強化学習技術
概要
強化学習はある環境内におけるエージェントが、現在の状態を観測し、取るべき行動を決定する問題を扱う機械学習の一種。エージェントは行動を選択することで環境から報酬を得る。強化学習は一連の行動を通じて報酬が最も多く得られるような方策(policy)を学習する。環境はマルコフ決定過程として定式化される。代表的な手法としてTD学習やQ学習が知られているものとなる。
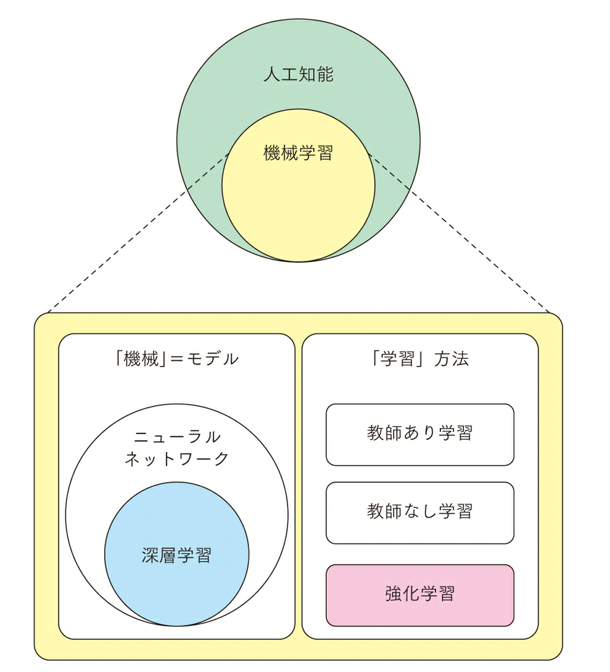
強化学習を取り巻くキーワードの関係を整理したものが以下となる。

機械学習は人工知能を実現する技術の一つであり、機械学習は文字通り「機械」を「学習」させる手法で、「機械」はモデルと呼ばれ、実態はパラメータを持った数式となる。このパラメータを、与えたデータに合うように調整するのが「学習」となる。

強化学習は、教師ありデータ学習、教師なしデータ学習といった「データ」を与える手法と異なり「環境」を与えるものとなる。環境とは「行動」と行動に応じた「状態の」の変化が定義されており、ある状態への到達に対し「報酬」が与えられる空間のこととなる。端的には、ゲームのようなものとなる。ゲームでは、ボタンを押したらキャラクターがジャンプしたりする。「ボタンほ押す」のが行動であり、「キャラクターがジャンプする」のが状態の変化に相当する。そしてゴールに到達できれば「報酬」が得られる。
実際、強化学習で使用する「環境」はゲームが多い。Pythonの強化学習のライブラリであるOpenAI Gymでは、強化学習の環境としてゲームが収録されている。

研究でも、Atari2600というゲーム機のゲームが強化学習の性能を測るための環境として使用されている。
強化学習では「環境」で「報酬」が得られるようにモデルのパラメータを調整する。このとき、モデルは「状態」を受け取り「行動」を出力する関数となる。Metacarを利用すれば、ブラウザ上に強化学習のしくみを体験することができる。

Metcarにはブラウザ上で車を運転する環境が用意されており、そこでモデルの学習が可能となる。また、学習した結果、モデルがどの「状態」に対し、どの「行動」を高く評価しているのかを確認できる。
強化学習は「行動」に対する「報酬」(≒正解)があるという点から教師あり学習によく似ている。教師あり学習と異なる点は、単体でなく全体の報酬(正解)で最適化を行うという点にある。例えば、一日1000円もらえるければ、3日我慢すれば10000円もらえるという場合を考えてみる。行動は、我慢するかしないかの2つとなる。
教師あり学習では単体の行動結果を評価するため、我慢しない=1000円の方が最適な行動になる。強化学習では全体と弟子の結果を評価するため、3日我慢する方が最適な行動となる。強化学習における環境の開始から終了までの期間(今回のケースであれば3日)を「1エピソード」と呼び、この1エピソードで得られる報酬を最大化することが強化学習の目的となる。
つまり、強化学習において「行動」は「報酬の総和」の最大化に繋がるかという観点から評価される。この評価をどう行うかは、モデル自身が学習する必要がある。つまり、強化学習のモデルは2つのことを学ぶ。一つ目は行動の評価方法、2つ目は(評価に基づく)行動の選び方(=戦略)となる。
行動の評価方法を学習していくという点は、強化学習の強みとなる。以後や将棋といった複雑なゲームでは「今の一手がどれくらい良いか?」という評価を行うのは困難だが、強化学習ではその評価方法自体を学習してくれる。そのため、人間が感覚的・直感的に判断している操作についても学習をさせることができる。
ただし、これは行動の評価がモデル任せになるということも意味している。人がラベルという形で正解を与えないため、モデルがどんな判断をするようになるかはモデルまかせになる。この点は教師なし学習のデメリットとも通じる。強化学習では、人の感覚と異なる評価が獲得され、意図しない行動をするようになる可能性がある。
教師あり学習が可能な場合は、まず教師あり学習を行うことが望ましい。教師あり学習はラベルを与えるためモデルの挙動が制御でき、単純にデータを増やすほど精度が高まるというわかりやすいスケーラビリティがある。強化学習、教示なし学習にはそれぞれメリットがあるが、実務ではどんな挙動をするかわからず、改善も単純にはいかない手法は歓迎されない。
本ブログではそれらについて以下の内容について述べている。
実装
強化学習の基礎
強化学習技術の概要と各種実装について
強化学習技術の概要と各種実装について。強化学習(Reinforcement Learning)は、機械学習の一分野であり、エージェント(Agent)と呼ばれる学習システムが、環境との相互作用を通じて最適な行動を学習する手法となる。強化学習では、具体的な入力データと出力結果のペアが与えられる教師あり学習とは異なり、報酬信号(Reward signal)と呼ばれる評価信号が与えられることが特徴となる。
ここでは強化学習技術の概要と様々な実装形態について述べている。
TD誤差(Temporal Difference Error)の概要と関連アルゴリズム及び実装例
TD誤差(Temporal Difference Error)の概要と関連アルゴリズム及び実装例。TD誤差(Temporal Difference Error)は、強化学習において用いられる概念の一つで、状態価値関数や行動価値関数の更新において重要な役割を果たすものとなる。TD誤差は、ある状態や行動の価値の見積もりと、その次の状態や行動の価値の見積もりの差を表している。TD誤差は、Bellman方程式を利用して、ある状態や行動の価値を次の状態や行動の価値と関連付けることで定義されている。
TD学習の概要とアルゴリズム及び実装例
TD学習の概要とアルゴリズム及び実装例。TD(Temporal Difference)学習は、強化学習(Reinforcement Learning)の一種で、エージェントが環境と相互作用しながら報酬を最大化する方法を学習するための手法となる。TD学習は、将来の報酬の予測を更新するために、実際に観測された報酬と将来の予測値との差分(Temporal Difference)を利用している。
マルコフ決定過程(MDP)の概要とアルゴリズム及び実装例について
マルコフ決定過程(MDP)の概要とアルゴリズム及び実装例について。マルコフ決定過程(MDP、Markov Decision Process)は、強化学習における数学的なフレームワークであり、エージェントが状態と行動に関連付けられた報酬を受け取る環境内での意思決定問題をモデル化するために使用されるものとなる。MDPは確率論的な要素とマルコフ性質を持つプロセスを表現している。
マルコフ決定過程(MDP)と強化学習を統合したアルゴリズムと実装例
マルコフ決定過程(MDP)と強化学習を統合したアルゴリズムと実装例。”マルコフ決定過程(MDP)の概要とアルゴリズム及び実装例について“で述べているマルコフ決定過程(MDP)と”強化学習技術の概要と各種実装について“で述べている強化学習を統合したアルゴリズムは、価値ベースの手法や方策ベースの手法を組み合わせアプローチとなる。
バンディット問題の概要と適用事例及び実装例
バンディット問題の概要と適用事例及び実装例。バンディット問題(Bandit problem)は、強化学習の一種であり、意思決定を行うエージェントが未知の環境において、どの行動を選択するかを学習する問題となる。この問題は、複数の行動の中から最適な行動を選択するための手法を見つけることを目的としている。
ここではこのバンディット問題に関して、ε-グリーディ法、UCBアルゴリズム、トンプソンサンプリング、softmax 選択、置換則法、”EXP3 (Exponential-weight algorithm for Exploration and Exploitation)アルゴリズムの概要と実装例について“でも述べているExp3アルゴリズム等の主要なアルゴリズムの概要と実装および、適用事例としてオンライン広告配信、医薬品の創薬、株式投資、クリニカルトライアルの最適化等とそれらの実装手順について述べている。
行動方策に基づく手法
Q-学習の概要とアルゴリズム及び実装例について
Q-学習の概要とアルゴリズム及び実装例について。Q-学習(Q-Learning)は、強化学習の一種で、エージェントが未知の環境を探索しながら最適な行動を学習するためのアルゴリズムとなる。Q-学習は、エージェントが行動価値関数(Q関数)を学習し、この関数を使用して最適な行動を選択する方法を提供している。
Vanilla Q-Learningの概要とアルゴリズムおよび実装例について
Vanilla Q-Learningの概要とアルゴリズムおよび実装例について。Vanilla Q-Learning(ヴァニラQ学習)は、強化学習の一種で、エージェントが環境とやり取りしながら最適な行動を学習するためのアルゴリズムの一つとなる。Q-Learningは、Markov Decision Process(MDP)と呼ばれる数学的モデルに基づいており、エージェントは状態(State)と行動(Action)の組み合わせに関連付けられた価値(Q値)を学習し、そのQ値をもとに最適な行動を選択する。
Double Q-Learningの概要とアルゴリズム及び実装例について
