図にCRPの次の出力に対する事後予測分布の結果を示す。

αの値はデータセットの数に比べて中程度である可能性が高いと結論付けたので、我々の事後予測では、顧客が新しいテーブルに座る確率は中程度であると予測できる。(前述の緑の分布)
このCRPを用いたガウス混合モデルを考えることができる。
(ns gr-anglican
(:require [gorilla-plot.core :as plot]
[clojure.core.matrix :as m]
[anglican.stat :as s]
:reload)
(:use clojure.repl
[anglican
core runtime emit
[state :only [get-predicts get-log-weight]]
[inference :only [collect-by]]]))
(defn kl-categorical
"KL divergence between two categorical distributions"
[p-categories q-categories]
(let [p-norm (reduce + (map second p-categories))
q-norm (reduce + (map second q-categories))
q (into {} (for [[c w] q-categories]
[c (/ w q-norm)]))]
(reduce +
(for [[c w] p-categories]
(if (> w 0.0)
(* (/ w p-norm)
(log (/ (double (/ w p-norm))
(double (get q c 0.0)))))
0.0)))))CRPのモデルを設定する。
(defquery crp-mixture
"CRP gaussian mixture model"
[observations alpha mu beta a b]
(let [precision-prior (gamma a b)]
(loop [observations observations
state-proc (CRP alpha)
obs-dists {}
states []]
(if (empty? observations)
(count obs-dists)
(let [state (sample (produce state-proc))
obs-dist (get obs-dists
state
(let [l (sample precision-prior)
s (sqrt (/ (* beta l)))
m (sample (normal mu s))]
(normal m (sqrt (/ l)))))]
;(observe obs-dist (first observations))
(recur (rest observations)
(absorb state-proc state)
(assoc obs-dists state obs-dist)
(conj states state)))))))以下のようなダミーデータに対して、予測を行う。
(def data
"observation sequence length 10"
[10 11 12 -100 -150 -200 0.001 0.01 0.005 0.0])
(def posterior
"posterior on number of states, calculated by enumeration"
(zipmap
(range 1 11)
(mapv exp
[-11.4681 -1.0437 -0.9126 -1.6553 -3.0348
-4.9985 -7.5829 -10.9459 -15.6461 -21.6521])))予測を行い、結果をプロットする。
(def number-of-particles 100)
(def number-of-samples 50000)
(def samples
(->> (doquery :lmh crp-mixture
[data 1.72 0.0 100.0 1.0 10.0]
:number-of-particles number-of-particles)
(take number-of-samples)
doall
time))
(plot/bar-chart (sort (keys posterior))
(map #(get empirical-posterior % 0.0)
(sort (keys posterior))))CRPを組み合わせた混合ガウスモデルでの予測結果は下図のようになる。

正解データの分布に非常に近いものが予測されている。
(let [p (into (sorted-map) posterior)]
(plot/bar-chart (keys p)
(vals p)))

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
