ε-グリーディ法(ε-greedy)の概要
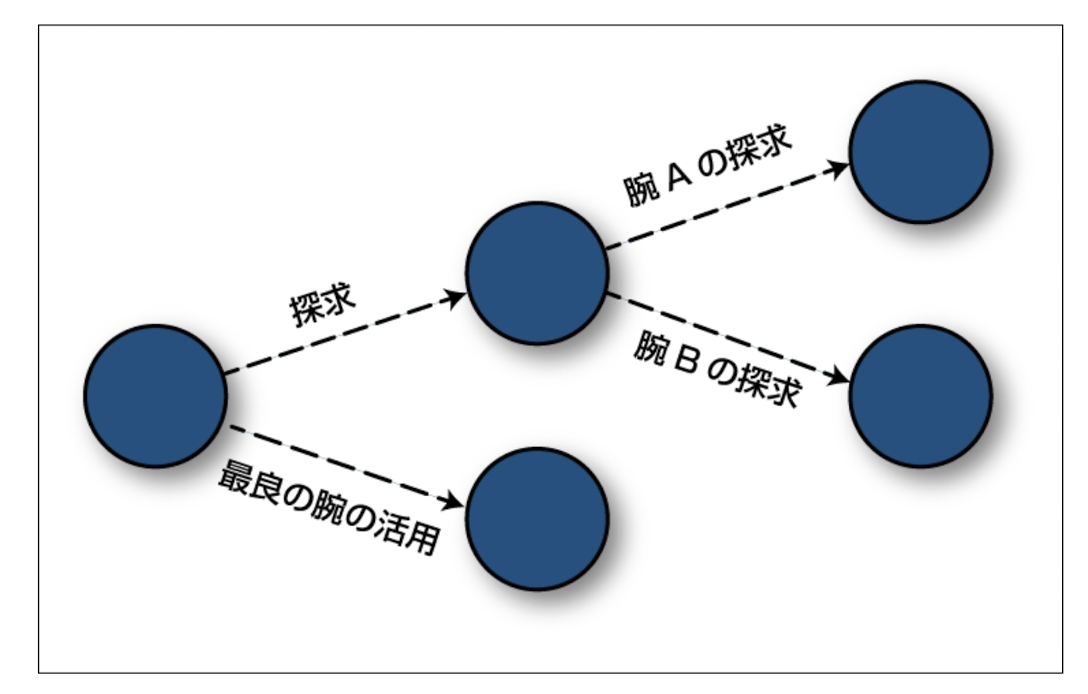
ε-グリーディ法(ε-greedy)は、強化学習などの探索と活用(exploitationとexploration)のトレードオフを取り扱うためのシンプルで効果的な戦略であり、このアルゴリズムは、最適な行動を選択する確率と、ランダムな行動を選択する確率を調整する方法となる。

以下にε-グリーディ法の概要について述べる。
- ε-グリーディ法は、ε(イプシロン)と呼ばれるパラメータを使用しており、εは0から1の間の値を取る。
- ε-グリーディ法は、エージェントが最適な行動を選ぶ確率をε、ランダムな行動(探索)を選ぶ確率を1-εとしてバランスを取る。
- ε-グリーディ法は、εの値によって探索と活用のバランスを調整でき、εが小さい場合、エージェントは主に既知の最適な行動を選び、εが大きい場合、エージェントはランダムな行動を頻繁に試す。
- ε-グリーディ法は、初期段階では探索を重視し、環境を探索して新たな情報を収集する。しかし、時間が経過するにつれてεを減少させ、収集した情報を活用して最適な行動を選びやすくなる。
- ε-グリーディ法は、強化学習タスクにおいて最適な方策を学習する際に広く使用されている。多くの強化学習アルゴリズム(例: “Q-学習の概要とアルゴリズム及び実装例について“で述べているQ学習、”SARSAの概要とアルゴリズム及び実装系について“で述べているSARSA)で探索戦略として採用されている。
ε-グリーディ法は、探索と活用のバランスを調整でき、多くの強化学習タスクで実用的なアプローチとなる。
ε-グリーディ法(ε-greedy)の具体的な手順について
ε-グリーディ法(ε-greedy)は、強化学習において、探索と活用のトレードオフを管理するための一般的な手法であり、この手法は、εの確率でランダムな行動を選択し、1-εの確率で現在の最適な行動を選択するものとなる。以下にε-グリーディ法の具体的な手順について述べる。
まずε-greedyを表すオブジェクトのクラスとしては、以下のようなものが定義できる。
class EpsilonGreedy ():
def __init__(self, epsilon, counts, value):
self.epsilon = epsilon
self.counts = counts
self.values = values
returnここでのepsilonは、与えられた腕を、どの頻度で探求するかを示し、浮動小数点数で定義されるもので(例:epsilon=0.1とすると腕を引く回数の10%が、腕の探索にあてられる)、countsは長さNのベクトルで与えられたN個の腕を、現行のバンディット問題でそれぞれ何回ひいたかを示すもの(例:arm1とarm2でそれぞれ2回ずつひいたものはcouns=[2,2])、valuesは浮動小数点のベクトルで、与えられたN個の腕を引くことで得られる報酬の平均となる(例:arm1を引いて1回のプレイで1単位、別のプレイで0単位報酬が得られ、arm2で、2回のプレイで報酬が0単位だと、values=[0.5, 0.0])
1. 初期化:
- 強化学習問題において、各行動に対する価値や報酬の推定値を初期化する。これらの推定値は、各行動がどれくらい良いかを示す指標となる。
def initialize(self, n-arms):
self.counts = [0 for col in range(n_srms)]:
self.values = [0.0 for col in range(n-arms)]
return2. 行動の選択:
- εの確率でランダムな行動を選択する。これにより、新しい行動を試して探索を促進する。
- 1-εの確率で、現在の価値や報酬の推定が最も高い行動を選択する。これにより、既知の良い行動を活用する。
def ind_max(x):
m = max(x)
return x.index(m)
def select_arm(self):
if random.random() > self.epsilon:
return ind_max(self.values)
else:
return random.randrange(len(self.values))上記のコードでは、ランダムに生成された数がepsilonよりも大きければ、アルゴリズムはvalueフィールドにあるキャッシュ値が最大の腕を選択し、そうでなければランダムで腕を選択している。
3. 報酬の観測と推定値の更新:
- 選択した行動に対する実際の報酬を観測する。
- 推定値を更新する。これは、選択した行動の推定値を実際の報酬に近づける方法で、例えば、移動平均や時系列の更新方法を使用することがある。
def update(self, chosen_arm, reward):
self.counts[chosen_arm] = self.count[chosen_arm] + 1
n = self.count[chosen_arm]
value = self.values[chosen_arm]
new_value = ((n-1) / float(n)) * value + (1 / float(n)) * reward