Double Q-Learningの概要とアルゴリズム及び実装例について。Double Q-Learning(ダブルQ-ラーニング)は、”Q-学習の概要とアルゴリズム及び実装例について“で述べているQ-Learningの一種であり、強化学習のアルゴリズムの一つであり、Q値を推定するための2つのQ関数を使用することで、過大評価(overestimation)の問題を軽減し、学習の安定性を向上させるものとなる。この手法は、Richard S. Suttonらによって提案されている。
SARSAの概要とアルゴリズム及び実装系について
SARSAの概要とアルゴリズム及び実装系について。SARSA(State-Action-Reward-State-Action)は、強化学習における一種の制御アルゴリズムで、主にQ学習と同じくモデルフリーな手法に分類されたものとなる。SARSAは、エージェントが状態\(s\)で行動\(a\)を選択し、その結果得られる報酬\(r\)を観測した後、新しい状態\(s’\)で次の行動\(a’\)を選択するまでの一連の遷移を学習している。
ε-グリーディ法(ε-greedy)の概要とアルゴリズム及び実装例について
ε-グリーディ法(ε-greedy)の概要とアルゴリズム及び実装例について。ε-グリーディ法(ε-greedy)は、強化学習などの探索と活用(exploitationとexploration)のトレードオフを取り扱うためのシンプルで効果的な戦略であり、このアルゴリズムは、最適な行動を選択する確率と、ランダムな行動を選択する確率を調整する方法となる。
Boltzmann Explorationの概要とアルゴリズム及び実装例について
Boltzmann Explorationの概要とアルゴリズム及び実装例について。Boltzmann Explorationは、強化学習において探索と活用のバランスを取るための手法の一つであり、通常、”ε-グリーディ法(ε-greedy)の概要とアルゴリズム及び実装例について“で述べているε-グリーディ法がランダムに行動を選択する確率を一定に保つのに対し、Boltzmann Explorationは行動価値に基づいて選択確率を計算し、これを使って行動を選択している。
Thompson Samplingアルゴリズムの概要と実装例
Thompson Samplingアルゴリズムの概要と実装例。Thompson Sampling(トンプソン・サンプリング)は、強化学習や多腕バンディット問題などの確率的意思決定問題に使用されるアルゴリズムであり、このアルゴリズムは、複数の選択肢(アクションまたはアームと呼ばれることが多い)の中から最適なものを選択する際に、不確実性を考慮するために設計されたものとなる。特に、各アクションの報酬が確率的に変動する場合に有用となる。
UCB(Upper Confidence Bound)アルゴリズムの概要と実装例
UCB(Upper Confidence Bound)アルゴリズムの概要と実装例。UCB(Upper Confidence Bound)アルゴリズムは、多腕バンディット問題(Multi-Armed Bandit Problem)において、異なるアクション(または腕)の間で最適な選択を行うためのアルゴリズムであり、アクションの価値の不確実性を考慮し、探索と利用のトレードオフを適切に調整することで、最適なアクションの選択を目指す手法となる。
ポリシー勾配法とアクタークリティック法
ポリシー勾配法の概要とアルゴリズム及び実装例
ポリシー勾配法の概要とアルゴリズム及び実装例。ポリシー勾配法(Policy Gradient Method)は、強化学習(Reinforcement Learning, RL)において、エージェントが直接ポリシー(行動選択の方針)を学習する手法の一つであり、この手法は、ポリシーの確率的な関数を用いて行動を選択し、その関数のパラメータを最適化することで、エージェントの長期的な報酬を最大化しようとするものとなる。
方策勾配法の概要とアルゴリズム及び実装例について
方策勾配法の概要とアルゴリズム及び実装例について。方策勾配法(Policy Gradient Methods)は、強化学習の一種で、特に方策(ポリシー)の最適化に焦点を当てる手法となる。方策は、エージェントが状態に対してどのような行動を選択すべきかを定義する確率的な戦略であり、方策勾配法は、方策を直接最適化することで、報酬を最大化するための最適な戦略を見つけることを目指す。
REINFORCE (Monte Carlo Policy Gradient)の概要とアルゴリズム及び実装例について
REINFORCE (Monte Carlo Policy Gradient)の概要とアルゴリズム及び実装例について。REINFORCE(またはMonte Carlo Policy Gradient)は、強化学習の一種で、方策勾配法(Policy Gradient Method)の一つであり、REINFORCEは、方策(ポリシー)を直接学習し、最適な行動選択戦略を見つけるための方法となる。
アドバンテージ学習の概要とアルゴリズム及び実装例
アドバンテージ学習の概要とアルゴリズム及び実装例。アドバンテージ学習(Advantage Learning)は、”Q-学習の概要とアルゴリズム及び実装例について“で述べているQ学習やポリシー勾配法の強化バージョンで、状態価値と行動価値の差、すなわち「アドバンテージ(優位性)」を学習する手法となる。従来のQ学習では、状態と行動のペアに対して得られる報酬の期待値(Q値)を直接学習していたが、アドバンテージ学習では、それに対して相対的にどれだけ良い選択であるかを評価するアドバンテージ関数 \(A(s,a)\) を計算する。
Generalized Advantage Estimation (GAE)の概要とアルゴリズム及び実装例
Generalized Advantage Estimation (GAE)の概要とアルゴリズム及び実装例。Generalized Advantage Estimation (GAE)は、強化学習におけるポリシーの最適化に使われる手法の一つで、特に、アクター・クリティック(Actor-Critic)アプローチのように、状態価値関数やアクション価値関数を利用するアルゴリズムにおいて、より安定した学習を可能にしたものとなる。GAEは、バイアスと分散のトレードオフを調整し、より効率的なポリシーアップデートを実現している。
Actor-Criticの概要とアルゴリズム及び実装例について
Actor-Criticの概要とアルゴリズム及び実装例について。Actor-Criticは、強化学習のアプローチの一つで、方策(ポリシー)と価値関数(価値推定子)を組み合わせた方法であり、Actor-Criticは、方策ベース法と価値ベース法の長所を結合し、効率的な学習と制御を実現することを目指すものとなる。
Trust Region Policy Optimization (TRPO)の概要とアルゴリズム及び実装例について
Trust Region Policy Optimization (TRPO)の概要とアルゴリズム及び実装例について。Trust Region Policy Optimization(TRPO)は、強化学習のアルゴリズムで、ポリシー勾配法(Policy Gradient)の一種となる。TRPOは、ポリシーの最適化を信頼領域制約の下で行うことで、ポリシーの安定性と収束性を向上させる。
TRPO-CMAの概要とアルゴリズム及び実装例
TRPO-CMAの概要とアルゴリズム及び実装例。TRPO-CMA (Trust Region Policy Optimization with Covariance Matrix Adaptation) は、強化学習におけるポリシー最適化手法の一つで、”Trust Region Policy Optimization (TRPO)の概要とアルゴリズム及び実装例について“で述べているTRPOと”CMA-ES(Covariance Matrix Adaptation Evolution Strategy)の概要とアルゴリズム及び実装例について“で述べている CMA-ESを組み合わせたものとなる。このアルゴリズムは、深層強化学習における複雑な問題を効率的に解決するために設計されている。
CMA-ES(Covariance Matrix Adaptation Evolution Strategy)の概要とアルゴリズム及び実装例について
CMA-ES(Covariance Matrix Adaptation Evolution Strategy)の概要とアルゴリズム及び実装例について。CMA-ES (Covariance Matrix Adaptation Evolution Strategy) は、進化的アルゴリズムの一種で、連続空間における困難な最適化問題を解くための最適化手法であり、特に、非線形・非凸な関数の最適化に優れた性能を発揮するものとなる。
Proximal Policy Optimization (PPO)の概要とアルゴリズム及び実装例について
Proximal Policy Optimization (PPO)の概要とアルゴリズム及び実装例について。Proximal Policy Optimization(PPO)は、強化学習のアルゴリズムの一種であり、ポリシー最適化法の一つであり、ポリシー勾配法をベースにして、安定性の向上と高い性能を目指して設計された手法となる。
A2C(Advantage Actor-Critic)の概要とアルゴリズム及び実装例について
A2C(Advantage Actor-Critic)の概要とアルゴリズム及び実装例について。A2C(Advantage Actor-Critic)は、強化学習のアルゴリズムの一つで、方策勾配法の一種であり、方策(Actor)と価値関数(Critic)を同時に学習することで、学習の効率と安定性を向上させることを目的とした手法となる。
A3C (Asynchronous Advantage Actor-Critic)の概要とアルゴリズム及び実装例について
A3C (Asynchronous Advantage Actor-Critic)の概要とアルゴリズム及び実装例について。A3C(Asynchronous Advantage Actor-Critic)は、深層強化学習のアルゴリズムの一種で、非同期の学習を用いて強化学習エージェントを訓練する手法であり、A3Cは、特に連続した行動空間でのタスクに適しており、大規模な計算リソースを有効活用できる点で注目されているものとなる。
Deep Deterministic Policy Gradient (DDPG)の概要とアルゴリズム及び実装例について
Deep Deterministic Policy Gradient (DDPG)の概要とアルゴリズム及び実装例について。Deep Deterministic Policy Gradient (DDPG) は、連続状態空間と連続行動空間を持つ強化学習タスクにおいて、ポリシー勾配法(Policy Gradient)を拡張したアルゴリズムとなる。DDPGは、Q-学習(Q-Learning)とディープニューラルネットワークを組み合わせて、連続アクション空間での強化学習問題を解決することを目的としている。
TD3 (Twin Delayed Deep Deterministic Policy Gradient)の概要とアルゴリズム及び実装例
TD3 (Twin Delayed Deep Deterministic Policy Gradient)の概要とアルゴリズム及び実装例。TD3(Twin Delayed Deep Deterministic Policy Gradient)は、強化学習における連続的な行動空間での”A2C(Advantage Actor-Critic)の概要とアルゴリズム及び実装例について“でも述べているアクター・クリティック法(Actor-Critic method)の一種となる。TD3は、”Deep Deterministic Policy Gradient (DDPG)の概要とアルゴリズム及び実装例について“で述べているDeep Deterministic Policy Gradient(DDPG)アルゴリズムを拡張したものであり、より安定した学習と性能向上を目指したものとなる。
Soft Actor-Critic (SAC) の概要とアルゴリズム及び実装例
Soft Actor-Critic (SAC) の概要とアルゴリズム及び実装例。Soft Actor-Critic(SAC)は、強化学習(Reinforcement Learning)のアルゴリズムの一種で、主に連続行動空間を持つ問題に対して効果的なアプローチとして知られているものとなる。SACは、深層強化学習(Deep Reinforcement Learning)の一部として、Q-learningおよびPolicy Gradientsなどの他のアルゴリズムと比較していくつかの利点を持っている。
ACKTRの概要とアルゴリズム及び実装例について
ACKTRの概要とアルゴリズム及び実装例について。ACKTR(Actor-Critic using Kronecker-factored Trust Region)は、強化学習のアルゴリズムの一つであり、”Trust Region Policy Optimization (TRPO)の概要とアルゴリズム及び実装例について“で述べているトラストリージョン法(Trust Region Policy Optimization, TRPO)のアイディアをもとに、ポリシーグラディエント法(Policy Gradient Methods)と価値関数の学習を組み合わせた手法で、特に連続行動空間での制御問題に適したものとなる。
深層強化学習(Deep Reinforcement Learning, DRL)
深層強化学習(DRL)によるマルチエージェントシステムの概要と実装例
深層強化学習(DRL)によるマルチエージェントシステムの概要と実装例。深層強化学習(DRL)によるマルチエージェントシステムの実装にはいくつかの方法がある。以下に一般的な手法について述べる。
Deep Q-Network (DQN)の概要とアルゴリズムおよび実装例について
Deep Q-Network (DQN)の概要とアルゴリズムおよび実装例について。Deep Q-Network(DQN)は、ディープラーニングとQ-Learningを組み合わせた手法で、Q関数をニューラルネットワークで近似することによって、高次元の状態空間を持つ問題に対処する強化学習アルゴリズムとなる。DQNは、Vanilla Q-Learningよりも大規模で高次元な問題に対して効果的で、また、リプレイバッファや固定ターゲットネットワークなどのテクニックを使用して学習の安定性を向上させている。
Dueling DQNの概要とアルゴリズム及び実装例について
Dueling DQNの概要とアルゴリズム及び実装例について。Dueling DQN(Dueling Deep Q-Network)は、強化学習においてQ学習をベースとしたアルゴリズムであり、価値ベースの強化学習アルゴリズムの一種となる。Dueling DQNは、特に状態価値関数とアドバンテージ関数を分離して学習し、Q値を効率的に推定するためのアーキテクチャであり、このアーキテクチャは、Deep Q-Network(DQN)の発展的なバージョンとして提案されたものとなる。
Rainbowの概要とアルゴリズム及び実装例について
Rainbowの概要とアルゴリズム及び実装例について。Rainbow(”Rainbow: Combining Improvements in Deep Reinforcement Learning”)は、深層強化学習の分野で重要な成果を収めた論文で、複数の強化学習の改良技術を組み合わせて、DQN(Deep Q-Network)エージェントの性能を向上させたアルゴリズムとなる。Rainbowは、多くの強化学習タスクで他のアルゴリズムよりも優れた性能を示し、その後の研究においても基準となるアルゴリズムの一つとなっている。
Prioritized Experience Replayの概要とアルゴリズム及び実装例について
Prioritized Experience Replayの概要とアルゴリズム及び実装例について。Prioritized Experience Replay(PER)は、強化学習の一種であるDeep Q-Networks(DQN)を改善するためのテクニックの一つとなる。DQNは、エージェントが環境とやり取りする際に収集した経験(経験リプレイバッファと呼ばれるもの)を再利用することによって学習し、通常、経験リプレイバッファからランダムにサンプリングすることが一般的だが、PERはこれを改善し、重要な経験を優先的に学習する方法になる。
C51 (Categorical DQN)の概要とアルゴリズム及び実装例について
C51 (Categorical DQN)の概要とアルゴリズム及び実装例について。C51、またはCategorical DQN、は深層強化学習のアルゴリズムであり、価値関数を連続的な確率分布としてモデル化する手法となる。C51は、通常のDQN(Deep Q-Network)の拡張で、離散的な行動空間の価値関数を連続的な確率分布で表現することにより、不確かさを扱う能力を持っている。
Soft Actor-Critic (SAC) の概要とアルゴリズム及び実装例
Soft Actor-Critic (SAC) の概要とアルゴリズム及び実装例。Soft Actor-Critic(SAC)は、強化学習(Reinforcement Learning)のアルゴリズムの一種で、主に連続行動空間を持つ問題に対して効果的なアプローチとして知られているものとなる。SACは、深層強化学習(Deep Reinforcement Learning)の一部として、Q-learningおよびPolicy Gradientsなどの他のアルゴリズムと比較していくつかの利点を持っている。
A3C (Asynchronous Advantage Actor-Critic)の概要とアルゴリズム及び実装例について
A3C (Asynchronous Advantage Actor-Critic)の概要とアルゴリズム及び実装例について。A3C(Asynchronous Advantage Actor-Critic)は、深層強化学習のアルゴリズムの一種で、非同期の学習を用いて強化学習エージェントを訓練する手法であり、A3Cは、特に連続した行動空間でのタスクに適しており、大規模な計算リソースを有効活用できる点で注目されているものとなる。
Deep Deterministic Policy Gradient (DDPG)の概要とアルゴリズム及び実装例について
Deep Deterministic Policy Gradient (DDPG)の概要とアルゴリズム及び実装例について。Deep Deterministic Policy Gradient (DDPG) は、連続状態空間と連続行動空間を持つ強化学習タスクにおいて、ポリシー勾配法(Policy Gradient)を拡張したアルゴリズムとなる。DDPGは、Q-学習(Q-Learning)とディープニューラルネットワークを組み合わせて、連続アクション空間での強化学習問題を解決することを目的としている。