self.values[chosen_arm] = new_value
return上記のコードでは、updateがcountsを増やして、選択した腕の現在の推定値を調べ、初めてであれば、その腕を引いたことで得られた報酬を、過去に引いたことがある腕であれば、選択した腕の推定値を以前の推定値と、今受け取った報酬との加重平均として更新する。
これは、特定の選択肢に関する経験が多ければ、アルゴリズムにとって1回の観察の価値がどんどんなくなることを示している。この加重係数は、腕を引くことで得られる報酬が、時間の経過と共に変化する場合に、重要なパラメータとなってくる。
4. 繰り返し:
- 上記の手順を反復的に繰り返す。システムが学習するにつれて、ε-グリーディ法は探索と活用のバランスを取りながら、最適な行動を見つけることが期待される。
ε-グリーディ法は、探索を通じて未知の状態や行動を探索し、同時に既知の情報を利用して効率的に学習することができ、εの値を調整することで、探索と活用の割合を変更することができ流手法となる。例えば、εを小さく設定すると、より活用が強調され、εを大きく設定すると、より多くの探索が行われる。
ε-グリーディ法(ε-greedy)の実装例について
ε-グリーディ法(ε-greedy)の実装例を示す。この例では、εの値を0.1(10%の確率でランダムな行動を選択)とし、Q学習と組み合わせて使用している。以下はPythonのコード例となる。
import random
# Qテーブルの初期化(例として状態数と行動数を設定)
num_states = 10
num_actions = 4
Q = [[0 for _ in range(num_actions)] for _ in range(num_states)]
# εの設定
epsilon = 0.1 # εの値を0.1に設定
# Q学習のパラメータ(学習率と割引率)
learning_rate = 0.1
discount_factor = 0.9
# エピソード数
num_episodes = 1000
# Q学習の実行
for episode in range(num_episodes):
state = random.randint(0, num_states - 1) # ランダムな初期状態
while True:
# ε-グリーディ法による行動選択
if random.uniform(0, 1) < epsilon:
action = random.randint(0, num_actions - 1) # εの確率でランダムな行動を選択
else:
action = Q[state].index(max(Q[state])) # 1 - εの確率で最適な行動を選択
# 行動を実行して次の状態と報酬を取得
next_state = random.randint(0, num_states - 1) # ダミーの次の状態
reward = 0 # ダミーの報酬
# Q値の更新(Q学習)
best_next_action = Q[next_state].index(max(Q[next_state]))
Q[state][action] = Q[state][action] + learning_rate * (reward + discount_factor * Q[next_state][best_next_action] - Q[state][action])
state = next_state
if state == num_states - 1:
break
# 学習結果の表示
print("学習結果(Qテーブル):")
for i in range(num_states):
print("状態", i, ":", Q[i])
このコードは、ε-グリーディ法を使用してQ学習を実装している。εの値に基づいて、ランダムな探索と最適な行動の活用が調整されている。εの値や他のパラメータは、問題に応じて調整することができ、この例はQ学習に適用されているが、ε-グリーディ法は他の強化学習アルゴリズムにも適用できる。
ε-グリーディ法(ε-greedy)のコードのデバックについて
バンディットアルゴリズムでは、受け取るべきデータをアルゴリズムが能動的に選択肢、それを使ってオンライン学習している。そのため、能動的な学習を行わない一般的な機械学習のアルゴリズムと比較して、単にデータを与えるだけではなく、ある程度勝手な動作する形でデバックを行う必要がある。
これらを実現するためによく用いられる方法がモンテカルロ法でのシミュレーションとなる。たとえば、誰かが広告を見るたびに、決まった確率で、その人が考古をクリックすると仮定し、バンディットアルゴリズムを使ってこの確率を推定し、クリックスルー率を最大化する戦略を決定しようとしたり、登録ユーザーではない、新しい訪問客がサイトを訪れたら、その訪問客が、決まった確率で、ランディングページを見てユーザー登録をすると仮定した時、この確率を推定し、コンバージョン率を最大化する戦略を決定するような問題を考える。
このような問題では、一定の時間は報酬が1で、残りの時間は0となる確立分布(ベルヌーイ分布)を仮定して作成することができる。