TRPO-CMAの概要とアルゴリズム及び実装例
TRPO-CMAの概要とアルゴリズム及び実装例。TRPO-CMA (Trust Region Policy Optimization with Covariance Matrix Adaptation) は、強化学習におけるポリシー最適化手法の一つで、”Trust Region Policy Optimization (TRPO)の概要とアルゴリズム及び実装例について“で述べているTRPOと”CMA-ES(Covariance Matrix Adaptation Evolution Strategy)の概要とアルゴリズム及び実装例について“で述べている CMA-ESを組み合わせたものとなる。このアルゴリズムは、深層強化学習における複雑な問題を効率的に解決するために設計されている。
逆強化学習(Inverse Reinforcement Learning, IRL)
逆強化学習の概要とアルゴリズム及び実装例について
逆強化学習の概要とアルゴリズム及び実装例について。逆強化学習(Inverse Reinforcement Learning, IRL)は、強化学習の一種で、エキスパートの行動データからエキスパートの意思決定の背後にある報酬関数を学習するタスクとなる。通常、強化学習では報酬関数が与えられ、エージェントはその報酬関数を最大化する政策を学習し、逆強化学習は逆のアプローチで、エージェントはエキスパートの行動データを分析し、エキスパートの意思決定に対応する報酬関数を学習することを目的としている。
特徴量逆強化学習(Feature-based Inverse Reinforcement Learning)の概要とアルゴリズム及び実装例について
特徴量逆強化学習(Feature-based Inverse Reinforcement Learning)の概要とアルゴリズム及び実装例について。特徴量逆強化学習(Feature-based Inverse Reinforcement Learning)は、強化学習の一種であり、エキスパートの行動から環境の報酬関数を推定する手法となる。通常の逆強化学習(Inverse Reinforcement Learning, IRL)は、エキスパートの軌跡を直接学習し、それに基づいて報酬関数を推定している一方、特徴量逆強化学習は、特徴量を使用して報酬関数を推定することに焦点を当るものとなっている。
ドリフト検出ベースの逆強化学習(Drift-based Inverse Reinforcement Learning)の概要とアルゴリズム及び実装例について
ドリフト検出ベースの逆強化学習(Drift-based Inverse Reinforcement Learning)の概要とアルゴリズム及び実装例について。ドリフト検出ベースの逆強化学習(Drift-based Inverse Reinforcement Learning)は、エキスパートの行動とエージェントの行動の差異を検出して、その差異を最小化する報酬関数を推定する手法となる。通常の逆強化学習(IRL)では、エキスパートの行動を直接学習し、それに基づいて報酬関数を推定し、エキスパートの行動とエージェントの行動が異なる場合、報酬関数を正確に推定することが困難になるのに対して、ドリフト検出ベースの逆強化学習では、エキスパートとエージェントの行動の差異(ドリフト)を検出し、そのドリフトを最小化するような報酬関数を推定するものとなる。
最大エントロピー逆強化学習(Maximum Entropy Inverse Reinforcement Learning, MaxEnt IRL)の概要とアルゴリズム及び実装例について
最大エントロピー逆強化学習(Maximum Entropy Inverse Reinforcement Learning, MaxEnt IRL)の概要とアルゴリズム及び実装例について。最大エントロピー逆強化学習(Maximum Entropy Inverse Reinforcement Learning, MaxEnt IRL)は、エキスパートの行動データからエージェントの報酬関数を推定するための手法の一つとなる。通常、逆強化学習は、エキスパートがどのように行動するかを観察して、その行動を説明できる報酬関数を見つけることを目的としている。MaxEnt IRLは、報酬関数の推定において最大エントロピー原理を組み込むことで、より柔軟で一般的なアプローチを提供する。エントロピーは、確率分布の不確実性や予測の不確かさを表す指標であり、最大エントロピー原理は最も不確実性が高い確率分布を選ぶという考え方となる。
最適制御に基づく逆強化学習(Optimal Control-based Inverse Reinforcement Learning)の概要とアルゴリズム及び実装例について
最適制御に基づく逆強化学習(Optimal Control-based Inverse Reinforcement Learning)の概要とアルゴリズム及び実装例について。最適制御に基づく逆強化学習(Optimal Control-based Inverse Reinforcement Learning, OCIRL)は、エージェントが特定のタスクを遂行する際に、エージェントの行動データからその背後にある報酬関数を推定しようとする手法となる。このアプローチは、エージェントが最適制御理論に基づいて行動すると仮定している。
シミュレーションと最適化技術
マルコフ決定過程(MDP)と強化学習の統合したRecursive Advantage Estimationの実装例について
マルコフ決定過程(MDP)と強化学習の統合したRecursive Advantage Estimationの実装例について。Recursive Advantage Estimationは、マルコフ決定過程(MDP)と強化学習を組み合わせた新しいアプローチとなる。これは、2020年にDeepMindによって提案された方法論となる。Recursive Advantage Estimationは、通常の強化学習とは異なり、再帰的な構造を持つ方策と価値関数を使用している。このアプローチの主なアイデアは、MDPの状態遷移と報酬の両方に再帰性を持つこととなる。通常のMDPでは、次の状態と報酬は前の状態と行動にのみ依存する。しかし、Recursive Advantage Estimationでは、再帰的な方策と価値関数を導入することで、過去の情報をより効果的に利用する。
ベイジアンネットワークを用いた推論と行動の統合によるアルゴリズムと実装例について
ベイジアンネットワークを用いた推論と行動の統合によるアルゴリズムと実装例について。ベイジアンネットワークを用いた推論と行動の統合は、確率的なモデルを利用してエージェントが環境とやり取りしながら最適な行動を選択する手法であり、ベイジアンネットワークは、事象間の依存関係を表現し、不確実性を扱うのに有用なアプローチとなる。ここでは、ベイジアンネットワークを用いた推論と行動の統合によるアルゴリズムの一例として、POMDP(部分観測マルコフ決定過程)について述べる。
シミュレーションと機械学習の組み合わせと各種実装例
シミュレーションと機械学習の組み合わせと各種実装例。シミュレーションは、現実世界のシステムやプロセスをモデル化し、それをコンピュータ上で仮想的に実行するものとなる。シミュレーションは、物理的な現象、経済モデル、交通フロー、気候パターンなど、さまざまな領域で使用され、モデルの定義、初期条件の設定、パラメータの変更、実行、結果の解析などのステップで構築することができる。シミュレーションと機械学習は、異なるアプローチとなるが、目的や役割によって様々な相互作用をすることがある。
ここではこのシミュレーションと機械学習の組み合わせの適応事例と各種実装について述べている。
カーリー・ウィンドウ探索(Curiosity-Driven Exploration)の概要とアルゴリズム及び実装例について
カーリー・ウィンドウ探索(Curiosity-Driven Exploration)の概要とアルゴリズム及び実装例について。カーリー・ウィンドウ探索(Curiosity-Driven Exploration)は、強化学習においてエージェントが興味深い状態や事象を自発的に見つけ、学習の効率を向上させるための一般的なアイディアや手法の総称となる。このアプローチは、単純な報酬信号だけでなく、エージェント自体が自己生成的に情報を生成し、それに基づいて学習することを目的としている。
価値勾配法の概要とアルゴリズム及び実装例について
価値勾配法の概要とアルゴリズム及び実装例について。価値勾配法(Value Gradients)は、強化学習や最適化の文脈で使用される手法の一つであり、状態価値やアクション価値といった価値関数に基づいて勾配を計算し、その勾配を使って方策の最適化を行うものとなる。
転移学習の概要とアルゴリズムおよび実装例について
転移学習の概要とアルゴリズムおよび実装例について。転移学習(Transfer Learning)は、機械学習の一種であり、あるタスクで学習したモデルや知識を、異なるタスクに適用する技術であり、通常、新しいタスクに必要なデータが少ない場合や、高い性能を要求するタスクにおいて、転移学習が有用となる。ここでは、この転移学習の概要及び様々なアルゴリズムと実装例について述べている。
機械学習におけるアクティブラーニング技術について
機械学習におけるアクティブラーニング技術について。機械学習におけるアクティブラーニング(Active Learning)は、モデルの性能を向上させるために、ラベル付けされたデータを効果的に選択するための戦略的なアプローチとなる。通常、機械学習モデルのトレーニングには大量のラベル付けされたデータが必要だが、ラベル付けはコストが高く、時間がかかるため、アクティブラーニングはデータ収集の効率を高めるものとなっている。
環境と実装
pytorchの概要と環境設定及び実装例
pytorchの概要と環境設定及び実装例。PyTorchは、Facebookが開発しオープンソースで提供されている深層学習のライブラリであり、柔軟性、動的計算グラフ、GPU加速などの特徴を持ち、様々な機械学習タスクを実装を可能としてくれるものとなる。以下に、PyTorchを用いたさまざまな実装例について述べる。
理論と応用
概要
強化学習は何故必要なのか?適用事例と技術課題及び解決のアプローチ
強化学習は何故必要なのか?適用事例と技術課題及び解決のアプローチ。chatGPTで有名なOpenAIのもう一つの側面として強化学習がある。chatGPTのベースとなっているGPTの肝は”深層学習におけるattentionについて“で述べたattentionをベースとした”Transformerモデルの概要とアルゴリズム及び実装例について“でも述べているtransformerと、強化学習による深層学習モデルの改善にあると言われている。深層学習と聞くと、AlphaGoに代表されるゲームへの適用か、車の自動運転への適用がすぐイメージされるが、今回は強化学習に対してもう少し深掘りした検討を行う。
教育とAIについて
教育とAIについて。AI(人工知能)は教育分野において大きな影響力を持ち、教育方法や学習プロセスを変革する潜在能力を秘めている。以下に、AIと教育に関するいくつかの重要な側面について述べる。
機械学習スタートアップシリーズ「Pythonで学ぶ強化学習」
機械学習スタートアップシリーズ「Pythonで学ぶ強化学習」。
強化学習の概要とシンプルなMDPモデルの実装
強化学習の概要とシンプルなMDPモデルの実装。強化学習の概要とシンプルなMDPモデルのpythonでの実装について述べる。
モデルベースアプローチ
モデルベースアプローチによる強化学習の概要とpythonでの実装
モデルベースアプローチによる強化学習の概要とpythonでの実装。前回述べた迷路の環境をベースに計画を立てる手法について述べる。計画を立てるには「価値評価」と「戦略」の学習が必要となる。そのためにはまず「価値」を実体に即した形で定義し直す必要がある。
ここでは動的計画法(Dynamic Programming)を用いたアプローチについて述べる。この手法は迷路の環境のような遷移関数と報酬関数が明らかな場合に利用でき。このように遷移関数・報酬関数をベースに学習する手法を「モデルベース」の学習法と呼ぶ。ここでの「モデル」とは環境のことで、環境の動作を決定する遷移関数・報酬関数がその実態となる。
モデルフリーアプローチ
epsilon-Greedy法
モデルフリー強化学習のpythonによる実装(1) epsilon-Greedy法。今回はモデルフリーの手法について述べる。モデルフリーは、エージェントが自ら動くことで経験を蓄積し、その経験から学習を行う手法となる。前述までのモデルベースのものと異なり環境の情報、つまり遷移関数と報酬関数は分かっていないことが前提となる。
行動した「経験」を活用するにあたり、検討すべきポイントは3つある。(1)経験の蓄積とバランス、(2)計画の修正を実績から行うか、予測で行うか、(3)経験を価値評価、戦略のどちらの更新に利用するか
モンテカルロ法とTD法
モデルフリー強化学習のpythonによる実装(2) モンテカルロ法とTD法。今回は行動の修正を実績に基づき行う場合と、予測により行う場合のトレードオフについて述べる。前者の手法としてモンテカルロ法(Monte Carlo Method)、後者の手法としてTD法(Temporal Difference Learning)について述べる。またこの間を取る手法としてMulti-step Learning法とTD(λ)法(ティーディーラムダ法)についても述べる。
経験を価値評価、戦略どちらの更新に利用するか:ValueベースvsPolicyベース
モデルフリー強化学習のpythonによる実装(3)経験を価値評価、戦略どちらの更新に利用するか:ValueベースvsPolicyベース。今回は、経験を「価値評価」の更新に使うか、「戦略」の更新に使うかという違いについて述べる。これはValueベースか、Policyベースかの違いと同じとなる。いずれも経験(=TD誤差)から学習する点に変わりはないが、その適用先がことなる。2つの違いを見ていくとともに、両方を更新する二刀流ともいえる手法についても述べる。
ValueベースとPolicyベースの大きな違いは、行動選択の基準となる。valueベースは価値が最大となる状態に遷移するように行動を決定し、Policyベースは戦略に基づいて行動を決定する。戦略を使用しない前者の基準をOff-policyと呼ぶ(戦略がない=Off)。これに対し、戦略を前提とする校舎をOn-policyと呼ぶ。
Q-Learningを例に取る。Q-Learningの更新対象は「価値評価」であり、行動選択の基準はOff-policyとなる。これはQ-Learningで「価値が最大になるような行動aをとる」(max(self.G[n-state]))ように実装したことからも明らかとなる。これに対して、更新対象が「戦略」で基準が「On-policy」である手法が存在する。それがSARSA(State-Action-Reward-State-Action)となる。
強化学習に対する深層学習の適用
概要
強化学習に対するニューラルネットワークの適用(1)概要。今回は、価値関数や戦略をパラメーターを持った関数で実装する方法について述べる。これによりテーブル管理では扱いづらい、連続的な状態や行動にも対応できるようになる。
基本的なフレームワークの実装
強化学習に対するニューラルネットワークの適用(2)基本的なフレームワークの実装。今回は強化学習への深層学習の適用のフレームワークでのpyhtonによる実装について述べる。
価値評価をパラメータを持った関数で実装するValue Function Approximation
強化学習に対するニューラルネットワークの適用 価値評価をパラメータを持った関数で実装するValue Function Approximation。今回はモデルフリー強化学習のpythonによる実装(1) epsilon-Greedy法等で述べたテーブル(Q[s][a]、Q-table)で行っていた価値評価をパラメータを持った関数に置き換える手法について述べる。価値評価を行う関数は価値関数(Value function)と呼ばれ、価値関数を学習(推定)することをValue Function Approximation(あるいは単にFunction Approximation)と呼ぶ。価値関数を利用した手法では、行動選択を価値関数の出力に基づいて行う。つまり、Valueベースの手法となる。
今回は、価値関数により行動を決定すエージェントを作成し、CartPoleの環境を攻略する。CartPoleは、棒が倒れないようにカートの位置を調整する環境となる。OpenAI Gymの中でもポプュラーな環境で、さまざまなサンプルで使用されている。価値関数には、ニューラルネットワークを用いる。
価値評価に深層学習を適用するDeep Q-Network
強化学習に対するニューラルネットワークの適用 価値評価に深層学習を適用するDeep Q-Network。今回はCNNを使ったゲームの攻略について述べる。基本的な仕組みは前述とほとんど変わらないが、「画面を直接入力できるメリットを体感するために環境を変更する。今回は具体的な題材としてはボルキャッチを行うゲームであるCatcherについて述べる。
今回実装したDeep-Q-Networkには、現在多くの改良が行われている。Deep-Q-Networkを発表したDeep Mindは、優秀な改良法6つを組み込んだRainbowというモデルを発表している(Deep-Q-Networkを足すと全部で7つで、7色のRainbowになる)。
戦略をパラメータを持った関数で実装するPolicy Gradient
強化学習に対するニューラルネットワークの適用 戦略をパラメータを持った関数で実装するPolicy Gradient。戦略もパラメータを持った関数で表現できる。状態を引数に取り、行動、または行動確率を出力する関数となる。ただ、戦略のパラメータ更新は容易ではない。価値評価では見積もりと実際の価値を近づけるというわかりやすいゴールがあった。しかし、戦略から出力される行動や行動確率は、計算できる価値と直接比較することができない。この場合の学習のヒントとなるのが、価値の期待値となる。
戦略に深層学習を適用する:Advanced Actor Critic(A2C)
強化学習に対するニューラルネットワークの適用 戦略に深層学習を適用する:Advanced Actor Critic(A2C)。価値関数にDNNを適用したように、戦略の関数にもDNNを適用することができる。具体的には、ゲーム画面を入力として行動・行動確率を出力する関数となる。