例えば、潜在ユーザーがサイトを訪れたら、腕を選び、特定のweb構成を表示し、訪問客は、それからユーザー登録をする(報酬1を受け取る)か、しないか(報酬は0となる)を選択する。このようなシミュレーションはベルヌーイ腕と呼ばれ、以下のようなコードが表される。
class BernouliArm():
def __init__(self, p):
self.p = p
def draw(self):
if random.random() > self.p:
return 0.0
else:
return 1.0このアプローチに数多くの腕を処理する適用するには以下のようにする。
means = [0.1, 0.1, 0.1, 0.1, 0.9]
n_arms = len(means)
random.shuffle(means)
arms = map(lambda (mu): BernouliArm(mu), means)このアプローチにより、5つの腕のある配列が設定され、その中の4本は10%の時間報酬を出すが、最も良い腕は90%の時間報酬を出すものとなる。ベルヌーイ腕を試すには、配列のいくつかの要素に対して、drawを数回呼び出す。
これらを使ったテストアルゴリズムは以下のようになる。
def test_algorithm(algo, arms, num_sims, horizon):
chosen_arms = [0.0 for i in range(num_sims * horizon)]
rewards = [0.0 for i in range(num_sims * horizon)]
cumulative_rewards = [0.0 for i in range(num_sims * horizon)]
sim_nums = [0.0 for i in range(num_sims * horizon)]
times = [0.0 for i in range(num_sims * horizon)]
for sim in range(num_sims):
sim = sim + 1
algo.initialize(len(arms))
for t in range(horizon):
t = t + 1
index = (sim - 1) * horizon + t - 1
sim_nums[index] = sim
times[index] = t
chosen_arm = algo.select_arm()
chosen_arms[index] = chosen_arm
reward = arms[chosen_arms[index]].draw()
rewards[index] = reward
if t == 1:
cumulative_rewards[index] = reward
else:
cumulative_rewards[index] = cumulative_rewards[index - 1] + reward
algo.update(chosen_arm, reward)
return [sim_nums, times, chosen_arms, rewards, cumulative_rewards]このようなテストケースでε-グリーディ法(ε-greedy)を評価した結果を以下に示す。

εが大きい(探索により多く時間を割く)ものは立ち上がりは早い。また小さいものは立ち上がりは遅いが最終的に到達するパフォーマンスレベルは高くなる。
しかしながら、累積報酬の観点から見るとεが小さいものは悪い選択を多くとってしまうため高くはならない。

ε-グリーディ法(ε-greedy)の課題について
ε-グリーディ法(ε-greedy)は強化学習において探索と活用のトレードオフを調整する強力な戦略だが、いくつかの課題が存在している。以下にε-グリーディ法の主な課題を示す。
1. 固定のεパラメータ:
ε-グリーディ法は通常、固定のεパラメータを使用している。しかし、問題の性質によって最適なεの値が異なる場合があり、固定のεパラメータでは最適な探索と活用のバランスを達成できないことがある。
2. εの減少速度:
εの減少速度(εを時間経過に応じて減少させる速度)を選択することは挑戦的な課題であり、適切な速度を見つけるためには試行錯誤が必要となる。速度が速すぎると、早い段階で活用が優先され、探索が不足する可能性がある。速度が遅すぎると、長い間探索を続けるため、収束が遅くなる可能性がある。
3. 最適なεの知識が必要:
ε-グリーディ法は最適なεの値を事前に知っていることが前提となる。しかし、未知の環境やタスクにおいて、最適なεを見つけることは難しい場合がある。
4. εが高い場合の無駄な探索:
εが高い場合、エージェントはランダムな行動を頻繁に選択する。これにより、学習の無駄な探索が増加し、学習効率が低下する可能性がある。
5. ランダム性の影響:
ε-グリーディ法は確率的な要素を持つ。そのため、同じε-グリーディ法を異なる環境やシードで複数回実行すると、結果が異なることがある。
これらの課題に対処するために、ε-グリーディ法のパラメータ調整や派生アルゴリズムの採用、自動ハイパーパラメータ調整、εの動的な調整(例: ε逓減)、様々な探索戦略の組み合わせなどが使用される。最適な探索戦略は、特定のタスクや環境に依存し、実験と調整によって見つける必要がある。