Policy Gradientにはいくつかバリエーションがあったが、ここではAdvantageを使ったActor Critic(A2C)と呼ばれる手法について述べる。なお「A2C」という名前自体には”Advantage Actor Critic”という意味しかないが、一般的に「A2C」と呼ばれる手法には分散環境で並列に経験を収集する手法も含む。ここでは純粋に「A2C」の部分のみを実装し、分散収集については解説程度にとどめる。
なお、A2Cに分散収集の手法が含まれているのはA2Cの前にA3C(Asynchronous Advantage Actor Critic)」という手法が発表されていたからという事情がある。A3CしA2Cと同様に分差ん環境を使用しているが、エージェントは各環境で経験を収集するだけでなく、学習も行う。これが(各環境下での)”Asynchronous”な学習となる。しかし、Asynchronousな学習をしなくても十分な精度、あるいはそれ以上の精度が出る、つまり”A”は3つでなく2つで十分、とされたのがA”2″Cの生まれた背景となる。そのため、Asynchronousな学習ではないが分散環境における経験の収集は残っている。
強化学習のPolicy Gradient手法の改善であるTRPO/PPOとDPG/DDPG
強化学習のPolicy Gradient手法の改善であるTRPO/PPOとDPG/DDPG。”強化学習に対するニューラルネットワークの適用 戦略に深層学習を適用する:Advanced Actor Critic(A2C)”にて「Policy Gradient系の手法は実行結果が安定しないことがある」と述べたが、これを改善する手法が提案されている。まず、更新前の戦略からあまり離れないように、つまり徐々に変化するように制約をかける手法で、式で書くと以下のようになる。TRPO/PPOも、前述のA2C/A3Cと並び、現在標準的に用いられているアルゴリズムとなる。
深層強化学習の弱点と対策
概要
深層強化学習における価値評価と戦略と弱点。強化学習への深層学習の適用では「価値評価」と「戦略」それぞれを関数で実装し、その関数をニューラルネットを用いて最適化した。主な手法の相関図は以下のようになる。強化学習の負の側面として以下の3つがある。(1)サンプル効率が悪い、(2)局所最適な行動に陥る、過学習することがある、(3)再現性が悪い
深層強化学習の弱点への対策の概要
深層強化学習の弱点と対策の概要と環境認識の改善の為の2つのアプローチ。今回は「サンプル効率が悪い」「局所最適な行動に陥る、過学習することが多い」「再現性が悪い」の3つの強化学習の弱点を克服する手法について述べる。特に「サンプル効率が悪い」は主要な課題となり、さまざまな対策が提案されている。それらのアプローチは様々あるが、今回は「環境認識の改善」を中心に述べる。
深層強化学習の弱点への対策の実装
深層強化学習の弱点である環境認識の改善の為の2つのアプローチの実装。”深層強化学習の弱点と対策の概要と環境認識の改善の為の2つのアプローチ”では深層強化学習の弱点である「サンプル効率が悪い」「局所最適な行動に陥る、過学習することが多い」「再現性が悪い」の3つの強化学習の弱点を克服する手法について述べ、特に主要な課題である「サンプル効率が悪い」に対する対策として「環境認識の改善」を中心に述べた。今回はそれらの実装について述べる。
深層強化学習の研究動向
メタラーニングと転移学習、内発的動機づけとカリキュラムラーニング
深層強化学習の研究動向:メタラーニングと転移学習、内発的動機づけとカリキュラムラーニング。ここでは「環境認識の改善」以外の手法について研究動向を述べる。具体的には「転移能力」としてメタラーニングと転移学習、「探索行動の改善」として内発的報酬/内発的動機づけ、「外部からの教示」としてカリキュラムラーニングについて述べる。
深層強化学習の弱点の克服
再現性の低さへの対応:進化戦略
深層強化学習の弱点の克服 再現性の低さへの対応:進化戦略。深層強化学習には「学習が安定しない」という問題があり、これが再現性の低さを招いていた。深層強化学習に限らず、深層学習では一般的に勾配法という学習方法が用いられる。この勾配法を代替する学習法として、近年進化戦略(Evolution Startegies)が注目を浴びている。進化戦略は遺伝的アルゴリズムと同時期に提案された古典的な手法でとてもシンプルな手法となる。
デスクトップPC(64bit Corei-7 8GM)では1時間足らずで上記の学習を行うことができ、通常の強化学習と比べてはるかに短い時間で、しかもGPUなしで報酬が獲得できるようになっている。進化戦略による最適化は未だ研究途上だが、将来勾配法と肩を並べる可能性がある。強化学習の再現性を高めるために、勾配法を改良するのではなく別の最適化アルゴリズムを使用する、あるいは併用する研究は今後発展の可能性がある。
局所最適な行動/過学習への対応:模倣学習
深層強化学習の弱点の克服 局所最適な行動/過学習への対応:模倣学習。今回は、局所最適な行動をしてしまう、また過学習してしまうことへの対処法について述べる。局所最適な行動と過学習は、端的には「意図しない行動」をしてしまう現象となる。これを解決するには「意図した行動」を学習させればよく、「模倣学習」と「逆強化学習」の2つの学習方法がある。今回は人が示したお手本から行動を進化させる「模倣学習」のさまざまな手法について述べる。
局所最適な行動/過学習への対応:逆強化学習
深層強化学習の弱点の克服 局所最適な行動/過学習への対応:逆強化学習。今回も前回に続き局所最適な行動をしてしまう、また過学習してしまうことへの対処法について述べる。ここでは逆強化学習について述べる。
逆強化学習(Inversed Reinforcement Learning : IRL)は、エキスパートの行動を模倣するのではなく行動の背景にある報酬関数を推定する。報酬関数を推定するメリットは3つある。1つ目は報酬を設計する必要がなくなる点で、これにより意図しない行動が発生するのを防げる。2点目は他タスクへの転移に利用できる点で、報酬関数が近い別のタスクであれば、その学習に利用できる(ジャンルが同じ別のゲームの学習に利用するなど)。3つ目は人間(や動物)の行動理解に使用できる点となる。
強化学習の活用領域
行動の最適化
強化学習の活用領域(1) 行動の最適化。ここでは強化学習が活用されている事例と、活用が見込まれる領域について述べる。強化学習の応用は、これまではゲーム領域、自動運転などが多かったが、最近では配車の最適化などに活用するなど「適用した結果どうだったか」というフィードバックが蓄積されつつあり、実社会への適用サイクルが回りつつある。
学習の最適化
強化学習の活用領域(2) – 学習の最適化。学習の最適化では、強化学習の「報酬をもとに最適化を行う」という学習プロセスを活用したものとなる。近年の深層学習モデルは勾配降下法により最適化を行うことが多いが、この場合当然「勾配」が計算できる必要がある。二乗誤差は勾配の計算が可能だが、中には計算できない指標もある。翻訳やようやく、または検索システムの評価指標は勾配の計算を行うことができないため、勾配法で直接最適化することが困難となる。
強化学習であれば、勾配が計算できなくても評価指標の値を「報酬」にしてしまえば学習できる。これが、強化学習を「学習の最適化」に使用するメリットになる。ここでは、強化学習によるモデルのパラメータの最適化と、構造の最適化について述べる。
強化学習でモデルのパラメータを最適化する事例として、要約の作成と化学物質構造の生成について述べる。
理論
機械学習プロフェッショナルシリーズ 「強化学習」 読書メモ
機械学習プロフェッショナルシリーズ 「強化学習」 読書メモ。
強化学習とは
強化学習とは。強化学習技術の概要。強化学習とは逐次的な意思決定ルールを学習する機械学習の一分野となる。意思決定ルールの最適化を目指すという点ではオペレーション・リサーチと同じだが、適用するシステムや環境に対する完全な知識を前提とせず、設計者が「なにをすべきか(Goal)」を報酬というアルゴリズムに入力して「どのように実現するのか(How)」をデータなどから学習するという特徴がある。
その為システムに関する知識が十分になくとも(大量に)データが取得できるのであれば、強化学習によって目的を達成するような意思決定ルールを得られる可能性があり、ビジネスインテリジェンスや医療、金融あるいはゲームの分野等の多岐に渡る領域での応用が検討されている。
プランニング問題
動的計画法を用いたアプローチと理論的裏付け
プランニング問題(1)-動的計画法を用いたアプローチと理論的裏付け。環境が既知の場合の逐次的意思決定であるプランニング問題について述べている。プランニング問題の特徴や解法は、環境が未知である強化学習を扱うための基礎となる。たとえば、プランニング問題の特徴を調べることで、環境が未知の場合においても、どのクラスの方策までを扱えば良いかわかる。また、プランニング方法の確立的な近似として、後述するTD法やQ学習などの強化学習の代表的な方法が導出される。ここでは期待リターンに基づく目的関数や最適価値関数、最適方策を導入し、最適方策を求める方法として動的計画法の理論的概要について述べている。
動的計画法の実装(価値反復法と方策反復法)
プランニング問題(2)-動的計画法の実装(価値反復法と方策反復法)。前回に引き続き、エージェントと環境の相互作用などによるデータからの学習を想定せず、環境(マルコフ決定過程)が既知であると仮定して、最適な方策を求めるプランニング問題の動的計画法での具体的なアプローチとして、価値反復法と方策反復法のアルゴリズムについて述べている。
探索と活用のトレードオフ
リグレットと確率的最適方策、ヒューリスティクス
探索と活用のトレードオフ -リグレットと確率的最適方策、ヒューリスティクス。実環境や環境シミュレーションなどで行動を入力し、報酬や次状態を観測することでデータを収集して、データから方策を逐次的に学習する際に問題となるデータの探索と活用のトレードオフについて述べ、トレードオフを考慮する代表的な方策モデルについて述べている。
モデルフリー型の強化学習
価値反復法(モンテカルロ法、TD法、TD(λ)法)
モデルフリー型の強化学習(1)- 価値反復法(モンテカルロ法、TD法、TD(λ)法)。前回までで、環境が既知として、完全な情報のもとでの方策の決定(プランニング問題)について述べた。今回は、環境が未知であり、環境とエージェントの相互作用などによって得られたデータから方策を学習することについて述べる。ここで述べるモデルフリー型の強化学習は環境非同定型の強化学習と呼ばれ、環境を陽に推定せずに、方策を学習するアプローチとなる。
具体的には動的計画法を基礎として、確率的近似の考え方に従って、確率的に観測されるデータからTD法、TD(λ)法、モンテカルロ法等を用いて価値反復法を行う手法について述べる。
方策反復法(Q学習法、SARSA、アクタークリック法)
モデルフリー型の強化学習(2)- 方策反復法(Q学習法、SARSA、アクタークリック法)。前回までで、履歴データからベルマン期待作用素Bπを近似して、価値関数を推定することをについて述べた。今回は主にベルマン最適作用素B*に基づく価値反復法を近似的に実行して、最適方策π*を学習することについて述べる。ただし、前述のように単純にB*を標本近似できないので、まずベルマン作用素と価値関数に行動空間を追加して、ベルマン行動作用素と行動価値関数を定義する。次にそれらを用いてベルマン行動作用素の標本近似を行い。さらにバッチ学習とオンライン学習としてQ学習法とSARSA法について述べる。
モデルベース型の強化学習
スパースサンプリング、UCT、モンテカルロ探索木
モデルベース型の強化学習 – スパースサンプリング、UCT、モンテカルロ探索木。前回は環境を推定しないモデルフリー型の強化学習について述べた。今回は、環境モデルを陽に推定し、推定した環境モデルを用いて方策を求めるモデルベース型の強化学習について述べる。これは具体的には、履歴データから環境モデルとしてマルコフ決定過程の状態遷移確率pTや報酬関数gを推定し、プランニング法(マルコフ決定過程の解法)でスパースサンプリング、UCT、モンテカルロ探索木等を用いて最適な方策を予測するものとなる。
関数近似を用いた強化学習
価値関数の関数近似(バッチ学習の場合)
関数近似を用いた強化学習(1)- 価値関数の関数近似(バッチ学習の場合)。状態数が膨大であったり、状態空間が連続の場合、これまでの状態ごとに値を持つようなテーブル形式の関数ではテーブルの要素が大きくなりすぎて学習が困難となるケースのために、価値関数や方策関数を関数近似器を用いて近似して学習することについて述べる。
まずは価値関数に対して自由度の小さいような関数近似器を用いて、それらを近似し学習するケースでバッチ学習の場合について解説する。
価値関数の関数近似(オンライン学習の場合)
関数近似を用いた強化学習(2)- 価値関数の関数近似(オンライン学習の場合)。状態数が膨大であったり、状態空間が連続の場合、これまでの状態ごとに値を持つようなテーブル形式の関数ではテーブルの要素が大きくなりすぎて学習が困難となるケースのために、価値関数や方策関数を関数近似器を用いて近似して学習することについて述べる。
まずは価値関数に対して自由度の小さいような関数近似器を用いて、それらを近似し学習するケースでオンライン学習の場合(勾配TD学習法、最小二乗法に基づく最小二乗TD学習(LSTD)法、GTD2法)について述べ、さらに関数近似の選択とLASSOを用いた正則化について述べる。
方策関数の関数近似(バッチ学習の場合)
関数近似を用いた強化学習(3)- 方策関数の関数近似(バッチ学習の場合)。アクター・クリティック法のように、行動価値関数から方策を求めるのではなく、方策パラメータθで確率的方策π0を直接規定して、θを学習することを考える。ここではまず方策学習の概要を確認し、次に勾配法に従い方策パラメータを学習する方策勾配法(policy gradient learning)の基礎について述べる。そして最後に方策勾配法の実装例について述べる。
方策パラメータθの各要素が各状態行動対(s,a)に対応する時、θはテーブル形式の効用関数と実質同等であり、関数近似なしの方策モデルを扱っていることとなる。一方、方策パラメータθの要素数dが|S||A|より小さい場合、πθで方策を近似していることになり、|S|や|A|が大きいときに有効となる。特に行動が連続の場合、行動価値関数を近似するアプローチだと行動選択や作用素argmaxa∈Aなどの計算が一般的に困難なため、方策を関数近似するアプローチがよく用いられる。
たとえば、ロボット制御においては連続値であるトルクなどが行動となり、行動を単純に離散化するよりは、連続のまま扱うことが望まれる。
方策を直接にパラメータθで規定する他の利点として、行動価値関数に基づく従来の方策では行動のランダム性をハイパーパラメータとしてユーザーが調整する必要があったのに対して、そのようなハイパーパラメータを方策パラメータθに含めることで、学習によって自動でランダム性を調整できることがある。
そのため、適度なランダム性を持つ確率的方策を求める必要がある場合、得な部分観測マルコフ決定過程(partially observable Markov decision process;POMDP)をマルコフ決定過程として近似的に扱って方策を学習する際に有効であることが示されている。
部分観測マルコフ決定過程
POMDPと信念MDPについて
部分観測マルコフ決定過程(1)POMDPと信念MDPについて。前回までに、エージェントはマルコフ性のある状態を観測できると仮定していた。しかし、実問題によってはマルコフ性の仮定は現実的ではなく、状態を状態を部分的にしか観測できず、未来の出来事がが現在の観測だけでなく過去の履歴にも依存することがある。このようなモデルを数理モデル化したものとして、部分観測マルコフ決定過程がある。
マルコフ決定過程(Markov decision process;MDP)ではエージェント(意思決定者)はマルコフ性のある状態をつねに観測できるとしていたが、部分観測マルコフ決定過程(POMDP)では状態を部分的にしか観測できず、観測状態がマルコフ性を満たすとは限らない状況を扱う過程となる。例えば、対話エージェントの学習を考える場合、観測は対話相手の発話、行動はエージェント自身の発話などになるが、多くの場合、会話の文脈(発話履歴)に依存して直前の発話の意味が異なるので、マルコフ決定過程では適切に数理モデル化できず、POMDPが利用される。
またPOMDPと対になる非マルコフの確率制御過程に対するアプローチとして、予測状態表現(predictive state representation;PSR)がある。大まかにはPOMDPでは後述の信念状態のように過去に何を経験したかという観点で状態を表現するのに対し、PSRでは未来に何か起きそうかという観点で状態を表現するという違いがある。
POMDPのプランニング
部分観測マルコフ決定過程(2)POMDPのプランニング。POMDPの環境モデルPが既知であるとして、プランニング(最適方策を求める)方法を説明する。前述したPOMDPを信念MDPの問題に帰着できることを確認したが、信念状態が連続空間にあるため、離散状態のマルコフ決定過程のプランニング方法をそのまま利用することはできない。そこで、プランニング方法を導出する上での大切な信念MDPの特徴を示し、動的計画法に基づくプランニングについて述べる。実装例としては、厳密法と計算量を抑えて近似的にプランニングを行う点近似の価値反復法について述べる。
プランニング問題として、𝑉∗𝑏の推定問題を扱う。まず、最適価値関数𝑉∗𝑏の推定の基礎となる信念MDPにおけるベルマン最適作用素と動的計画法を説明する。
最後に実装については、連続空間である信念空間Bについてのアルファベクトルの和Uの計算が必要なため、単純にに実装することはできな為、それらを解決する実装例として、厳格法と計算量を抑え効率よく近似解を求める近似法について述べる。
強化学習の発展的トピック
リスク指標を用いた強化学習
強化学習の新展開(1)-リスク指標を用いた強化学習。強化学習の応用が広がる一方で、一般的な強化学習法の適用が困難な事例も多く指摘されている。その要因の一つとして、多くの強化学習法はリターンの「期待値」の最大化を目的としていることが挙げられている。実際に、期待リターンの最大化問題もしくは期待コストの最小化問題として定式化できない事例が多く報告されている。
例えば、起こる確率は小さいが、大きな損失が発生してしまうような可能性があり、ユーザーがそのリスクをなるべく回避することに興味があるような場合、期待リターンはその目的を正しく反映する指標とは言えなくなる。なぜなら、期待リターンの最大化は全体として発生するコストを軽減するが、高いコストの発生するリスクを積極的に回避することを目指していないからとなる。
特に金融工学において、リスク回避は主要なテーマであり、たとえば株式投資の場合には、小さな確率で起こる大きな損失を回避しながら収益を高めるようなポートフォリオを組むことが必要となる。
深層学習を用いたアプローチ