ε-グリーディ法(ε-greedy)の課題への対応について
以下に、ε-グリーディ法の課題への対処方法について述べる。
1. εの調整:
ε-グリーディ法では、εの値の調整が重要であり、εが小さすぎると、探索が不足し、εが大きすぎると無駄なランダム行動が増える。最適なεの値を見つけるために、εの値を時間経過に応じて調整する方法があり、εを減少させ、学習の初期段階では探索を重視し、後の段階では活用を増やすことができる。
2. 逐次的なεの調整:
ε-グリーディ法では、εの値を事前に決定する必要がある。しかし、環境が変化する場合や学習の途中で最適なεが変化することがあり、逐次的なεの調整を導入し、学習中にεを適応的に変更する方法が考えられる。
3. バリエーションの利用:
ε-グリーディ法は一つの探索戦略であり、その性能は問題によって異なる。問題に応じて他の探索戦略と組み合わせることができも例えば、”UCB(Upper Confidence Bound)アルゴリズムの概要と実装例“で述べているUCB(Upper Confidence Bound)、”Boltzmann Explorationの概要とアルゴリズム及び実装例について“で述べているBoltzmann Explorationなどの探索アルゴリズムと組み合わせて使用することで、効果的な探索を行うことができる。
4. パラメータの自動調整:
εの値や他のハイパーパラメータを自動調整するハイパーパラメータ最適化アルゴリズムを使用することができ、これにより、最適なハイパーパラメータ設定を探索する手間を減らし、性能を向上させることが可能となる。
5. 強化学習アルゴリズムの選択:
ε-グリーディ法は特定の強化学習アルゴリズムと組み合わせて使用され、適切な強化学習アルゴリズムを選択し、ε-グリーディ法と組み合わせて使用することで、課題に適した探索戦略を選ぶことができる。
参考情報と参考図書
強化学習の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“に記載している。そちらも参照のこと。
1. Reinforcement Learning: An Introduction
Authors: Richard S. Sutton & Andrew G. Barto
Publisher: MIT Press
Edition: 2nd (2018)
強化学習の「標準テキスト」。
ε-greedyや探索/利用トレードオフの基本概念はもちろん、理論と実装例まで詳述。
特に第2章〜第3章でε-greedyが丁寧に説明されている。
2. Algorithms for Reinforcement Learning
Author: Csaba Szepesvári
Publisher: Morgan & Claypool Publishers
強化学習アルゴリズムに焦点を当てたコンパクトで理論的な本。
ε-greedyを含む代表的な方策探索法(policy search)について解説。
3. Deep Reinforcement Learning Hands-On
Author: Maxim Lapan
Publisher: Packt Publishing
実践的な深層強化学習の入門書。
ε-greedyを含む探索戦略の実装例(Python, PyTorch)が豊富。
4. Reinforcement Learning: State-of-the-Art
Editors: Marco Wiering & Martijn van Otterlo
Publisher: Springer
複数の論文寄稿で構成されたリファレンス集。
ε-greedyを用いた最新アルゴリズムや変種に触れられる場合あり。
ε-greedyの位置づけや、他の探索手法(Boltzmann, UCBなど)との比較が詳しい。
6. Hands-On Reinforcement Learning with Python
Bandit Algorithms
-
Bandit Algorithms — Tor Lattimore & Csaba Szepesvári (Cambridge University Press)
Multi-armed bandit問題とε-greedyの理論的背景。
Machine Learning 教科書
-
Pattern Recognition and Machine Learning — Christopher M. Bishop
強化学習基盤理論の補強に有用。
-
“Reinforcement Learning: A Survey” — Leslie Pack Kaelbling, Michael L. Littman, Andrew W. Moore
参考図書としては”「強化学習」を学びたい人が最初に読む本“


“機械学習スタートアップシリーズ Pythonで学ぶ強化学習“

“つくりながら学ぶ!深層強化学習 PyTorchによる実践プログラミング“等を参照のこと。


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