強化学習の新展開(2)-深層学習を用いたアプローチ。深層モデルを利用する強化学習は深層強化学習(deep reinforcement learning)と呼ばれる。近年テレビゲームや囲碁で人を超える性能を発揮し、多くの注目を浴びている。今回は深層強化学習のトピックについて述べる。
深層強化学習を改善するには7つの手法(初代のDQN,二重Q学習(二重DQN法),優先度付け経験再生,衝突Qネットワーク,分布強化学習(カテゴリDQN法)ノイズネットワーク,nステップ切断リターン)がある。
また囲碁をはじめ将棋やチェスなどの完全情報ゲームで、ルールのみを与えて、事故対戦から学習することで、人を超える方策を獲得することに成功した強化学習法であるアルファゼロについても述べる。
TD法
TD法とは(外部リンク)
TD法とは(外部リンク)。TD学習(Temporal Difference learning)とは強化学習の手法の一つで、価値ベースの手法です。以下(1)式で表される様にTD誤差が0になる様な行動価値関数を用いてQ値を決定します。 こちらで強化学習について説明しましたが、ここでは強化学習の実装例の理解として、単純なスキナー箱を例にTD学習を用い説明します。
マルチタスク学習
マルチタスク学習の概要と適用事例と実装例
マルチタスク学習の概要と適用事例と実装例。マルチタスク学習(Multi-Task Learning)は、複数の関連するタスクを同時に学習する機械学習の手法となる。通常、個々のタスクは異なるデータセットや目的関数を持っているが、マルチタスク学習ではこれらのタスクを同時にモデルに組み込むことで、相互の関連性や共有できる情報を利用して互いに補完しあうことを目指している。
ここではこのマルチタスクに対して、共有パラメータモデル、モデルの蒸留、転移学習、多目的最適化等の手法の概要について述べ、自然言語処理、画像認識、音声認識、医療診断等の応用事例とpythonによる簡易な実装例について述べている。

コメント
[…] と組み合わせたアプローチも多く検討されており、例えば”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“で述べている強化学習と組み合わせた深層強化学習、” […]
[…] 推論技術 セマンティックウェブ技術 深層学習技術 オンライン学習 強化学習技術 チャットボットと質疑応答技術 ユーザーインターフェース技術 […]
[…] “バンディット問題の理論とアルゴリズム“で述べたバンディット問題や”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“で述べている強化学習では、最適な解を得るために、よりよい方策を探す「探索」と、選んだ方策で最適解を見つける「知識活用」のバランスが重要であり、どちらかに偏っても局所解に陥り、大域的な解を得ることができないことが述べられている。上述したさまざまな宗教における思想や実践は人が幸せに生きるための方策として捉えることができる。それぞれについて学び理解することはより良い生き方をするためのヒントになるものと考えられる。 […]
[…] い場合に有効な手法として、近年注目されている。深層強化学習の詳細に関しては”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“にて述べているので参照のこと。 […]
[…] 自然言語処理技術 推論技術 セマンティックウェブ技術 深層学習技術 強化学習技術 オンライン学習 チャットボットと質疑応答技術 […]
[…] 推論技術 セマンティックウェブ技術 深層学習技術 オンライン学習 強化学習技術 チャットボットと質疑応答技術 ユーザーインターフェース技術 […]
[…] 知識情報処理技術 オンライン学習技術 強化学習技術 確率的生成モデル技術 自然言語処理技術 […]
[…] 機械学習における数学 深層学習 オントロジー技術 知識情報処理 強化学習 説明できる機械学習 […]
[…] 確率的生成モデル 機械学習技術 深層学習技術 センサーデータ/IOT技術 強化学習 […]
[…] 技術の選択の基準としては、深層学習、強化学習、確率的生成モデル、自然言語処理、説明できる機械学習、知識情報処理などの本ブログに記載しているものは、それぞれのリンク先の記事を参考にすることとし、それら以外の技術のピックアップを意識して行っている。 […]
[…] 強化学習の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“に記載している。そちらも参照のこと。 […]
[…] 強化学習の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“に記載している。そちらも参照のこと。 […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] 強化学習の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“に記載している。そちらも参照のこと。 […]
[…] “深層学習について“でも述べている深層学習技術を活用した新たな探索アルゴリズムが開発されている。例えば、”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“でも述べている深層強化学習(Deep Reinforcement Learning, DRL)は、”Q-学習の概要とアルゴリズム及び実装例について“で述べているQ-学習や”方策勾配法の概要とアルゴリズム及び実装例について“で述べている方策勾配法などのアルゴリズムを深層ニューラルネットワークと組み合わせ、ゲームプレイやロボット制御などの問題に対処したものとなる。 […]
[…] 強化学習の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“に記載している。そちらも参照のこと。 […]
[…] 様々な強化学習技術の理論とアルゴリズムとpythonによる実装 | Deus Ex Machina より: 2023年5月30日 1:59 PM […]
[…] 強化学習の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“に記載している。そちらも参照のこと。 […]
[…] 推論技術 セマンティックウェブ技術 深層学習技術 オンライン学習 強化学習技術 チャットボットと質疑応答技術 ユーザーインターフェース技術 […]
[…] 推論技術 セマンティックウェブ技術 深層学習技術 オンライン学習 強化学習技術 チャットボットと質疑応答技術 ユーザーインターフェース技術 […]
[…] ためのプラットフォームとして広く使用されている。特に”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“で述べているように強化学習(Reinforcement Learning)では、AI […]
[…] 画像認識 自然言語処理 音声認識 スパースモデリング 強化学習 深層学習 Python 物理・数学 […]
[…] 強化学習の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“に記載している。そちらも参照のこと。 […]
[…] 様々な強化学習技術の理論とアルゴリズムとpythonによる実装 | Deus Ex Machina より: 2023年8月10日 4:13 AM […]
[…] 強化学習の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“に記載している。そちらも参照のこと。 […]
[…] 強化学習の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“に記載している。そちらも参照のこと。 […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] こでは、CartPole環境を使用し、Q学習(Q-Learning)アルゴリズムを実装している。強化学習技術の詳細は”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“を参照のこと。 […]
[…] 今回は海外の著名な学会から抽出した注目される技術とその代表的な論文について述べている。技術の選択の基準としては、深層学習、強化学習、確率的生成モデル、自然言語処理、説明できる機械学習、知識情報処理などの本ブログに記載しているものは、それぞれのリンク先の記事を参考にすることとし、それら以外の技術のピックアップを意識して行っている。 […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] センサーデータ/IOT技術 オンライン学習 深層学習技術 確率生成モデル 強化学習技術 python 経済とビジネス […]
[…] オンライン学習技術 深層学習技術 確率生成モデル 強化学習技術 […]
[…] 推論技術 セマンティックウェブ技術 深層学習技術 オンライン学習 強化学習技術 チャットボットと質疑応答技術 ユーザーインターフェース技術 […]
[…] 推論技術 セマンティックウェブ技術 深層学習技術 オンライン学習 強化学習技術 チャットボットと質疑応答技術 ユーザーインターフェース技術 […]
[…] 推論技術 セマンティックウェブ技術 深層学習技術 オンライン学習 強化学習技術 チャットボットと質疑応答技術 ユーザーインターフェース技術 […]